shuffle过程
shuffle概念
shuffle的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。而在MapReduce中,shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理。其在MapReduce中所处的工作阶段是map输出后到reduce接收前,具体可以分为map端和reduce端前后两个部分。在shuffle之前,也就是在map阶段,MapReduce会对要处理的数据进行分片(split)操作,为每一个分片分配一个MapTask任务。接下来map()函数会对每一个分片中的每一行数据进行处理得到键值对(key,value),其中key为偏移量,value为一行的内容。此时得到的键值对又叫做“中间结果”。此后便进入shuffle阶段,由此可以看出shuffle阶段的作用是处理“中间结果”。
此处应该想一下,为什么需要shuffle,它的作用是什么?
在了解shuffle的具体流程之前,应先对以下两个概念有所了解:
block块(物理划分)
block是HDFS中的基本存储单位,hadoop1.x默认大小为64M而hadoop2.x默认块大小为128M。文件上传到HDFS,就要划分数据成块,这里的划分属于物理的划分(实现机制也就是设置一个read方法,每次限制最多读128M的数据后调用write进行写入到hdfs),块的大小可通过 dfs.block.size配置。block采用冗余机制保证数据的安全:默认为3份,可通过dfs.replication配置。注意:当更改块大小的配置后,新上传的文件的块大小为新配置的值,以前上传的文件的块大小为以前的配置值。
split分片(逻辑划分)
Hadoop中split划分属于逻辑上的划分,目的只是为了让map task更好地获取数据。split是通过hadoop中的InputFormat接口中的getSplit()方法得到的。那么,split的大小具体怎么得到呢?
首先介绍几个数据量:
totalSize:整个mapreduce job输入文件的总大小。
