第一次作业
1、UML类图
2、程序复杂度:
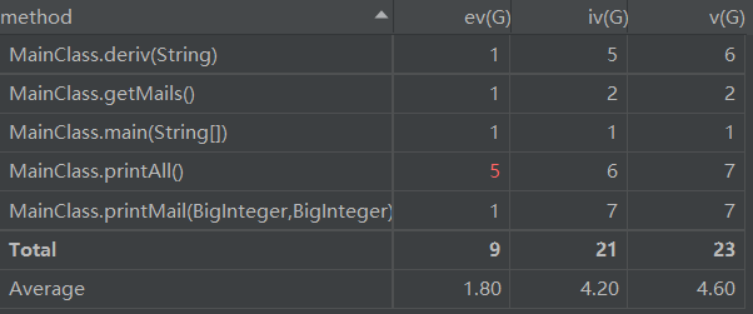
算法复杂度主要集中在化简打印输出部分,输出打印的两个函数Cyclomatic Complexity都较高,主要原因是输出时为减小长度,设计了很多返回路径。事实证明,自己在测试代码时此部分确实是bug最集中的区域,以后在此类情境中应多加考虑。
3、bug分析
此处列举自身测试时的bug和测试出别人的bug。
(1)使用long而非BigInteger,在数字过大时产生异常。
(2)在系数为0,1,-1指数为0,1等情况时输出错误。这些部分也就是我的代码中v(G)较高的区域。多路径返回时容易漏分析情况。测试时应加强边界情况测试,在能做到的情况下可穷举边界情况,以防止bug产生。
4、发现别人bug的方法
本次代码比较简单,我去阅读别人代码,分析可能出错的地方,不过好像大家都没多少bug,但阅读过程中自己也学习不少技巧。
5、反思
第一次作业我只分了一个类,完全是面向过程的写法。但由于第一次作业较为简单,这种写法是很方便的。虽然不利于后序扩展,但整体代码长度才一百多行,使用尽可能简单的方法可减少bug产生,重构起来也不复杂。但随着后序作业复杂度的上升,这样的写法就不适宜了。
第二次作业
1、UML类图
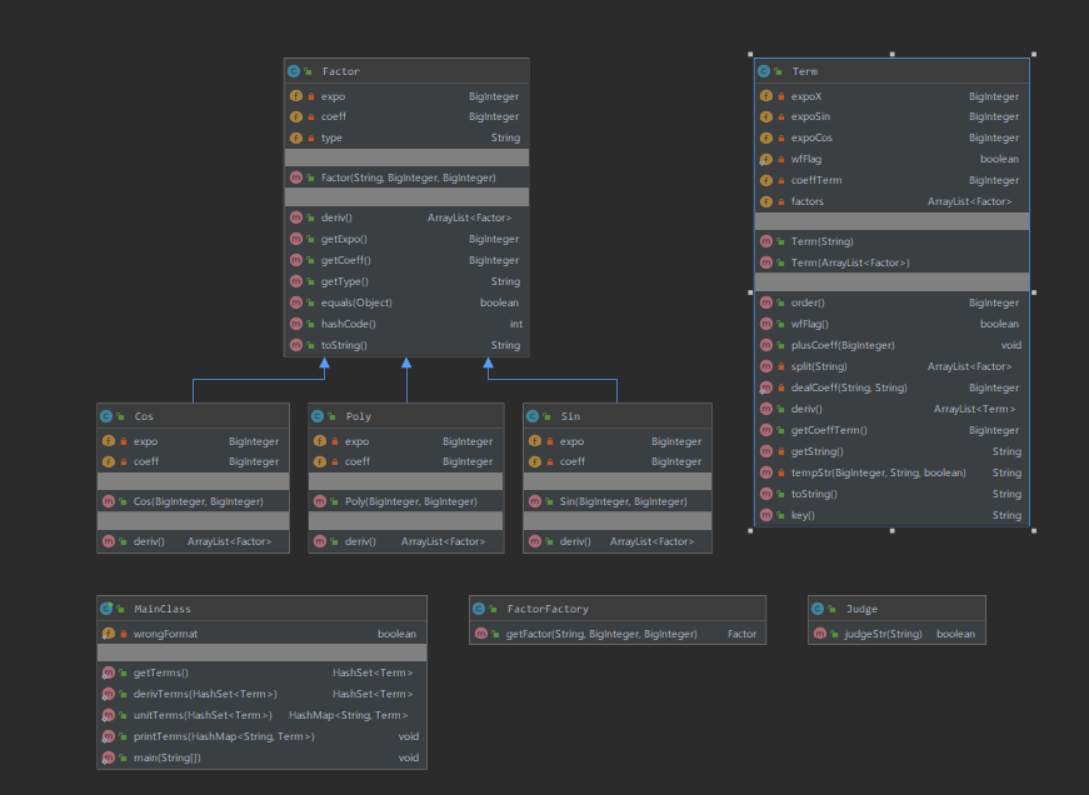
此次作业相对于上次作业基本是完全重构。这次作业我的代码逻辑比较混乱,对象主要分为了Factor和Term两个大类,Term类里存储了所含有的Factor。Factor包含三个子类,构造工厂Factor来生成它们。每个对象定义了对应的除和打印方法,但Term间的协调却在MainClass里完成,结构比较混乱。Judge函数用于判断字符串是否合法其实是后来添加的,因为我在写完代码后发现原有结构很多非法情况判断不出来,改也改不好,只好重写了一个判断。
2、程序复杂度
仅截取部分




