爬取内容:
简书中每一篇文章的具体数据,主要包括文章标题、钻石数、发表日期、文章字数、文章阅读量、文章的评论量和点赞量等,这里爬取2000条左右保存至数据库
代码实现在文末!
分析思路:
- 首先,谷歌浏览器抓包,获取简书首页加载新文章的方式,当我们点击主页的加载更多的按钮的时候,后台发送了一个异步的POST请求来加载新文章
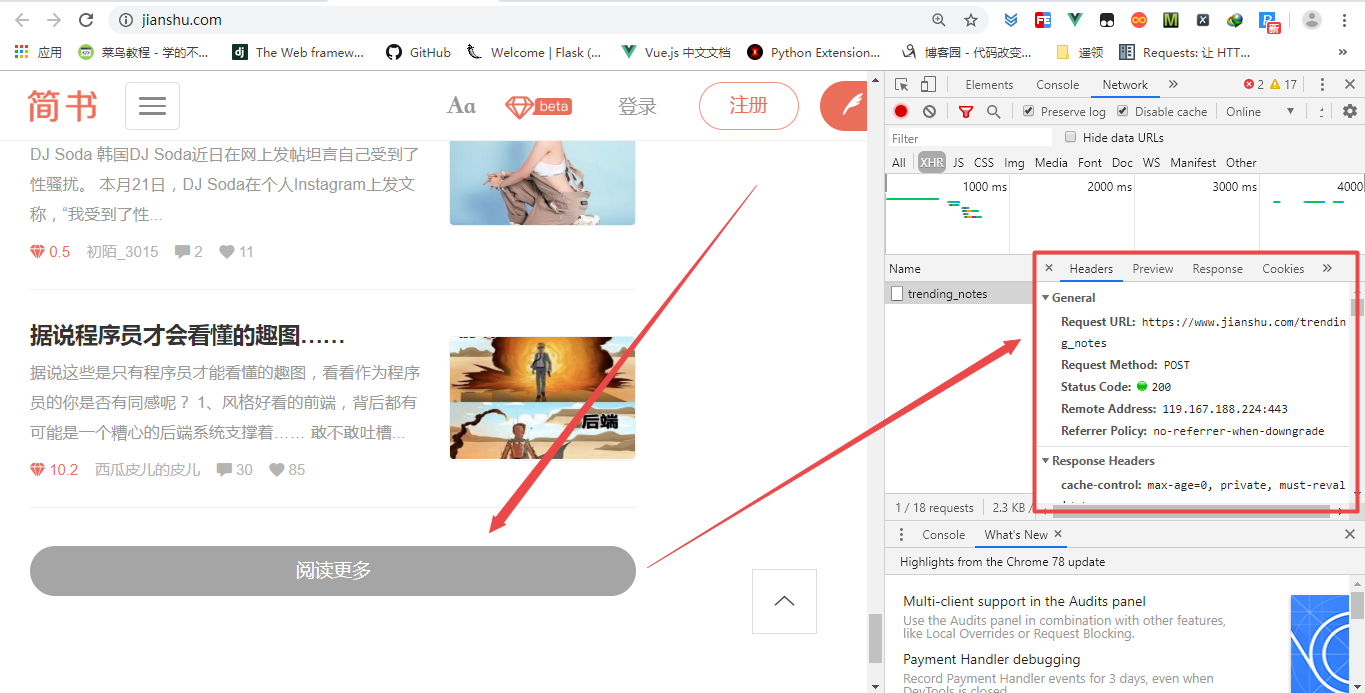
请求有一个page参数,即是我们需要的。而且可以观察到返回的并非json数据,而是html数据
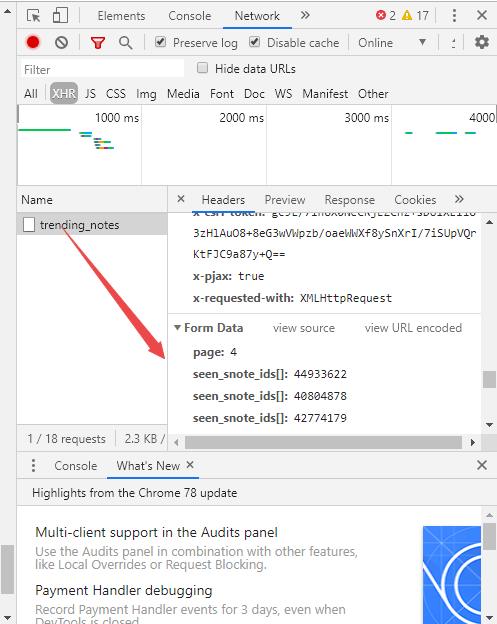

接下来,我们做的就是从返回的html中找出跳到具体文章内容的链接,这里过程就不加赘述,一会会在代码里看到
- 所以我们可有有如下的一个逻辑过程:
- 通过向简书发送POST请求,获取新的文章列表的html,当然参数page要变,以控制页码
- 从返回的html代码中解析出真正文章的url
- 向真正的文章页面发送请求,获取响应
- 从响应的页面代码中提取出我们想要的文章数据
- 整理文章数据后保存至数据库
相关库与方法:
- Python网络请求requests库
- 解析方法xpath,这里用到的是Python的lxml库
- 数据库链接mysql的库,pymysql
- 多线程及队列,Python的threading和queue模块
代码结构及实现:
1 # 简书爬虫项目 2 3 ### 目录结构 4 - lilei_spider 5 - ____init____.py 6 - jianshu_index.py 7 - config.py 8 - storage.py 9 - utils 10 - db.py 11 - tools.py 12 13 ## 文件说明: 14 #### jianshu_index.py 15 > 简书爬虫整体逻辑实现,也是运行项目的入口文件 16 17 #### config.py 18 > 项目中用到的配置参数 19 20 #### storage.py 21 > 实现数据的存储 22 23 #### db.py 24 > 数据库连接相关 25 26 #### tools.py 27 > 工具函数及工具类 28 29 #### article.sql 30 > 导出的数据库文件 31 32 #### requirements.txt 33 > 项目依赖库 34 35 ### 技术说明 36 - python网络请求库:requests 37 - 数据解析方法:xpath(lxml库) 38 - 连接数据库:pymysql 39 - 多线程:threading,queue
代码实现:
jianshu_index.py
1 import requests 2 import threading 3 from queue import Queue 4 from lxml import etree 5 6 from config import INDEX_ADDRESS as index_address 7 from config import ADDRESS as address 8 from config import HEADERS as headers 9 from storage import Storage 10 from utils.tools import DecodingUtil 11 12 13 class JianshuSpider(object): 14 """爬取简书首页数据的爬虫类""" 15 def __init__(self): 16 self.max_page = 300 # 爬取总文章数:300*7=2100 17 self.params_queue = Queue() # 存放地址发送post请求参数的队列 18 self.url_queue = Queue() # 存放文章url的队列 19 self.index_queue = Queue() # 存放首页响应的新文章列表的队列 20 self.article_queue = Queue() # 存放文章响应内容的队列 21 self.content_queue = Queue() # 存放格式化后的文章数据内容的队列 22 23 def get_params_list(self): 24 """构造post请求的page参数队列""" 25 for i in range(1, self.max_page+1): 26 self.params_queue.put({'page': i}) 27 28 def pass_post(self): 29 """发送POST请求,获取新的文章列表,请求参数从队列中取出""" 30 while True: 31 response = requests.post(index_address, data=self.params_queue.get(), headers=headers) 32 