numSplits:来自job.getNumMapTasks(),即在job启动时用户利用org.apache.hadoop.mapred. JobConf. setNumMapTasks(int n)设置的值,从方法的名称上看,是用于设置map的个数。但是,最终map的个数也就是split的个数并不一定取用户设置的这个值,用户设置的map个数值只是给最终的map个数一个提示,只是一个影响因素,而不是决定因素。
goalSize:totalSize/numSplits,即期望的split的大小,也就是每个mapper处理多少的数据。但也仅仅是期望。
minSize:split的最小值,该值可由两个途径设置:
1.通过子类重写方法protected void setMinSplitSize(long minSplitSize)进行设置。一般情况为1,特殊情况除外
2.通过配置文件中的mapred.min.split.size进行设置
最终取两者中的最大值!
split计算公式:finalSplitSize=max(minSize,min(goalSize,blockSize))
shuffle流程概括
因为频繁的磁盘I/O操作会严重的降低效率,因此“中间结果”不会立马写入磁盘,而是优先存储到map节点的“环形内存缓冲区”,在写入前进行分区(partition),也就是对于每个键值对来说,都增加了一个partition属性值,然后连同键值对一起序列化成字节数组写入到缓冲区(缓冲区采用的就是字节数组,默认大小为100M)。当写入的数据量达到预先设置的阙值后(mapreduce.map.io.sort.spill.percent,默认0.80,或者80%)便会启动溢写出线程将缓冲区中的那部分数据溢出写(spill)到磁盘的临时文件中,并在写入前根据key进行排序(sort)和合并(combine,可选操作)。溢出写过程按轮询方式将缓冲区中的内容写到mapreduce.cluster.local.dir属性指定的目录中。当整个map任务完成溢出写后,会对磁盘中这个map任务产生的所有临时文件(spill文件)进行归并(merge)操作生成最终的正式输出文件,此时的归并是将所有spill文件中的相同partition合并到一起,并对各个partition中的数据再进行一次排序(sort),生成key和对应的value-list,文件归并时,如果溢写文件数量超过参数min.num.spills.for.combine的值(默认为3)时,可以再次进行合并。