Hive
- Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 QL ,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
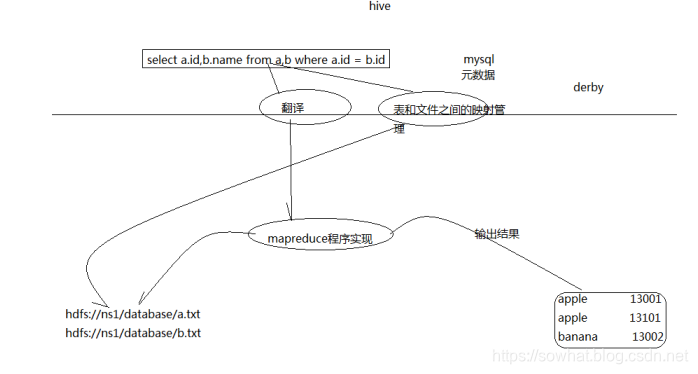
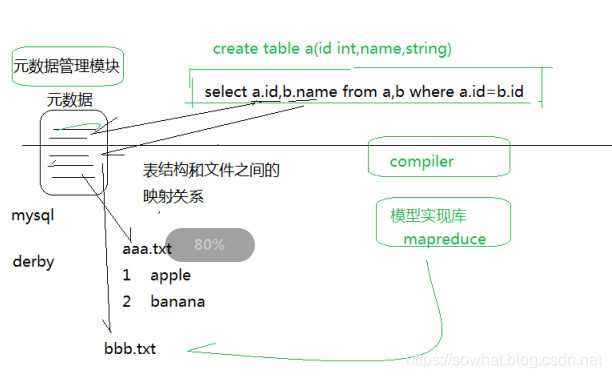
- Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。Hive的表其实就是HDFS的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
Hive 体系
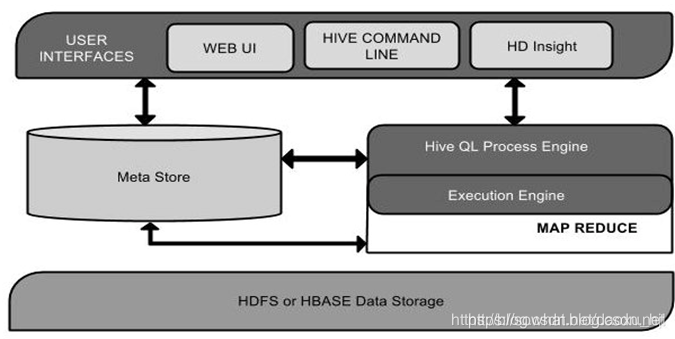
- 用户接口主要有三个:CLI,JDBC/ODBC和 WebUI
CLI,即Shell命令行
JDBC/ODBC 是 Hive 的Java,与使用传统数据库JDBC的方式类似
WebGUI是通过浏览器访问 Hive
- Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
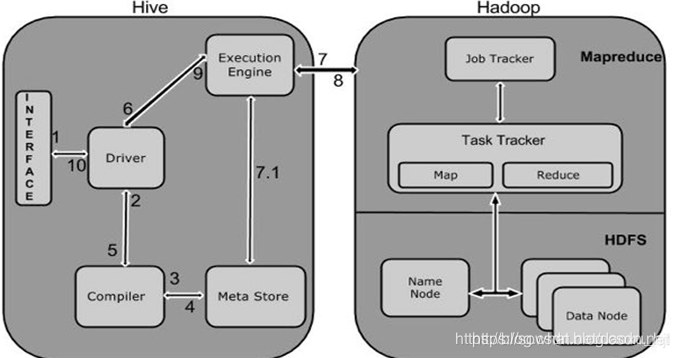
- 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行
- Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务)
Hive 执行原理


