Abstract
微人脸的超分辨率与特征点定位是高度相关的任务。一方面,利用高分辨率的人脸可以获得更高的精度特征点的定位。另一方面,面部SR将受益于对面部属性(如特征点)的先验知识。(意思时人脸的超分和人脸特征点的定位相互促进)。更具体地说,一个共享的深度编码器被应用于通过利用互补的信息来为两个任务提取特性。为了利用分级编码器的代表能力,将共享特征提取模块的中间层融合以形成有效的特征表示。融合后的特征被输入到特定任务的模块,以同时地检测人脸特征点和超分辨人脸图像。大量的实验表明,论文中提出的模型在特征点定位和人脸识别方面都优于目前的先进技术。我们对tiny face 的特征点的定位有了很大的改进(即 16×16)。该框架在低分辨率(LR)(即,64 * 64)人脸上的特征点的定位对现有的人HR方法(即, 256×256)产生了可比较的结果。在SR方面,与其他先进的方法相比,我们从定性和定量的角度证明了所提出的方法在恢复低分辨率的人脸图像更锐利的边缘和更多的细节。
Introduction
人脸自动识别是人类感知、视觉理解、风格转换和应用的机器视觉(如特征点定位,身份识别,人脸检测)等问题的关键。现代基于人脸的任务模型在应用于低分辨率图像时往往会失效。最近的研究表明:分辨率的降低(i.e., < 30×30) 会使得人脸特征点定位的的模型的误差增加。为了解决这个问题,人脸SR(也称为面部幻觉),旨在从LR图像生成高分辨率(HR)人脸。恢复后的面部会提供更详细的信息(例如,更清晰的边缘,更清晰的形状,和更精细的皮肤细节),通常用于改进分析和感知。然而,大多数已经存在的方法(e.g., Superfan (Bulat and Tzimiropoulos 2018))很大程度上依赖于复原图像的质量。由于SR方法通常存在模糊问题,将SR图像用于人脸相关任务可能会影响最终的预测或结论
另一方面,人脸先验知识可以用于提取高质量的SR人脸。在单图像超分辨(SISR)问题中,人脸SR利用先验知识来提高推断图像的精度,从而获得更高质量的结果。例如,可以利用低层信息(如颜色的平滑)面部热图和面部解析图提供额外的中层信息(如人脸的structure)来恢复更锐利的边缘和形状。而且,可以使用身份标签提取高级信息和其他人脸属性(如性别,年龄和姿势)。然后利用它来减少幻脸的模糊性。因此,额外的面部信息对于SR是有益的,特别是对于微小的面部。
先前在人脸识别方面的工作要么是使用先验信息进行超分辨的LR图像(e.g., FSRNet (Chen et al. 2018)不然就是直接在超分辨图像上定位特征点(e.g., SuperFAN (Bulat and Tzimiropoulos 2018))。SuperFAN只使用SR来帮助定位小脸的landmarks,但反之亦然。此外,我们的模型不处理恢复的SR输出,因为它存在模糊性,所以我们专门设计了一个编码模块来最大化从LR面部捕获的信息量。在FSRNet中,特征点只是作为人脸先验知识来进行人脸的超分辨,这与在恢复的粗糙SR图像上检测特征点的存在的问题是一样的。此外,SuperFAN和FSRNet分别处理这两个任务,导致冗余的特征图(feature maps)。由于人脸SR和landmarks定位任务可以相互受益,我们的目标是通过同时处理这两个任务,从LR人脸中提取最大数量的信息。因此,我们提出了一个多任务框架,允许这些任务相互受益,从而提高了两个任务的性能。(看图1)
论文的主要贡献如下:
1. 提出了一个对微小人脸进行SR和特征点检测的网络(称为JASRNet)。第一个联合学习特征点定位和SR的多任务模型。与现有的两步方法不同,我们利用两项任务的互补信息。这允许在LR空间中做出更准确的特征点预测,并改进LR到HR的重构。
2. 在最大化程度地从LR人脸捕获信息时用到了新的深度特征提取和融合模块,而它们是在编码器中间层进行的,以便利用深度层次机制