至此,map端shuffle过程结束,接下来等待reduce task来拉取数据。对于reduce端的shuffle过程来说,reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge最后合并成一个分区相同的大文件,然后对这个文件中的键值对按照key进行sort排序,排好序之后紧接着进行分组,分组完成后才将整个文件交给reduce task处理。
纠正:分区好像是发生在溢出写过程之前,也就是当满足溢出写条件时,首先进行分区,然后分区内排序,并且选择性的combine,最后写出到磁盘。
下图是shuffle的官方流程图:
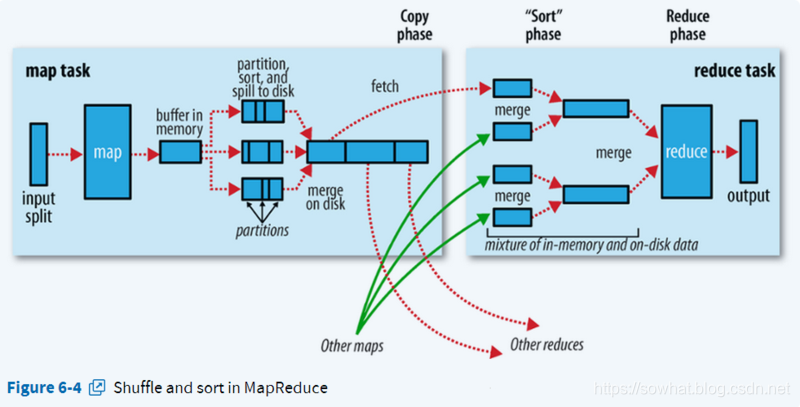
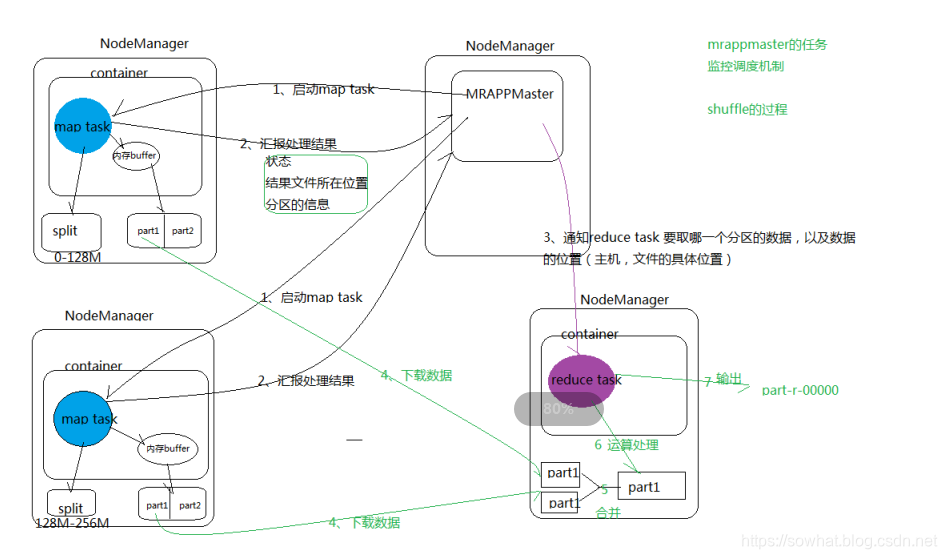
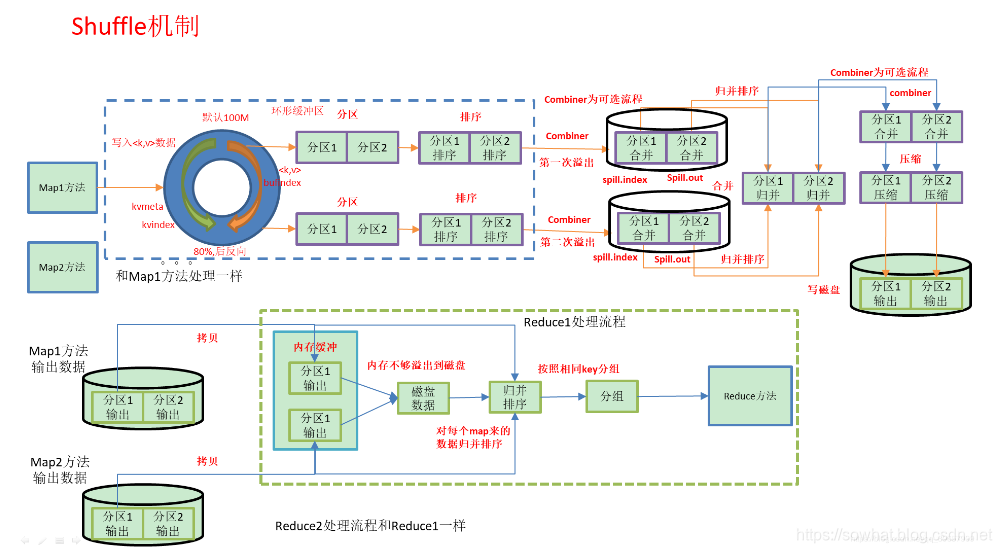
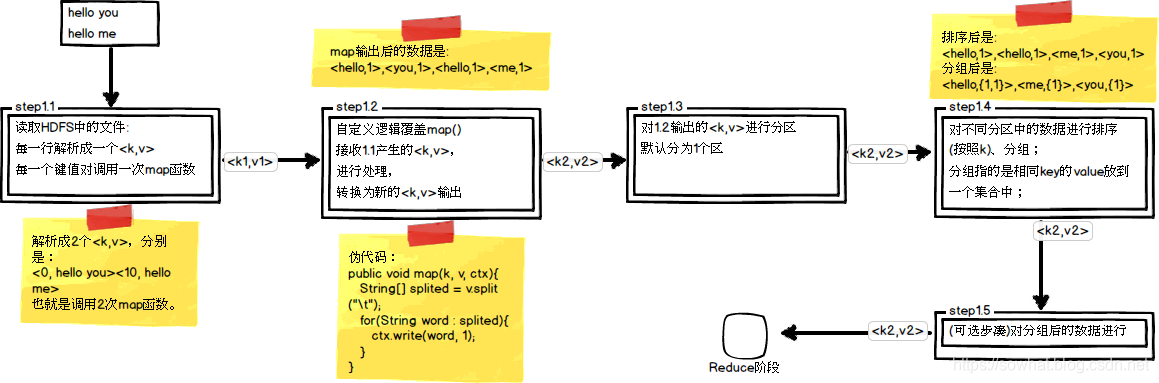
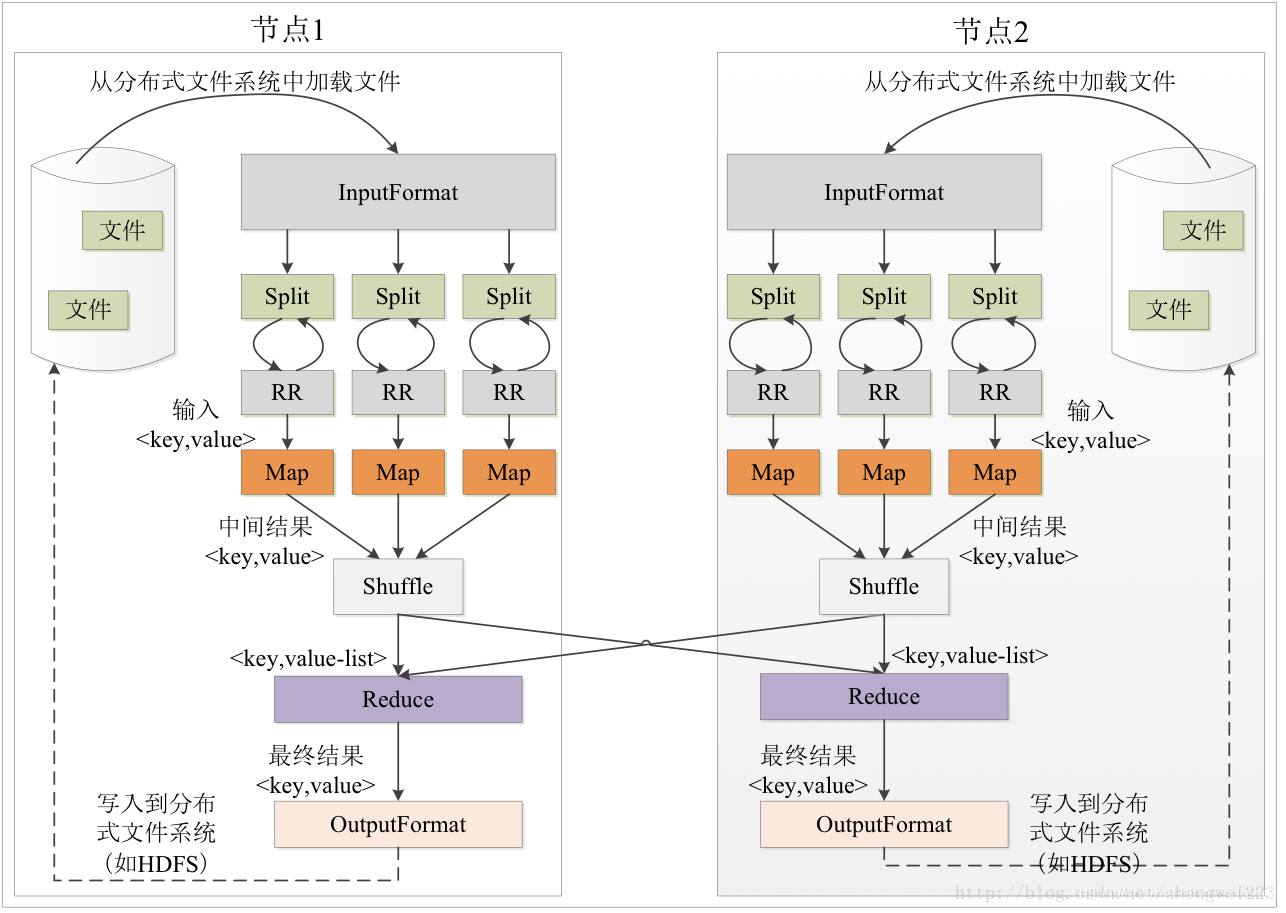
shuffle详细流程
Map端shuffle
分区Partition
在将map()函数处理后得到的(key,value)对写入到缓冲区之前,需要先进行分区操作,这样就能把map任务处理的结果发送给指定的reducer去执行,从而达到负载均衡,避免数据倾斜。MapReduce提供默认的分区类(HashPartitioner),其核心代码如下:
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
getPartition()方法有三个参数,前两个指的是mapper任务输出的键值对,而第三个参数指的是设置的reduce任务的数量,默认值为1。因为任何整数与1相除的余数肯定是0。也就是说默认的getPartition()方法的返回值总是0,也就是Mapper任务的输出默认总是送给同一个Reducer任务,最终只能输出到一个文件中。如果想要让mapper输出的结果给多个reducer处理,那么只需要写一个类,让其继承Partitioner类,并重写getPartition() 方法,让其针对不同情况返回不同数值即可。并在最后通过job设置指定分区类和reducer任务数量即可。