安装模式
metastore是hive元数据的集中存放地

相关文档资料: http://hive.apache.org/
官网下载: http://hive.apache.org/downloads.html
前置说明
- 安装并启动Hadoop 集群:使用hadoop-2.9.0
- hive只需要在 NameNode 节点安装即可,可以不在datanode节点安装
- 以下 在本地独立模式的基础上安装: 建议选择远程模式安装mysql,步骤一样,修改url为其他节点名称、赋权语句指定%接收任何主机连接
下载 解压 配置环境变量
https://mirrors.tuna.tsinghua.edu.cn/apache/hive/
选择稳定版:apache-hive-2.3.4-bin.tar.gz
主namenode节点hdp-01: mkdir -p /opt/hive
通过FileZilla上传tgz安装包至hdp-01的hive目录
解压:cd /opt/hive && tar -zxvf apache-hive-2.3.4-bin.tar.gz
vim ~/.bash_profile
#末尾添加环境变量
export HIVE_HOME=/opt/hive/apache-hive-2.3.4-bin
export PATH=$HIVE_HOME/bin:$PATH
#立即生效
source ~/.bash_profile
Hive配置Hadoop HDFS
cd $HIVE_HOME/conf
cp hive-default.xml.template hive-site.xml
vim hive-site.xml
#修改 属性:hive.metastore.warehouse.dir 为 /data/hive/warehouse
#修改 属性:hive.exec.scratchdir 为 /data/hive/tmp
创建目录配置权限
#创建warehouse目录
hdfs dfs -mkdir -p /data/hive/warehouse
hdfs dfs -chmod 777 /data/hive/warehouse
#创建tmp目录
hdfs dfs -mkdir -p /data/hive/tmp
hdfs dfs -chmod 777 /data/hive/tmp
#验证
hdfs dfs -ls /data/hive/

修改 hive-site.xml中的临时目录
- 将文件中的所有 ${system:java.io.tmpdir}替换成/opt/hive/apache-hive-2.3.4-bin/tmp
sed -i 's/${system:java.io.tmpdir}//opt/hive/apache-hive-2.3.4-bin/tmp/g' hive-site.xml
- 将文件中所有的${system:user.name}替换为hadoop
sed -i 's/${system:user.name}/hadoop/g' hive-site.xml
- 创建上面定义的目录:
mkdir -p /opt/hive/apache-hive-2.3.4-bin/tmp
安装配置mysql
MySQL 安装
sudo yum install -y mysql
当然也可以自己手动下载包安装
上传mysql驱动包并移动到$HIVE_HOME/lib
下载一个mysql-connector-java驱动包 mysql-connector-java-5.1.44.tar.gz,并上传解压
tar -zxvf mysql-connector-java-5.1.44.tar.gz
cp mysql-connector-java-5.1.44-bin.jar $HIVE_HOME/lib
修改hive-site.xml数据库相关配置
修改属性值:
javax.jdo.option.ConnectionURL
javax.jdo.option.ConnectionDriverName
javax.jdo.option.ConnectionUserName
javax.jdo.option.ConnectionPassword
hive.metastore.schema.verification
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hdp-01:3306/hive?createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
复制hive-env.sh模板并配置
cp $HIVE_HOME/conf/hive-env.sh.template $HIVE_HOME/conf/hive-env.sh
export HADOOP_HOME=/opt/hadoop/hadoop-2.9.0
export HIVE_CONF_DIR=/opt/hive/apache-hive-2.3.4-bin/conf
export HIVE_AUX_JARS_PATH=/opt/hive/apache-hive-2.3.4-bin/lib
启动MySQL
sudo service mysqld start
sudo chkconfig mysqld on
sudo chkconfig --list | grep mysql
创建MySQL账号并授权
mysql
create user hive@'hdp-01' identified by 'hive';
grant all privileges on *.* to 'hive'@'hdp-01' with grant option;
flush privileges;
此处使用本地独立模式安装的mysql,若使用远程模式授权语句可改为:grant all privileges on . to ‘hive’@‘hdp-01’ with grant option;
初始化hive 数据库
schematool -initSchema -dbType mysql