这次作业的代码复杂度很高,主要集中在字符串的分割和获取打印内容部分,获取打印部分内容复杂度高的原因主要是我把化简和获取打印内容混在了一起。两个本来就复杂的内容纠缠不清会增加更高的复杂性,Term.getString()函数的复杂混乱就达到了惊人的程度。
3、bug分析
(1)这次作业强测爆炸,指数为1的情况我的处理存在错误,这样的错误是致命性的。其实我在课下时就已经发现此处有错误,并进行了改正,但由于自己代码设计的混乱,事实上自己只改正了部分。
(2)还有一个错误是判断合法空白符不能用s,这提示我应该更认真的看指导书。
4、发现别人bug的方法
这次互测我看了部分同学的代码去找bug,也测试了一些课下时自己出bug的数据。随着代码量的增长,靠阅读代码找bug变得越来越困难了。自己的互测朝着阅读易错部分代码和黑箱测试过渡。
5、反思
这次作业自己不够用心,写之前没有认真思考代码结构,导致代码结构混乱,bug众多,扩展性差,导致下次代码又得重构。写完代码也没有好好测试,很明显的bug都没被自己发现,甚至对已经发现的bug都不够重视,出现了改bug只改了一半的情况。此次作业我完成的很不理想,以后作业应引以为戒。
第三次作业
1、UML类图

这次作业相对于第二次作业又是完全重构。我在MainClass里对括号进行处理替换,在Judge类里判断表达式是否合法。但判断表达式是否合法对字符串分割和分离字符串的元素的分割是极为相似的,我纠结了很久,还是在判断是否合法时把元素分割出来了,造成结构有些混乱,不过我如果把Judge改个名字,混乱可能就能减少一点......元素的分割我采用了长正则匹配法,对括号中的内容进行了替换处理。我建立了Element父类,子类有Term(项)、Expression(表达式)、Factor(因子)。因子间构成树型结构,项的子结点有因子,表达式的子节点有项或因子,因子的子节点是因子或表达式(去括号操作)。每往下加一层,deep就加一,以便求导时根据深度由深向浅求导。没有子节点的元素是叶,分析可知,叶一定是常数乘x的幂函数形式。叶处求导方式固定,每一层再采取相对应的求导方式,由深到浅,即可完成求导。我的分割元素部分采用了递归方法,但求导时想不到有效的递归方法,导致程序化简程度低,性能不高,递归求导方法还要从同学的代码(互测时看到的)和博客中学习。
2、程序复杂度
仅截取部分



复杂度最高的还是在求导和分割部分,我单独为求导写了个类,但求导还是和元素紧密相关,难以分离,耦合度高。实际上,我的求导类对元素明显划分,是可以归到各个元素方法里面的,单独分出来可能是因为自己还是习惯面向过程,面向对象思维不够强。不过这样分也有好处,自己在写代码和测试求导时,更方面相互比价,自己的思路更加清晰。Judge分割字符串的复杂度也很高,这里用了递归方法,且一层层的创建元素,是代码中最复杂的部分。
3、bug分析
这次作业课下测试时,bug主要集中在括号处理附近。为避免匹配字符串匹配时遭遇无法解决的递归,我对括号内的字符串进行了替换,并用字典存储替换内容,以便在合适的时候换回去。这个过程比较抽象,我在此犯了不少错误,比如括号没处理好,括号未正确匹配等。
4、互测部分
这次作业代码很长,很难通过阅读代码查找bug。我提交了自己课下测试出现过bug的代码,和群里大家讨论容易出错的代码。同学的代码bug主要存在于递归层数过深触发异常和符号判断不正确触发异常的情况。
5、反思
有了上次的教训,这次写码前我就对自己的结构进行了思考,虽然求导化简方面自己没有想到好方法,但这次写码时思路明显比之前清晰,在难度增大的情况下bug反而减少了。
对比和心得体会
(1)我的代码没能很好的适应面向对象,不是说不能面向过程,只是我很多地方混在一起,结构混乱不清晰。以后要多加练习改进。
(2)想好再写,不然bug会很多。
(3)码码一时爽,一直码码一直爽(不是
(4)努力增强可扩展性,争取减少重构。
------------恢复内容结束------------