写入环形内存缓冲区
因为频繁的磁盘I/O操作会严重的降低效率,因此“中间结果”不会立马写入磁盘,而是优先存储到map节点的“环形内存缓冲区”,并做一些预排序以提高效率,当写入的数据量达到预先设置的阙值后便会执行一次I/O操作将数据写入到磁盘。每个map任务都会分配一个环形内存缓冲区,用于存储map任务输出的键值对(默认大小100MB,mapreduce.task.io.sort.mb调整)以及对应的partition,被缓冲的(key,value)对已经被序列化(为了写入磁盘)。
执行溢写出
一旦缓冲区内容达到阈值(mapreduce.map.io.sort.spill.percent,默认0.80,或者80%),就会会锁定这80%的内存,并在每个分区中对其中的键值对按键进行sort排序,具体是将数据按照partition和key两个关键字进行排序,排序结果为缓冲区内的数据按照partition为单位聚集在一起,同一个partition内的数据按照key有序。排序完成后会创建一个溢出写文件(临时文件),然后开启一个后台线程把这部分数据以一个临时文件的方式溢出写(spill)到本地磁盘中(如果客户端自定义了Combiner(相当于map阶段的reduce),则会在分区排序后到溢写出前自动调用combiner,将相同的key的value相加,这样的好处就是减少溢写到磁盘的数据量。这个过程叫“合并”)。剩余的20%的内存在此期间可以继续写入map输出的键值对。溢出写过程按轮询方式将缓冲区中的内容写到mapreduce.cluster.local.dir属性指定的目录中。
合并Combiner
如果指定了Combiner,可能在两个地方被调用:
1.当为作业设置Combiner类后,缓存溢出线程将缓存存放到磁盘时,就会调用;
2.缓存溢出的数量超过mapreduce.map.combine.minspills(默认3)时,在缓存溢出文件合并的时候会调用
合并(Combine)和归并(Merge)的区别:
两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,如果归并,会得到<“a”,<1,1>>
特殊情况:当数据量很小,达不到缓冲区阙值时,怎么处理?