self.index_queue.put(DecodingUtil.decode(response.content)) # 返回结果放入队列 33 self.params_queue.task_done() # 计数减一 34 print('pass_post', '@'*10) 35 36 def parse_url(self): 37 """根据首页返回的新的文章列表,解析出文章对应的url""" 38 while True: 39 content = self.index_queue.get() # 从队列中取出一次POST请求的文章列表数据 40 html = etree.HTML(content) 41 a_list = html.xpath('//a[@class="title"]/@href') # 每个li标签包裹着一篇文章 42 for a in a_list: 43 url = a # xpath解析出文章的相对路径 44 article_url = address + url 45 self.url_queue.put(article_url) # 放入队列 46 self.index_queue.task_done() 47 print('parse_url', '@'*10) 48 49 def pass_get(self): 50 """发送GET请求,获取文章内容页""" 51 while True: 52 article_url = self.url_queue.get() # 从队列中获取文章的url 53 response = requests.get(article_url, headers=headers) 54 self.article_queue.put(DecodingUtil.decode(response.content)) # 返回结果放入队列 55 self.url_queue.task_done() 56 print('pass_get', '@'*10) 57 58 def get_content(self): 59 while True: 60 article = dict() 61 article_content = self.article_queue.get() 62 html = etree.HTML(article_content) 63 # 标题:title,钻石:diamond,创建时间:create_time,字数:word_number 64 # 阅读量:read_number,评论数:comment_number,点赞数:like_number,文章内容:content 65 article['title'] = html.xpath('//h1[@class="_2zeTMs"]/text()')[0].strip(' ').strip(' ') 66 try: 67 article['diamond'] = html.xpath('//span[@class="_3tCVn5"]/span/text()')[0] 68 except IndexError: 69 article['diamond'] = '' 70 article['create_time'] = html.xpath('//div[@class="s-dsoj"]/time/text()')[0].replace(' ', '') 71 article['word_number'] = html.xpath('//div[@class="s-dsoj"]/span[2]/text()')[0].split(' ')[-1] 72 article['read_number'] = html.xpath('//div[@class="s-dsoj"]/span[last()]/text()')[0].split(' ')[-1] 73 article['comment_number'] = html.xpath('//div[@class="_3nj4GN"][1]/span/text()[last()]')[0] 74 article['like_number'] = html.xpath('//div[@class="_3nj4GN"][last()]/span/text()[last()]')[0] 75 content = html.xpath('//article[@class="_2rhmJa"]') # html富文本内容 76 article['content'] = DecodingUtil.decode(etree.tostring(content[0], method='html', encoding='utf-8')) 77 self.content_queue.put(article) # 放入队列 78 self.article_queue.task_done() # 上一队列计数减一 79 print('get_content', '@'*10) 80 81 def save(self): 82 """保存数据""" 83 while True: 84 article_info = self.content_queue.get() # 队列中获取文章信息 85 # print(article_info) 86 Storage.save_to_mysql(article_info) # 文章数据保存到mysql数据库 87 self.content_queue.task_done() 88 print('save', '*'*20) 89 90 def run(self): 91 # 0.