1、索引数据结构B+树(为什么快)
1、 B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
2、B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3、由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
2、hash索引数据库为什么不能(表扫描,范围查询)
3、定位优化MySQL
explain
SHOW STATUS
4、count(*),count(1)区别
如果你的数据表没有主键,那么count(1)比count(*)快
如果有主键的话,那主键(联合主键)作为count的条件也比count(*)要快
如果你的表只有一个字段的话那count(*)就是最快的啦
5、innodb,mysam锁方面的区别,(文件有区别)
1. InnoDB支持事务,MyISAM不支持
2. InnoDB支持外键,而MyISAM不支持。
3. InnoDB是聚集索引,使用B+Tree作为索引结构,MyISAM是非聚集索引
4. InnoDB不保存表的具体行数
5. Innodb不支持全文索引,而MyISAM支持全文索引
6. MyISAM表格可以被压缩后进行查询操作
7. InnoDB支持行(默认)级锁
8、InnoDB表必须有唯一索引(如主键)
9、Innodb存储文件有frm、ibd,而Myisam是frm、MYD、MYI
Innodb:frm是表定义文件,ibd是数据文件
Myisam:frm是表定义文件,myd是数据文件,myi是索引文件
6、数据库事务四大特性
- 原子性(Actomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
- 一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以操持完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
- 隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
- 持久性(Durable):事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
7、隔离级别,并发的问题,如何解决(锁的是什么)
- 脏读(Dirty Reads):一个事务正在对一条记录做修改,在这个事务并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”的数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象地叫做“脏读”。
- 不可重复读(Non-Repeatable Reads):一个事务在读取某些数据已经发生了改变、或某些记录已经被删除了!这种现象叫做“不可重复读”。
- 幻读(Phantom Reads):一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读”。
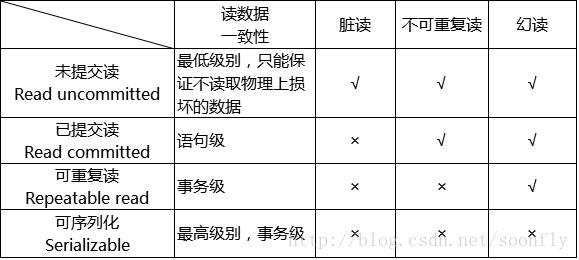
8、MySQL默认的隔离级别
可重复读
9、乐观锁和悲观锁
10、readis了解过吗
11、如何加载class文件的,JVM,类加载器
12、反射机制
13、类加载器的双亲委派机制
14、Java内存模型 堆,栈,本地方法栈,程序计数器
15、Java GC、算法
16、标记清除的缺点
17、引用计数算法
18、根可达算法
19、年轻代空间 Edan+0+1
20、fullGC触发的条件
21、垃圾收集器CMS、G1
22、强软弱虚引用
23、线程创建方式
24、start、run方法的区别
25、线程的返回值
处理线程的返回值
26、线程池
27、线程池的核心参数
1. corePoolSize:指定了线程池中的线程数量。
2. maximumPoolSize:指定了线程池中的最大线程数量。
3. keepAliveTime:当前线程池数量超过 corePoolSize 时,多余的空闲线程的存活时间,即多 次时间内会被销毁。
4. unit:keepAliveTime 的单位。
5. workQueue:任务队列,被提交但尚未被执行的任务。
6. threadFactory:线程工厂,用于创建线程,一般用默认的即可。
7. handler:拒绝策略,当任务太多来不及处理,如何拒绝任务。
28、线程池拒绝策略
29、hashmap存放数据怎么计算数组的下标
HashMap中数组下标值的计算过程,大致分为如下几步:
获取key.hashCode(),
然后将hashCode高16位和低16位异或(^)操作,
然后与当前数组长度-1结果进行与(&)操作,
最终结果就是数组的下标值。
30、hashmap扩容头插还是尾插
创建时尾插
31、spring bean的加载机制、生命周期
bean factory
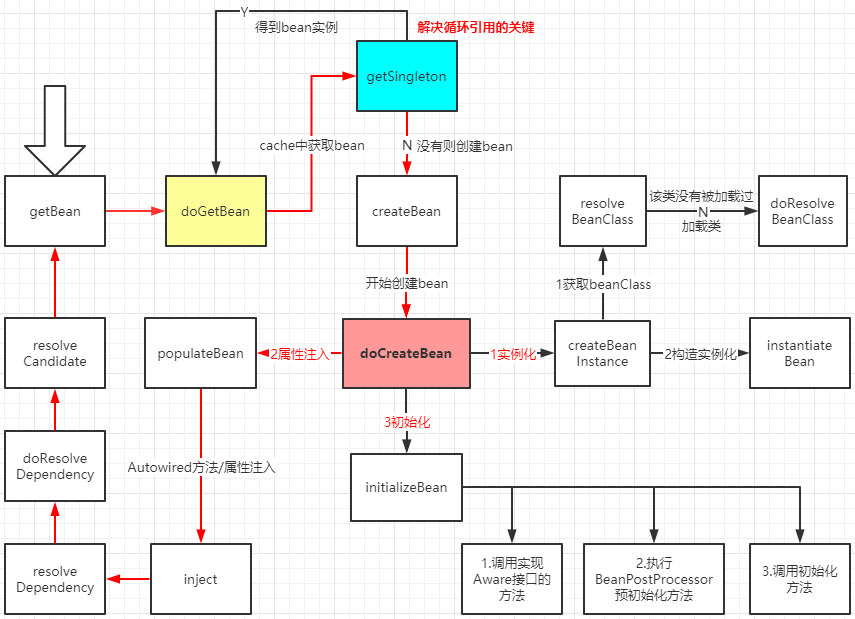
32、spring IOC AOP
33、AOP的实现原理
动态代理
34、动态代理的功能
让你可以在不用修改源码的情况下,增加一些方法,
- 动态代理事先不知道要代理的是什么,只有在运行的时候才能确定。
- 动态代理的调用处理程序必须事先InvocationHandler接口,及使用Proxy类中的newProxyInstance方法动态的创建代理类
35、mybatis的底层流程
配置-》sqlsessionfactory
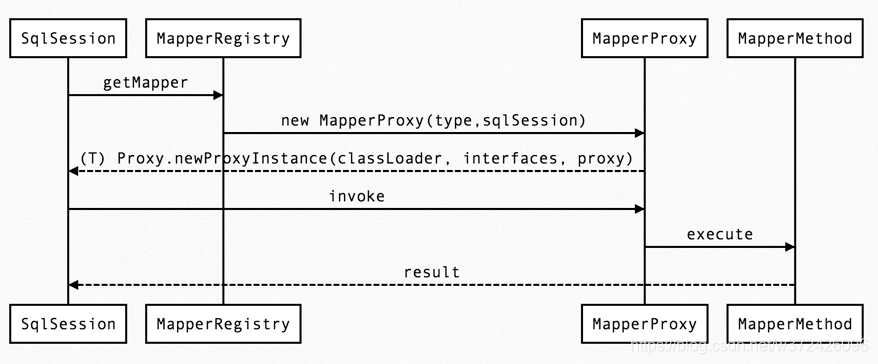
36、mybatis一级缓存、二级缓存
默认开启一级缓存,二级缓存需要配置
37、一级缓存会出现脏读吗
基于mybatis中的缓存机制,查询的结果是缓存中的结果,数据未得到即时更新。
38、算法
快速排序,
挖坑填数,
1、找到一个基准数
2、由后向前找到比基准数小的数,填到前一个坑位里
3、由前向后找到比前一个数大的数,填到前一个坑位里