对于这种情况,目前看到有两种不一样的说法:
①不会有写临时文件到磁盘的操作,也不会有后面的合并。
②最终也会以临时文件的形式存储到本地磁盘
至于真实情况是怎么样的,我还不清楚。。。
归并merge
当一个map task处理的数据很大,以至于超过缓冲区内存时,就会生成多个spill文件。此时就需要对同一个map任务产生的多个spill文件进行归并生成最终的一个已分区且已排序的大文件。配置属性mapreduce.task.io.sort.factor控制着一次最多能合并多少流,默认值是10。这个过程包括排序(135 跟 246 排序为123456 )和合并(可选),归并得到的文件内键值对有可能拥有相同的key,这个过程如果client设置过Combiner,也会合并相同的key值的键值对(根据上面提到的combine的调用时机可知)。
溢出写文件归并完毕后,Map将删除所有的临时溢出写文件,并告知NodeManager任务已完成,只要其中一个MapTask完成,ReduceTask就开始复制它的输出(Copy阶段分区输出文件通过http的方式提供给reducer)
压缩
写磁盘时压缩map端的输出,因为这样会让写磁盘的速度更快,节约磁盘空间,并减少传给reducer的数据量。默认情况下,输出是不压缩的(将mapreduce.map.output.compress设置为true即可启动)
Reduce端shuffle
结合下面这张图可以直观感受reduce端的shuffle过程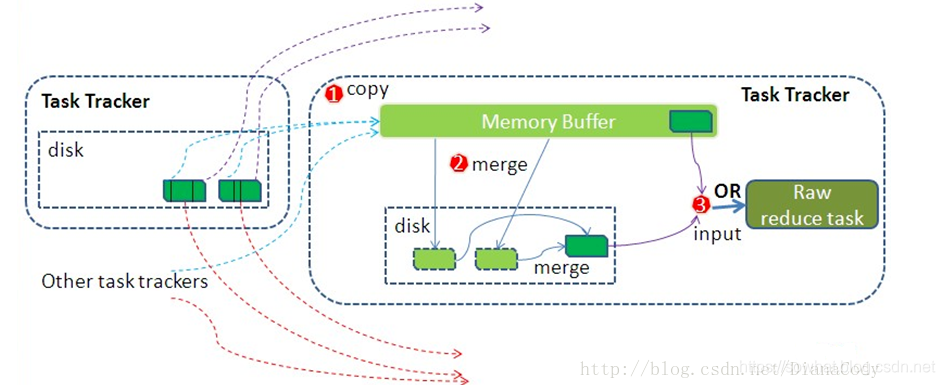
复制copy
Reduce进程启动一些数据copy线程,通过HTTP方式请求MapTask所在的NodeManager以获取输出文件。
NodeManager需要为分区文件运行reduce任务。并且reduce任务需要集群上若干个map任务的map输出作为其特殊的分区文件。而每个map任务的完成时间可能不同,因此只要有一个任务完成,reduce任务就开始复制其输出。提前copy
reduce任务有少量复制线程,因此能够并行取得map输出。默认线程数为5,但这个默认值可以通过mapreduce.reduce.shuffle.parallelcopies属性进行设置。
Reducer如何知道自己应该处理哪些数据呢?
因为Map端进行partition的时候,实际上就相当于指定了每个Reducer要处理的数据(partition就对应了Reducer),所以Reducer在拷贝数据的时候只需拷贝与自己对应的partition中的数据即可。每个Reducer会处理一个或者多个partition。
reducer如何知道要从哪台机器上去的map输出呢?
