https://python123.io/ws/demo.html
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>
</body></html>
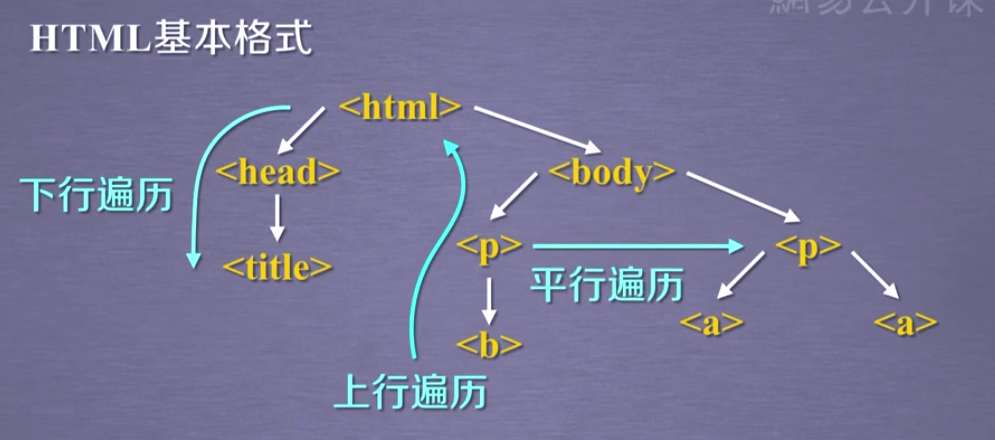
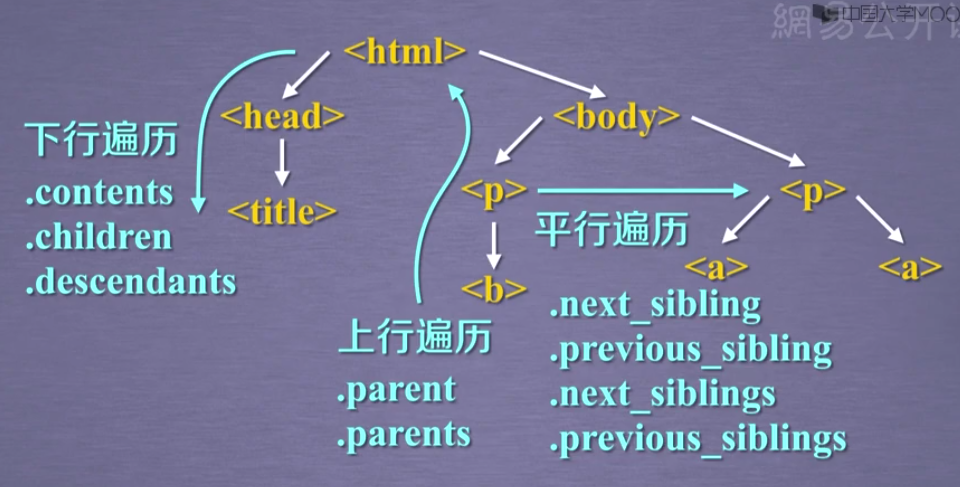
方法一:下行遍历

"""12 基于bs4库的HTML内容遍历方法"""
import requests
from bs4 import BeautifulSoup
#方法一:下行遍历
url = "https://python123.io/ws/demo.html"
r = requests.get(url)
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
# <head><title>This is a python demo page</title></head>
print(soup.head)
# [<title>This is a python demo page</title>]
print(soup.head.contents)
print(soup.body.contents)
# 5
print(len(soup.body.contents)) # 注意回车也是其元素
print(soup.body.contents[1])
# 使用.contents输出其元素
print('*'*10)
for content in soup.body.contents:
print(content)
print('*'*10)
###############################
print('#'*10)
# 使用.chidlren输出
for child in soup.body.children:
print(child)
print('#' * 10)
print('$'*10)
# 使用.descendants输出
for descendant in soup.body.descendants:
print(descendant)
print('$' * 10)
方法二:上行遍历

"""12 基于bs4库的HTML内容遍历方法"""
import requests from bs4 import BeautifulSoup
#方法二:上行遍历 url = "https://python123.io/ws/demo.html" r = requests.get(url) demo = r.text soup = BeautifulSoup(demo, "html.parser") # <head><title>This is a python demo page</title></head> print(soup.title.parent) print(soup.head.parent) # 整个html print('$' * 30) print(soup.html.parent) # 整个html print('$' * 30) print(soup.parent) # None ############### """ p body html [document] """ for parent in soup.a.parents: if parent is None: print(parent) else: print(parent.name)
方法三:平行遍历

"""12 基于bs4库的HTML内容遍历方法"""
import requests from bs4 import BeautifulSoup
#方法三:平行遍历 url = "https://python123.io/ws/demo.html" r = requests.get(url) demo = r.text soup = BeautifulSoup(demo, "html.parser") # and print(soup.a.next_sibling) print(soup.a.next_sibling.next_sibling) print(soup.a.previous_sibling) # None print(soup.a.previous_sibling.previous_sibling) #对a标签后序结点进行遍历 print('#'*30) for sibling in soup.a.next_siblings: print(sibling) print('#'*30) #对a标签前序结点进行遍历 print('@'*30) for sibling in soup.a.previous_siblings: print(sibling) print('@'*30)