各个方法之间利用队列来传送数据 92 # 1.简书首页加载新数据方式为POST请求,url不变,参数page变化,所以首先构造一个params集 93 # 2.遍历params集发送POST请求,获取响应 94 # 3.根据每一次获取的文章列表,再获取对应的真正文章内容的页面url 95 # 4.向文章内容页面发送请求,获取响应 96 # 5.提取对应的数据 97 # 6.保存数据,一份存入数据库,一份存入excel 98 thread_list = list() # 模拟线程池 99 t_params = threading.Thread(target=self.get_params_list) 100 thread_list.append(t_params) 101 for i in range(2): # 为post请求开启3个线程 102 t_pass_post = threading.Thread(target=self.pass_post) 103 thread_list.append(t_pass_post) 104 for j in range(2): # 为解析url开启3个线程 105 t_parse_url = threading.Thread(target=self.parse_url) 106 thread_list.append(t_parse_url) 107 for k in range(5): # 为get请求开启5个线程 108 t_pass_get = threading.Thread(target=self.pass_get) 109 thread_list.append(t_pass_get) 110 for m in range(5): # 为提取数据开启5个线程 111 t_get_content = threading.Thread(target=self.get_content) 112 thread_list.append(t_get_content) 113 # for n in range(5): # 为保存数据开启5个线程 114 t_save = threading.Thread(target=self.save) # 保存数据一个线程 115 thread_list.append(t_save) 116 # ===================================================================================================== 117 for t in thread_list: 118 t.setDaemon(True) # 把子线程设置为守护线程,主线程结束,子线程结束 119 t.start() 120 for q in [self.params_queue, self.url_queue, self.index_queue, self.article_queue, self.content_queue]: 121 q.join() # 让主线程等待阻塞,等待队列的任务完成之后再结束 122 print('主线程结束......') 123 124 125 if __name__ == '__main__': 126 jianshu_spider = JianshuSpider() 127 jianshu_spider.run()
config.py
1 import os 2 3 4 ADDRESS = 'https://www.jianshu.com' # 简书网地址 5 6 INDEX_ADDRESS = 'https://www.jianshu.com/trending_notes' # 首页加载数据的地址 7 8 HEADERS = { 9 'x-pjax': 'true', 10 'referer': 'https://www.jianshu.com/', 11 'Content-Type': 'application/x-www-form-urlencoded', 12 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 13 'Chrome/77.0.3865.120 Safari/537.36', 14 'x-csrf-token': 'PRFNi9/FDZmm/bV4f8ZueVNFln0PpQ5kgsMcSERpwpNugy/bcOBgNEZvBo4/aTwrm28awdmuTfcMaHcogJ1mdA==' 15 }