map任务完成后,它们会使用心跳机制通知它们的application master(MRAppMaster)、因此对于指定作业,application master知道map输出和主机位置之间的映射关系。reducer中的一个线程定期询问master以便获取map输出主机的位置。知道获得所有输出位置。
归并merge
Copy 过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比 map 端的更为灵活,它基于 JVM 的 heap size 设置,因为 Shuffle 阶段 Reducer 不运行,所以应该把绝大部分的内存都给 Shuffle 用。
Copy过来的数据会先放入内存缓冲区中,如果内存缓冲区中能放得下这次数据的话就直接把数据写到内存中,即内存到内存merge。Reduce要向每个Map去拖取数据,在内存中每个Map对应一块数据,当内存缓存区中存储的Map数据占用空间达到一定程度的时候,开始启动内存中merge,把内存中的数据merge输出到磁盘上一个文件中,即内存到磁盘merge。与map端的溢写类似,在将buffer中多个map输出合并写入磁盘之前,如果设置了Combiner,则会化简压缩合并的map输出。Reduce的内存缓冲区可通过mapred.job.shuffle.input.buffer.percent配置,默认是JVM的heap size的70%。内存到磁盘merge的启动门限可以通过mapred.job.shuffle.merge.percent配置,默认是66%。
当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件(如果拖取的所有map数据总量都没有内存缓冲区,则数据就只存在于内存中),这时开始执行合并操作,即磁盘到磁盘merge,Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的sort过程就是这个合并的过程,采取的排序方法跟map阶段不同,因为每个map端传过来的数据是排好序的,因此众多排好序的map输出文件在reduce端进行合并时采用的是归并排序,针对键进行归并排序。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。最终Reduce shuffle过程会输出一个整体有序的数据块。
reduce
当一个reduce任务完成全部的复制和排序后,就会针对已根据键排好序的Key构造对应的Value迭代器。这时就要用到分组,默认的根据键分组,自定义的可是使用 job.setGroupingComparatorClass()方法设置分组函数类。对于默认分组来说,只要这个比较器比较的两个Key相同,它们就属于同一组,它们的 Value就会放在一个Value迭代器,而这个迭代器的Key使用属于同一个组的所有Key的第一个Key。
在reduce阶段,reduce()方法的输入是所有的Key和它的Value迭代器。此阶段的输出直接写到输出文件系统,一般为HDFS。如果采用HDFS,由于NodeManager也运行数据节点,所以第一个块副本将被写到本地磁盘。
1、当reduce将所有的map上对应自己partition的数据下载完成后,reducetask真正进入reduce函数的计算阶段。由于reduce计算时同样是需要内存作为buffer,可以用mapreduce.reduce.input.buffer.percent(default 0.0)(源代码MergeManagerImpl.java:674行)来设置reduce的缓存。
这个参数默认情况下为0,也就是说,reduce是全部从磁盘开始读处理数据。如果这个参数大于0,那么就会有一定量的数据被缓存在内存并输送给reduce,当reduce计算逻辑消耗内存很小时,可以分一部分内存用来缓存数据,可以提升计算的速度。所以默认情况下都是从磁盘读取数据,如果内存足够大的话,务必设置该参数让reduce直接从缓存读数据,这样做就有点Spark Cache的感觉。
2、Reduce在这个阶段,框架为已分组的输入数据中的每个键值对对调用一次 reduce(WritableComparable,Iterator, OutputCollector, Reporter)方法。Reduce任务的输出通常是通过调用 OutputCollector.collect(WritableComparable,Writable)写入文件系统的。
关于分组的深入理解,请看这篇文章:https://mp.csdn.net/postedit/81778972
MapReduce组件全貌
前面的学习 主要是在梳理跟学习数据的处理流程,其实还应该了解下数据的输入InputFormat 跟输出OutputFormat,
实际输入:hdfs(默认,而且还是TextInputFormat),数据库,文件,ftp,网页,网络端口等。
书籍输出:往数据库、HBase、ftp、hdfs(默认是往hdfs写,而且还是TextOutputFormat)文件。
Hadoop具体demo之倒排索引
整体思想就是爬去若干网页,然后对网页进行分词,然后统计不同词在网页中出现的次数。比如
a.txt
hello kitty
hello job
hello name
b.txt
kitty node
kitty log
c.txt
hello node
log what
结果
hello a.txt-3 c.txt-1
kitty a.txt-1 b.txt-2
…
分为两步
- 读取若干文件 数据分割为 单词-文件 次数
- 对上一步结果 处理未 单词 文件-次数
package myii;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import cn.itcast.hadoop.mr.flowsort.SortMR;
import cn.itcast.hadoop.mr.flowsort.SortMR.SortMapper;
import cn.itcast.hadoop.mr.flowsort.SortMR.SortReducer;
import cn.itcast.hadoop.mr.flowsum.FlowBean;
/**
* 倒排索引步骤一job
* @author ljj
* 将不同文件 切分为 key:字符-->文件名 val:出现次数
*/
public class InverseIndexStepOne {
public static class StepOneMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//拿到一行数据
String line = value.toString();
//切分出各个单词
String[] fields = StringUtils.split(line, " ");
//获取这一行数据所在的文件切片
FileSplit inputSplit = (FileSplit) context.getInputSplit();
//从文件切片中获取文件名
String fileName = inputSplit.getPath().getName();
for(String field:fields){
//封装kv输出 , k : hello-->a.txt v: 1
context.write(new Text(field+"-->"+fileName), new LongWritable(1));