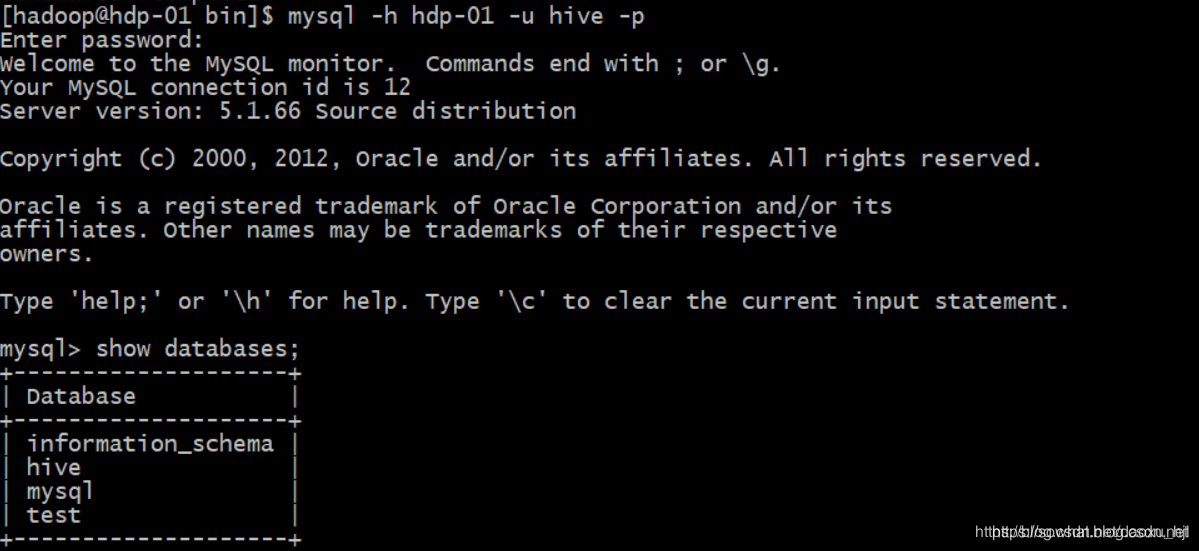
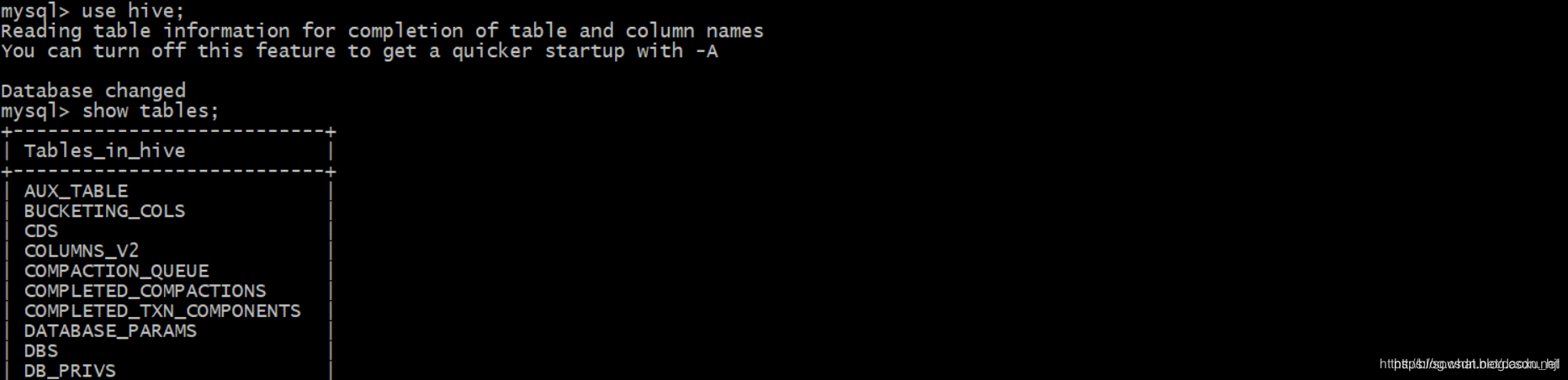
启动hive
nohup hive --service metastore &
nohup hive --service hiveserver2 &
hive
Hive的运行模式即任务的执行环境
分为本地与集群两种
我们可以通过mapred.job.tracker 来指明
设置方式:
hive > SET mapred.job.tracker=local
Hive启动方式
- hive 命令行模式,直接输入#/hive/bin/hive的执行程序,或者输入 #hive --service cli
- hive web界面的 (端口号9999) 启动方式
#hive --service hwi &
用于通过浏览器来访问hive
http://hadoop0:9999/hwi/
- hive 远程服务 (端口号10000) 启动方式
#hive --service hiveserver &
Hive跟传统数据库
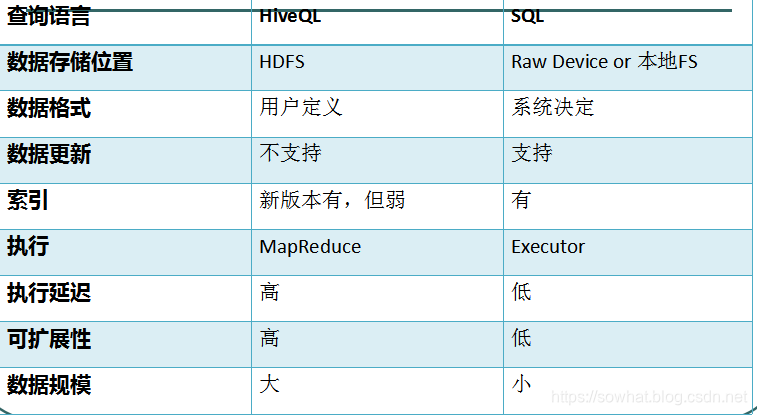
PS:Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、” ”、”x001″)、行分隔符 (”
”)以及读取文件数据的方法(Hive 中默认有三个文件格式 TextFile,SequenceFile 以及 RCFile)。由于在加载数据的过程中,不需要从用户数据格式到 Hive 定义的数据格式的转换,因此,Hive 在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
Hive 数据类型
基本数据类型
tinyint/smallint/int/bigint
float/double
boolean
string
复杂数据类型
Array/Map/Struct
没有date/datetime
Hive存储格式
Hive的数据存储基于Hadoop HDFS
Hive没有专门的数据存储格式
存储结构主要包括:数据库、文件、表、视图
Hive默认可以直接加载文本文件(TextFile),还支持sequence file 、RC file
创建表时,指定Hive数据的列分隔符与行分隔符,Hive即可解析数据
DataBase
类似传统数据库的DataBase默认数据库"default",使用#hive命令后,不使用hive>use <数据库名>,系统默认的数据库。可以显式使用hive> use default;
表的格式
Table 内部表

