窗口函数对于一些统计应用情况有非常好的使用效果,本文主要举例使用常用的几种窗口函数。
定义
数据准备
CREATE TABLE empsalary( depname varchar, empno bigint, salary int, enroll_date date ); INSERT INTO empsalary VALUES('develop',10, 5200, '2007/08/01'); INSERT INTO empsalary VALUES('sales', 1, 5000, '2006/10/01'); INSERT INTO empsalary VALUES('personnel', 5, 3500, '2007/12/10'); INSERT INTO empsalary VALUES('sales', 4, 4800, '2007/08/08'); INSERT INTO empsalary VALUES('sales', 6, 5500, '2007/01/02'); INSERT INTO empsalary VALUES('personnel', 2, 3900, '2006/12/23'); INSERT INTO empsalary VALUES('develop', 7, 4200, '2008/01/01'); INSERT INTO empsalary VALUES('develop', 9, 4500, '2008/01/01'); INSERT INTO empsalary VALUES('sales', 3, 4800, '2007/08/01'); INSERT INTO empsalary VALUES('develop', 8, 6000, '2006/10/01'); INSERT INTO empsalary VALUES('develop', 11, 5200, '2007/08/15');
操作
1.row_number():返回行号,对比值重复时行号不重复不间断, 即返回 1,2,3,4,5....,不返回 1,2,2,4...
select row_number() over(),* from empsalary limit 2;

select row_number() over(),* from empsalary limit 2 offset 2;

--按depname分组,salary排序,注意红色记录行号不间断 select row_number() over(partition by depname order by salary),* from empsalary;

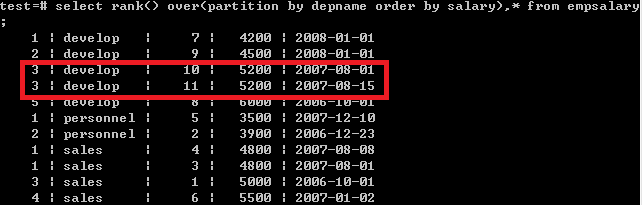
2.rank():返回行号,对比值重复时行号重复并间断, 即返回 1,2,2,4...
select rank() over(partition by depname order by salary),* from empsalary;
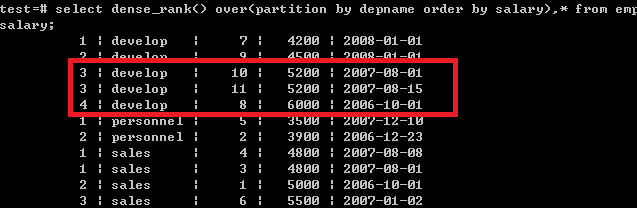
3.dense_rank():返回行号,对比值重复时行号重复但不间断, 即返回 1,2,2,3
select dense_rank() over(partition by depname order by salary),* from empsalary;
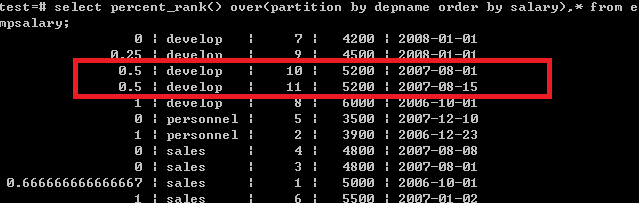
4.percent_rank():从当前开始, 计算在分组中的比例 (行号-1)*(1/(总记录数-1))
select percent_rank() over(partition by depname order by salary),* from empsalary;
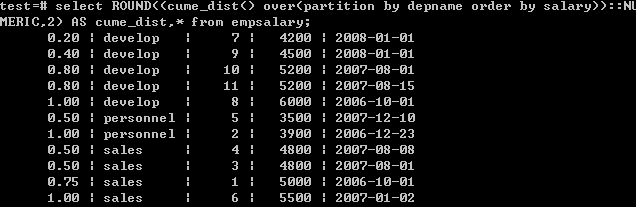
5.cume_dist() :返回行数除以记录数值
select ROUND((cume_dist() over(partition by depname order by salary))::NUMERIC,2) AS cume_dist,* from empsalary;
6.ntile(分组数量):让所有记录按分组数目尽可以的均匀分布
select ntile(3) over(partition by depname order by salary),* from empsalary;

7.lag(value any [, offset integer [, default any ]]):返回偏移量值, offset integer 是偏移值, 正数时前值, 负数时后值, 没有取到值时用 default 代替;所谓正偏移即当前行的值salary按照偏移量offset偏移到下面对应的行,负偏移同。见红色标识
select lag(salary,1,null) over(partition by depname order by enroll_date),* from empsalary;

8.lead(value any [, offset integer [, default any ]]):返回偏移量值, offset integer 是偏移值, 正数时取后值,负数时取前值, 没有取到值时用 default 代替。
select lead(salary,1,2) over(partition by depname order by enroll_date),* from empsalary;

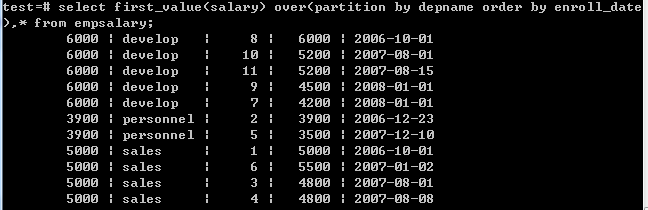
9.first_value(value any)返回第一值
select first_value(salary) over(partition by depname order by enroll_date),* from empsalary;
10.last_value(value any)返回最后值
select last_value(salary) over(partition by depname order by enroll_date),* from empsalary;
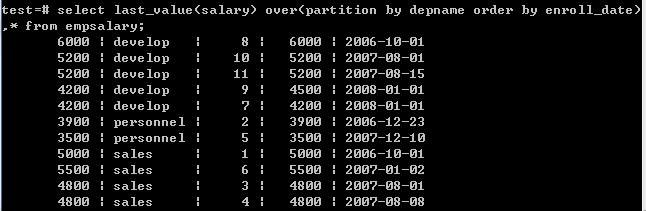
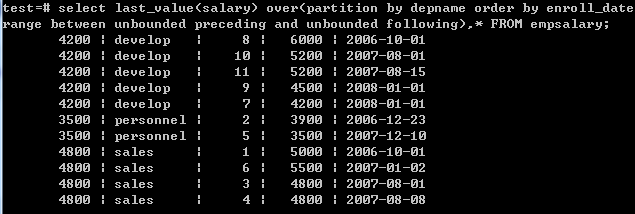
从返回结果看,似乎有问题,默认情况下, 带了 order by 参数会从分组的起始值开始一直叠加, 直到当前值不同为止,通过修改分组的统计范围就可以实现 order by 参数取最后值.
select last_value(salary) over(partition by depname order by enroll_date range between unbounded preceding and unbounded following),* FROM empsalary;
11.nth_value(value any, nth integer):返回窗口框架中的指定值,如nth_value(salary,2),则表示返回字段salary的第二个窗口函数值
select nth_value(salary,2) over(partition by depname order by enroll_date),* from empsalary;

12.同时调用多个窗口函数可用下面别名简化写法
select sum(salary) over w,avg(salary) over w,* from empsalary window w as (partition by depname order by enroll_date); 与下面写法同: select sum(salary) over(partition by depname order by enroll_date),avg(salary) over(partition by depname order by enroll_date),* from empsalary;