}
}
}
public static class StepOneReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
// <hello-->a.txt,{1,1,1....}>
@Override
protected void reduce(Text key, Iterable<LongWritable> values,Context context)
throws IOException, InterruptedException {
long counter = 0;
for(LongWritable value:values){
counter += value.get();
}
context.write(key, new LongWritable(counter));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(InverseIndexStepOne.class);
job.setMapperClass(StepOneMapper.class);
job.setReducerClass(StepOneReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
//检查一下参数所指定的输出路径是否存在,如果已存在,先删除
Path output = new Path(args[1]);
FileSystem fs = FileSystem.get(conf);
if(fs.exists(output)){
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
System.exit(job.waitForCompletion(true)?0:1);
}
}
=======
package myii;
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Reducer;
import cn.itcast.hadoop.mr.ii.InverseIndexStepOne.StepOneMapper;
import cn.itcast.hadoop.mr.ii.InverseIndexStepOne.StepOneReducer;
public class InverseIndexStepTwo
{
public static class StepTwoMapper extends Mapper<LongWritable, Text, Text, Text>
{
//k: 行起始偏移量 v: {hello-->a.txt 3}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
{
String line = value.toString();
String[] fields = StringUtils.split(line, " ");
String[] wordAndfileName = StringUtils.split(fields[0], "-->");
String word = wordAndfileName[0];
String fileName = wordAndfileName[1];
long count = Long.parseLong(fields[1]);
context.write(new Text(word), new Text(fileName + "-->" + count));
//map输出的结果是这个形式 : <hello,a.txt-->3>
}
}
public static class StepTwoReducer extends Reducer<Text, Text, Text, Text>
{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException
{
//拿到的数据 <hello,{a.txt-->3,b.txt-->2,c.txt-->1}>
String result = "";
for (Text value : values)
{
result += value + " ";
}
context.write(key, new Text(result));
//输出的结果就是 k: hello v: a.txt-->3 b.txt-->2 c.txt-->1
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
// 先构造job_one
Job job_one = Job.getInstance(conf);
job_one.setJarByClass(InverseIndexStepTwo.class);
job_one.setMapperClass(StepOneMapper.class);
job_one.setReducerClass(StepOneReducer.class);
//......
//构造job_two
Job job_tow = Job.getInstance(conf);
job_tow.setJarByClass(InverseIndexStepTwo.class);
job_tow.setMapperClass(StepTwoMapper.class);
job_tow.setReducerClass(StepTwoReducer.class);
job_tow.setOutputKeyClass(Text.class);
job_tow.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job_tow, new Path(args[0]));
//检查一下参数所指定的输出路径是否存在,如果已存在,先删除
Path output = new Path(args[1]);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(output))
{
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job_tow, output);
// 先提交job_one执行 可在配置文件中 先配置多个任务 然后 在 后面依次调用任务
boolean one_result = job_one.waitForCompletion(true);
if (one_result)
{
System.exit(job_tow.waitForCompletion(true) ? 0 : 1);
}
}
}
参考文章:
shuffle简单通俗讲解
倒排索引
shuffle
shuffle讲解
shuffle图解
split具体讲解
https://blog.csdn.net/ASN_forever/article/details/81233547
https://blog.csdn.net/u014374284/article/details/49205885
https://blog.csdn.net/lb812913059/article/details/79899644
https://blog.csdn.net/lb812913059/article/details/79899798
https://www.cnblogs.com/DianaCody/p/5425658.html