Partition 分区表




Bucket Table 桶表

External Table 外部表

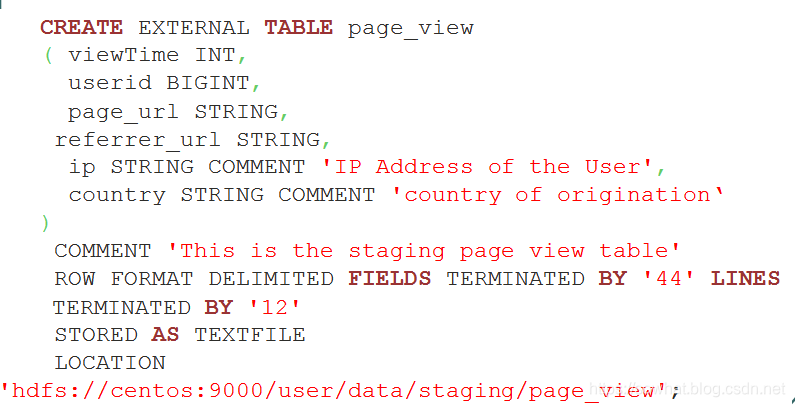
创建表格
CREATE TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT ‘IP Address of the User’)
COMMENT ‘This is the page view table’
PARTITIONED BY(dt STRING, country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘�01’
STORED AS SEQUENCEFILE; TEXTFILE
指定数据格式
create table tab_ip_seq(id int,name string,ip string,country string)
row format delimited
fields terminated by ‘,’
stored as sequencefile;
insert overwrite table tab_ip_seq select * from tab_ext;
创建表格导入本地文件到数据库
create table tab_ip(id int,name string,ip string,country string)
row format delimited
fields terminated by ‘,’
stored as textfile;
load data local inpath ‘/home/hadoop/ip.txt’ into table tab_ext;
创建external 表
一般创建内部表有HDFS统一管理数据的存储路径,但有时候业务数据在别的HDFS路径中则需要 指定数据源(也叫外部表)
CREATE EXTERNAL TABLE tab_ip_ext(id int, name string,
ip STRING,
country STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’
STORED AS TEXTFILE
LOCATION ‘/external/hive’;
###CTAS 用于创建一些临时表存储中间结果
CREATE TABLE tab_ip_ctas
AS
SELECT id new_id, name new_name, ip new_ip,country new_country
FROM tab_ip_ext
SORT BY new_id;
//insert from select 用于向临时表中追加中间结果数据
create table tab_ip_like like tab_ip;
insert overwrite table tab_ip_like select * from tab_ip;
//分区
create table tab_ip_part(id int,name string,ip string,country string)
partitioned by (part_flag string)
row format delimited fields terminated by ‘,’;
// 导入数据指定分区
load data local inpath ‘/home/hadoop/ip.txt’ overwrite into table tab_ip_part
partition(part_flag=‘part1’);
// 导入数据指定分区
load data local inpath ‘/home/hadoop/ip_part2.txt’ overwrite into table tab_ip_part
partition(part_flag=‘part2’);
select * from tab_ip_part;
select * from tab_ip_part where part_flag=‘part2’;
select count(*) from tab_ip_part where part_flag=‘part2’;
alter table tab_ip change id id_alter string;
ALTER TABLE tab_cts ADD PARTITION (partCol = ‘dt’) location ‘/external/hive/dt’;
show partitions tab_ip_part;
//write to hdfs
insert overwrite local directory ‘/home/hadoop/hivetemp/test.txt’ select * from tab_ip_part where part_flag=‘part1’;
insert overwrite directory ‘/hiveout.txt’ select * from tab_ip_part where part_flag=‘part1’;
//array
create table tab_array(a array,b array)
row format delimited
fields terminated by ‘ ’
collection items terminated by ‘,’;
示例数据
tobenbrone,laihama,woshishui 13866987898,13287654321
abc,iloveyou,itcast 13866987898,13287654321
select a[0] from tab_array;
select * from tab_array where array_contains(b,‘word’);
insert into table tab_array select array(0),array(name,ip) from tab_ext t;
//map
create table tab_map(name string,info map<string,string>)
row format delimited
fields terminated by ‘ ’
collection items terminated by ‘;’
map keys terminated by ‘:’;
示例数据:
fengjie age:18;size:36A;addr:usa
furong age:28;size:39C;addr:beijing;weight:180KG
load data local inpath ‘/home/hadoop/hivetemp/tab_map.txt’ overwrite into table tab_map;
insert into table tab_map select name,map(‘name’,name,‘ip’,ip) from tab_ext;
//struct
create table tab_struct(name string,info structage:int,tel:string,addr:string)
row format delimited
fields terminated by ‘ ’
collection items terminated by ‘,’
load data local inpath ‘/home/hadoop/hivetemp/tab_st.txt’ overwrite into table tab_struct;
insert into table tab_struct select name,named_struct(‘age’,id,‘tel’,name,‘addr’,country) from tab_ext;
//CLUSTER 比分区更细 分桶
create table tab_ip_cluster(id int,name string,ip string,country string)
clustered by(id) into 3 buckets;
load data local inpath ‘/home/hadoop/ip.txt’ overwrite into table tab_ip_cluster;
set hive.enforce.bucketing=true;
insert into table tab_ip_cluster select * from tab_ip;
select * from tab_ip_cluster tablesample(bucket 2 out of 3 on id);
//cli shell
hive -S -e ‘select country,count(*) from tab_ext’ > /home/hadoop/hivetemp/e.txt
有了这种执行机制,就使得我们可以利用脚本语言(bash shell,python)进行hql语句的批量执行
select * from tab_ext sort by id desc limit 5;
select a.ip,b.book from tab_ext a join tab_ip_book b on(a.name=b.name);
//UDF
select if(id=1,first,no-first),name from tab_ext;
hive>add jar /home/hadoop/myudf.jar;
hive>CREATE TEMPORARY FUNCTION my_lower AS ‘org.dht.Lower’;
select my_upper(name) from tab_ext;
## 自定义函数 UDF