3. 我们在SR和微小人脸(即16x16)特征点定位方面取得了很大的进步. 除此之外,我们的JASRNet在低分辨率人脸特征点定位产生的结果可与现存的评估HR人脸方法以较高低。并且我们提出的恢复HR人脸的方法比现有的方法有更锐利的边缘和形状
Method
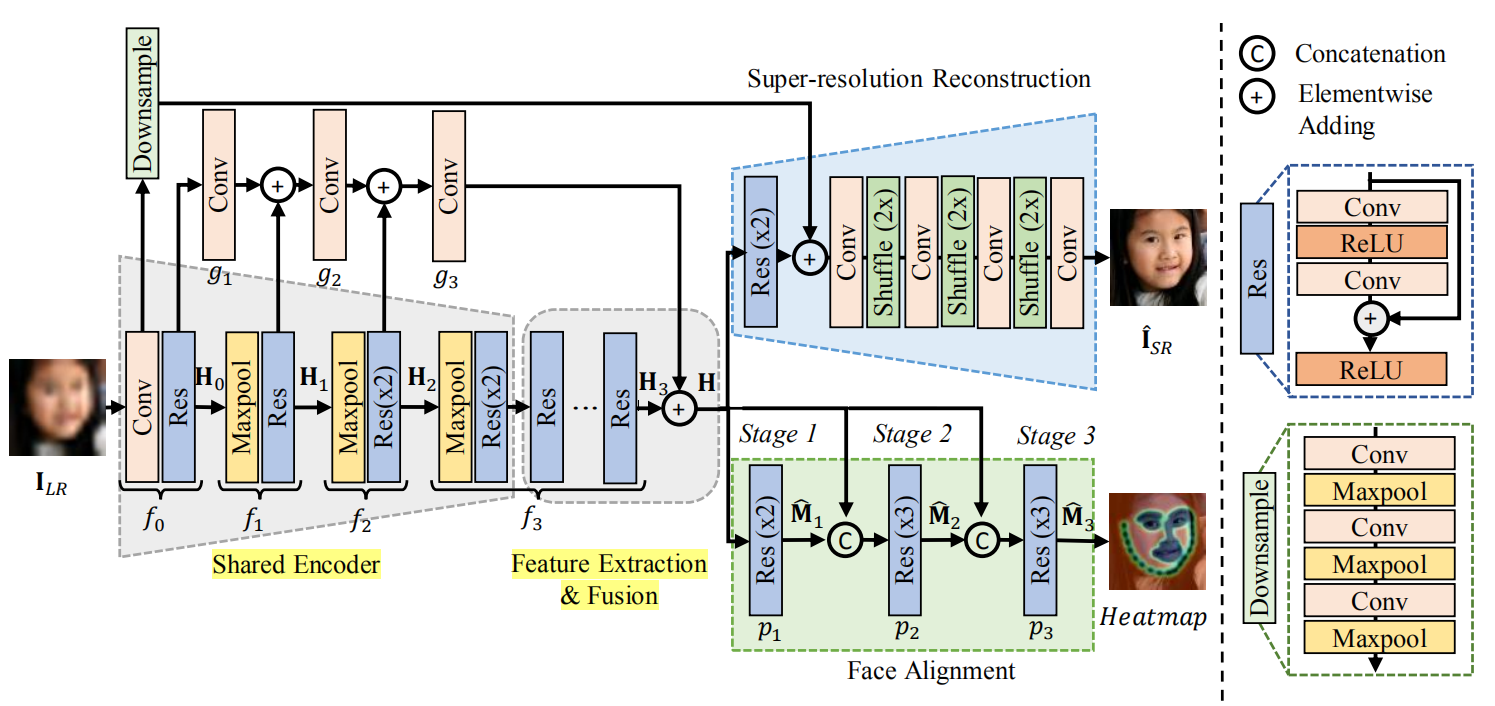
图3:论文中提出的JASRNet的框架。共享编码模块(Shared Encoder)是为双任务提取浅层特征和共享特征。采用深度特征提取和融合模块(The deep feature extraction and fusion)是为了获得更好的特征表示。super-resolution and face alignment模块是超分辨率重构模块和人脸对齐模块
论文提出了联合对齐和超分辨率网络(即JASRNet),同时对小人脸进行超分辨率建模和特征点定位。论文的框架如图3所示

原始LR图片被喂入给共享的编码器,然后编码器将数据输入到特征提取模块,为这两个任务提取特征。接着,融合的特征被输入到两个特定任务的模块。同时生成超分辨率图片(IHR(i))和特征点估计的概率图(M(i))
在人脸对齐方面,SR模块恢复了分辨率较高的图像,从而帮助模型检测到更准确的特征点。对齐模块定位脸部的边缘和结构,迫使更多的关注高频内容(即边缘)。因此这两种任务,即人脸SR和特征点定位,都适合相互受益。这项工作的目的是获得最大的信息量,而这些信息量是从低分斌率的人脸中提取的。信息的获得通过结合每个任务的损失函数来实现的。对于SR任务,L1损失是最小的,因为它能提供比L2更好的收敛性。在对齐任务中,使用L2热图损失。加在一起,JASRNet的损失函数可以表示为

a为热图损失的权值
Shared feature extraction and fusion
Shallow encoder:
以前的face SR和alignment工作通常分别处理这两个任务,导致冗余的feature map。为了有效地从LR图像中提取特征,设计了一个共享编码器来提取浅层特征,从而捕获两个任务的互补信息。Shallow encoder由一个卷积和一个残差块,
然后由maxpooling操作和残差块组成三个转换(如图3)。编码器的中间层后来被融合以获得更丰富的几何和语义特征。
JASRNet的所有卷积层都使用大小为3×3的卷积核,每层后接一个ReLU层。
Deep feature extraction and fusion
研究表明,深度网络在许多计算机视觉任务中有更好的表现,包括SR。增加深度也是这项工作中使用的一种策略。从共享编码器中提取的浅层特征被传递到由T个残差块组成的深度特征提取模块,在报告的实验中T = 32。一个深度网络不仅可以恢复超分辨人脸图像使其有更锐利的边缘和形状,而且可以实现更高精度的特征点定位。
Inspired by Hyperface (Ranjan, Patel, and Chellappa 2019)我们融合了中间层,以利用特征在不同层次上的代表能力。考虑到相邻层特征的相似性,并没有将共享编码器的所有特征融合在一起构成新的特征表示。由于每个maxpooling层都以2倍对feature map进行下采样,所以在每个maxpooling层之前的层的输出使用skip连接进行分支,然后被融合成包含几何信息的更丰富的feature。为了匹配feature map的大小,对于与skip连接并行应用的每个maxpooling层,使用步长为2的
3x3 的卷积层对feature2倍的下采样并进行融合(迷糊)
maxpooling之前的输出记为Hi(i∈{0,1,2});特征提取模块的最后一个残差块输出为H3(图3)ILR作为输入。则有
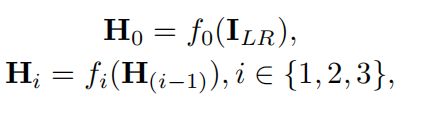