storage.py
1 import pandas as pd 2 from utils.db import conn 3 from utils.tools import rep_invalid_char 4 5 6 class Storage(object): 7 """存储数据""" 8 cursor = conn.cursor() 9 excel_writer = pd.ExcelWriter('article.xlsx') 10 11 def __init__(self): 12 pass 13 14 @classmethod 15 def save_to_mysql(cls, article:dict): 16 """字典类型的文章数据保存到数据库""" 17 title = article.get('title', '') 18 diamond = article.get('diamond', '') 19 create_time = article.get('create_time', '') 20 word_number = article.get('word_number', '') 21 read_number = article.get('read_number', '') 22 comment_number = article.get('comment_number', '') 23 like_number = article.get('like_number', '') 24 content = rep_invalid_char(article.get('content', '')) 25 # content = article.get('content', '') 26 27 sql = "INSERT INTO `article2` (`title`,`diamond`,`create_time`,`word_number`,`read_number`,`comment_number`," 28 "`like_number`,`content`) VALUES ('{}','{}','{}','{}','{}','{}','{}','{}');".format(title, diamond, 29 create_time, word_number, read_number, comment_number, like_number, content) 30 try: 31 cls.cursor.execute(sql) 32 conn.commit() 33 except Exception as e: 34 print(e) 35 # raise RuntimeError('保存至数据库过程Error!') 36 print('保存至数据库过程Error!')
db.py
1 import pymysql 2 3 4 class DB(object): 5 """数据库连接""" 6 _host = '127.0.0.1' 7 _user = 'root' 8 _password = '******' 9 _db = 'homework' 10 11 @classmethod 12 def conn_mysql(cls): 13 return pymysql.connect(host=cls._host, user=cls._user, password=cls._password, db=cls._db, charset='utf8') 14 15 16 conn = DB.conn_mysql()
tools.py
1 import re 2 import chardet 3 4 5 class DecodingUtil(object): 6 """解码工具类""" 7 @staticmethod 8 def decode(content): 9 """ 10 读取字节数据判断其编码,并正确解码 11 :param content: 传入的字节数据 12 :return: 正确解码后的数据 13 """ 14 # print(chardet.detect(content)) 15 the_encoding = chardet.detect(content)['encoding'] 16 try: 17 return content.decode(the_encoding) 18 except UnicodeDecodeError: 19 print('解码Error!') 20 try: 21 return content.decode('utf-8') 22 except: 23 return '未能成功解码的文章内容!' 24 25 26 def rep_invalid_char(old:str): 27 """mysql插入操作时,有无效字符,替换""" 28 invalid_char_re = r"[/?\[]*:]" 29 return re.sub(invalid_char_re, "_", old)