1、pandas数据的读取
pandas需要先读取表格类型的数据,然后进行分析
| 数据说明 | 说明 | pandas读取方法 |
| csv、tsv、txt | 用逗号分割、tab分割的纯文本文件 | pd.read_csv |
| excel | 微软xls或者xlsx文件 | pd.read_excel |
| mysql | 关系向数据库表 | pd.read_sql |
#本代码示例: import pandas as pd #导入包 #1读取csv,使用默认的标题行、逗号分割 fpath = “要打开文件的路径” ratings = pd.read_csv(fpath) #使用pd.read_csv读取数据 ratings.head() #查看前几行(默认5行) ratings.shape #查看数据的形状,返回(行数、列数) ratings.columns # 查看列名列表 ratings.index #查看索引列 ratings.dtypes #查看每一列的数据类型 #1.2读取txt文件,自己制定分隔符、列名 fpath = “文件的路径” pvuv = pd.read_csv( fpath, sep = “ ”, #l列的分隔符 header = None, names = ['pdate','pv','uv'] ) print(pvuv) #读取excel文件 fpath = “文件的路径” pvuv = pd.read_excel(fpath) print(pvuv) #读取Mysql数据库 import pmysql conn = pmysql.connect( host = '127.0.0.1', user = 'root', password = '123456', database = 'test', charest = 'utf8' ) mysql_page = pd.read_sql("select * from 表名",con=conn) print(mysql_page)
2、pandas数据结构(DataFrame & Series)
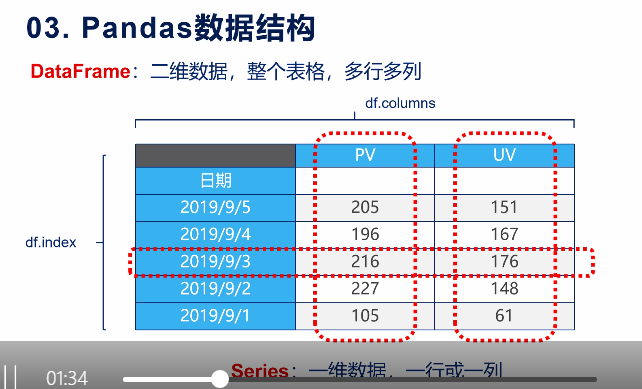
DataFrame:二维数据,整个表格,多行多列
df.columns 查询列
df.index 查询行
Series:一维数据,一行或者一列
#1、 Series #2、DataFrame #3、从DAtaFrame中查询出Series import pandas as pd import numpy as np #series是一种类似于一维数组的对象,它由一组数据(不同数据类型)以及一组与之相关的数#据标签(即索引)组成。 #1.1仅有数据列表即可产生最简单的series s1 = pd.Series([1,'a',5.2,6]) # print(s1) #左侧为索引,右侧为数据 print(s1.index) #获取索引 结果:RangeIndex(start=0, stop=4, step=1) print(s1.values) #获取数据 结果:[1 'a' 5.2 6] #1.2 创建一个具有标签索引的Series s2 = pd.Series([1,'a',5.2,6],index = ['d','b','a','c']) print(s2) print(s2.index) #Index(['d', 'b', 'a', 'c'], dtype='object') #1.3 使用python字典创建Series sdata = {'ohio':3500,'Texas':72000,'Oregs':16000,'Ggrqg':5000} s3 = pd.Series(sdata) print(s3) #1.4 根据标签索引查询数据(类似python的字典dict) print(s2['a'])#5.2 print(type(s2['a']))#<class 'float'> print(s2[['b','a']]) #2 DataFrame # DataFrame是一个表格型的数据结构 # 每一列可以是不同的值类型(数值、字符串、布尔值) # 既有行索引index,也有列索引columns # 可以被看由Series组成的字典 #2.1根据多个字典序列创建dataframe data = { 'state':['ofjg','sdfg','werw','wrgwer','rgwg'], 'year':[2000,3000,5000,6000,9000], 'pop':[1.5,1.7,1.6,5.3,3.5] } df = pd.DataFrame(data) print(df) #3.从DataFrame中查询Series # 如果只查询一列,返回的是pd.Series # 如果查询多行、多列,返回的是pd.DataFrame # 3.1 查询一列 结果是一个pd.Series print(df['year']) print(type(df['year']))#<class 'pandas.core.series.Series'> # 3.2 查询多列,结果是一个pd.DataFrame print(df[['year','pop']]) print(type(df[['year','pop']]))#<class 'pandas.core.frame.DataFrame'> # 3.3 查询一行,结果是一个pd.Series print(df.loc[1]) print(type(df.loc[1]))#<class 'pandas.core.series.Series'> # 3.4 查询多行,结果是一个pd.DataFrame print(df.loc[1:3]) print(type(df.loc[1:3]))#<class 'pandas.core.frame.DataFrame'>