fi(·)(i∈{0,1,2,3})在特征提取过程中对信号进行变换。因此,f0是第一卷积层与残差块的映射,f1和f2分别是maxpooling与残差块结合的第一步和第二步的映射,f3是构成特征提取模块的剩余残差块的映射。【结合图3看】
从数学上讲,作为输出的融合特征H可以建立为

其中,卷积运算gi(·)(i∈{1,2,3})融合中间特征。
Task-specifific modules
Super-resolution reconstruction.
超分辨率重建模块根据16×16的共享特征重构HR图像。首先,将共享特征映射(feature maps)输入两个残差块,提取任务相关特征。接下来,有3个卷积层,每个卷积层后面都跟一个像素调整层(pixel shufflfle layers),使feature maps的大小夸大为原来的2倍(i.e., 16 × 16 to 128 × 128)。最后,由3×3个滤波器组成的卷积层,从HR RGB图像空间进行映射。
Inspired by EDSR (Lim et al. 2017) and RDN (Zhang etal. 2018), 共享编码器和SR重构模块的第一个和最后一个残差块通过一个大跳跃连接( a large skip connection)。这恢复了具有更精细细节的HR图像(即。,更锐利的边缘和形状)
The skip connection直接提供低频信息的超分辨图像。因此,它迫使网络专注于学习高频信息,而不是已经提供的低频信息。由于第一个卷积层的输出大小为128×128,重建模块中最后一个残块的feature map大小为16×16,因此我们采用3个卷积和3个maxpooling层对128×128 feature map进行了8倍的采样(图3)。
与SuperFAN不同,在SuperFAN中,长跳转连接( the long skip connection)对整体性能的影响最小,我们的模型主要受益于跳转连接( the long skip connection)。这是因为所提取的特征包含高频信息,因此可以更有效地恢复锐利和准确的边缘。此外,由于超分辨率和人脸对齐共享深度特征(the deep features ),这种长跳跃连接(long skip connection)的一个byproduct 也提高了特征点定位任务的性能。
Face alignment.
与SR重构模块一样,将共享特征H通过连续残差块输入,提取出针对人脸对齐的特征。 受卷积姿势机器 (CPM)在人脸对齐方面成功的启发(Wei et al. 2016) ,我们还利用剩余块组成的顺序框架来估计t特征点的位置。在第一阶段,两个残块预测粗略的热图![]() .在第二阶段,热图
.在第二阶段,热图![]() 预测在第一阶段第一个连接的特征图H,然后喂给由三个连续的残差块组成的第二个预测模块来预测的热图
预测在第一阶段第一个连接的特征图H,然后喂给由三个连续的残差块组成的第二个预测模块来预测的热图![]() 。第三阶段是连接特征图H和
。第三阶段是连接特征图H和 ![]() 产生最后一个估计
产生最后一个估计![]() ,表示如下:
,表示如下:
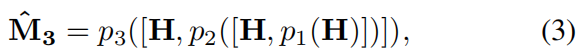
其中pj将预测模块映射为(j∈{1,2,3})。注意,特征图的大小在整个面部对齐模块中是恒定的(即 16×16)。 在训练期间,我们使用heatmap回归L2损失来定位特征点,而不是直接预测像素坐标(x, y)。因此,argmax用于在最后阶段(即![]() )从预测的热图中确定(x, y)。具体地说,K个heatmap中每一个的最大值被找到作为预测的特征点
)从预测的热图中确定(x, y)。具体地说,K个heatmap中每一个的最大值被找到作为预测的特征点![]()