此程序功能:
1.完成对10.4G.csv文件各个元素频率的统计
2.获得最大的统计个数
3.对获取到的统计个数进行降序排列
4.对各个元素出现次数频率的统计
import org.apache.spark.{SparkConf, SparkContext} /** */ object 大数据统计 { def main(args: Array[String]): Unit = { val conf=new SparkConf().setAppName("大数据").setMaster("local[4]") val sc=new SparkContext(conf) // val text= sc.textFile("/home/soyo/桌面/shell编程测试/1.txt") val text= sc.textFile("/home/soyo/下载/Hadoop+Spark+Hbase/all2.csv") //text.foreach(println) val wordcount= text.flatMap(line=>line.split(",")).map(word=>(word,1)) .reduceByKey((a,b)=>a+b) wordcount.collect().foreach(println) // wordcount.saveAsTextFile("/home/soyo/桌面/shell编程测试/1-1-1.txt") println("单独文件中各个数的统计个数") // wordcount.map(_._2).foreach(println) println("获取统计的最大数") // wordcount.map(_._2).saveAsTextFile("/home/soyo/下载/Hadoop+Spark+Hbase/77.txt") println(wordcount.map(_._2).max()) println("对获取到的数降序排列") wordcount.map(_._2).sortBy(x=>x,false).foreach(println) //false:降序 true:升序 println("转变为key-value形式") wordcount.map(_._2).map(num=>(num,1)).reduceByKey((a,b)=>a+b).foreach(println) println("对key-value按key再排序,获得结果表示:假设文件中'soyo5'总共出现10次,可文件'soyo1'也出现10次,最后整个排序获得的是(10,2)10次的共出现2次") wordcount.map(_._2).map(num=>(num,1)).reduceByKey((a,b)=>a+b).sortByKey().foreach(println) } }
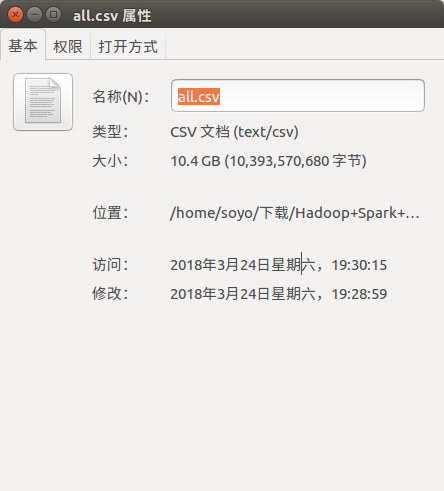
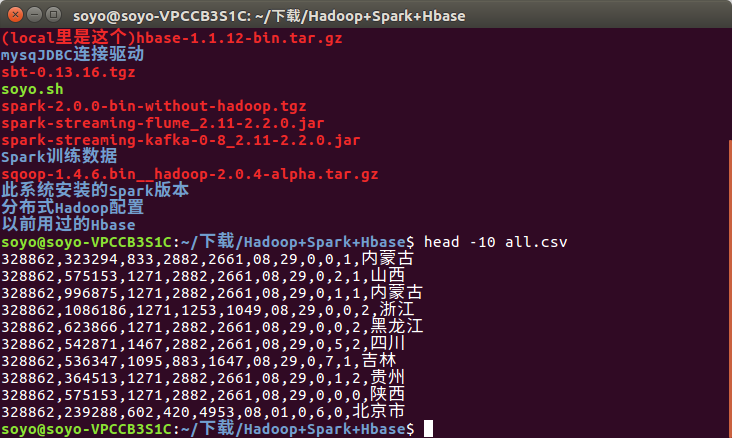
数据内容:
Spark 保存的文件是这样的:
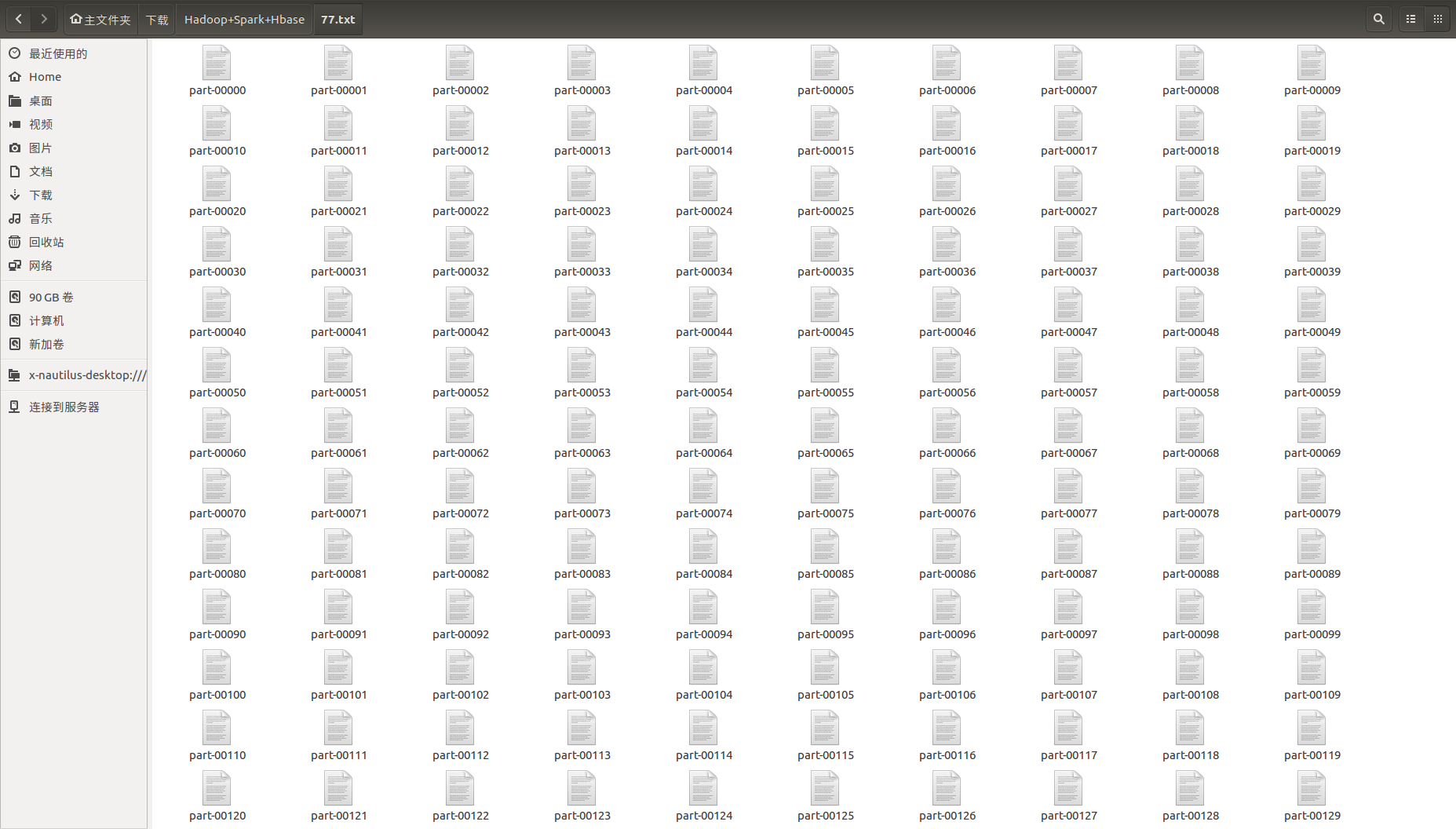
这里可以用一个脚本将这么多的文件进行合并:
#!/bin/bash
cat * >>soyoo.txt
结果太多只写一个:
获取统计的最大数
294887496 (数据中有一个元素出现了这么多次)