显示所有函数:
hive> show functions;
查看函数用法:
hive> describe function substr;
```java
package mybigdata;
import java.util.HashMap;
import org.apache.hadoop.hive.ql.exec.UDF;
// 导入hive Jar 包 然后 继承UDF 自定义实现 evaluate 函数即可 可以自定义输入跟输出 数据的个数跟类型
public class PhoneNbrToArea extends UDF{
private static HashMap<String, String> areaMap = new HashMap<>();
static {
areaMap.put("1388", "beijing");
areaMap.put("1399", "tianjin");
areaMap.put("1366", "nanjing");
}
//一定要用public修饰才能被hive调用
public String evaluate(String pnb) {
String result = areaMap.get(pnb.substring(0,4))==null? (pnb+" huoxing"):(pnb+" "+areaMap.get(pnb.substring(0,4)));
return result;
}
}
- 将文件打包到HDFS中或者本地
- hive语句中导入该jar包就可用这个函数了
add jar hdfs://cluster/user/kg/hive_udf/kg_graphx-1.0-SNAPSHOT.jar;
create temporary function jsonutil as 'com.credithc.rc.kg.udf.JsonUdf';
create temporary function jsonlist as 'com.credithc.rc.kg.udf.JsonUdaf';
====
hive> add jar /home/hadoop/hiveareaudf/jar
hive> create temporary function getarea as 'mybigdata.PhoneNbrToArea';
hive> select getarea(phoneNB),upflow,downflow from t_flow;