| 这个作业属于哪个课程 | 软工-2018级计算机1班 |
|---|---|
| 这个作业要求在哪里 | 202103226-1 编程作业 |
| 这个作业的目标 | 学习使用GITHUB或者码云 |
| 学号 | 20188390 |
| 这个作业的目标 | 学习使用Git、完成本次编程作业 |
| 参考文献 | eclipse中使用GIT或者码云(eclipse最新版自带GIT插件) 正则表达式的使用 |
| 参考文献 | 《码出高效_阿里巴巴Java开发手册》 |
目录
正文
Gitee项目地址
PSP表格
| PSP+D3+A+A1:D10 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 10 |
| • Estimate | • 估计这个任务需要多少时间 | 785 | 990 |
| Development | 开发 | 480 | 660 |
| • Analysis | • 需求分析 (包括学习新技术) | 30 | 30 |
| • Design Spec | • 生成设计文档 | 20 | 25 |
| • Design Review | • 设计复审 | 20 | 30 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 10 | 15 |
| • Design | • 具体设计 | 20 | 25 |
| • Coding | • 具体编码 | 360 | 480 |
| • Code Review | • 代码复审 | 60 | 70 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 30 | 35 |
| Reporting | 报告 | 20 | 25 |
| • Test Repor | • 测试报告 | 60 | 45 |
| • Size Measurement | • 计算工作量 | 5 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 15 | 10 |
| 合计 | 785 | 990 |
解题思路描述
- 要解决的要求
输入参数为输入文本文件路径和输出文本文件路径。
读取输入文本内容。
统计文件的字符数。
统计文件的单词总数。
统计文件的有效行数(不为空白,存在非空白字符即可)。
统计文件中各单词的出现次数(出现频率top10)。
将统计结果输出到output.txt(将上述项目输出到output.txt)。
- 解决的方法
字节流读取文件数据转为字符
设置编码格式为utf-8
正则表达式匹配单词、匹配换行符,开始符号等非空白字符
字典序排序冲浪得到答案,在室友帮助下理解
代码规范
计算模块接口的设计与实现过程
- Lib类
- 正则表达式
Matcher m = Pattern.compile("(^|
)\s*\S+").matcher(text);
- 记录行数
while (m.find())
{
lines ++;
}
return lines;
正则表达式匹配非空白字符是这次编程作业的重要内容,是基座!但是对于正则表达式的语法还是有些不熟,花了很久查资料和室友的讲解才完成!
- countWord()
记录单词数量并返回记录单词数量的变量的值 - setWordMapFeca()
(^|[^A-Za-z0-9])([a-zA-Z]{4}[a-zA-Z0-9]*)
又是一个重要的正则表达式,这里用来判断单词,与下面的while循环相关联,做到记录同一个单词的出现频率,以便筛选Top10。
- HashMap类的学习
*Java中的HashMap散列存储
* 它是一种数据结构,它允许我们存储对象并在我们知道key的情况下在恒定时间O(1)中检索它。
* 散列函数用于连接HashMap中的键和值。通过调用HashMap的put(key,value)方法存储对象,并通过调用get(key)方法检索对象。
* 一般使用的是String作为可以,这是由于String实现了自己的hashCode 和方法,只有这样保证计算出来的索引最终会在同一个桶位置。
* 特点
* HashMap 允许 null作为key , 线程不安全, 查询key时间复杂度 O(1)
- WordCount类
对运行速度的要求
有室友在做前进的标兵,使用最快的运行算法
FileInputStream in = new FileInputStream(file); /* size 为字符串的长度,一次性读入数据*/
int size = in.available();
byte[] buffer = new byte[size];
in.read(buffer);
in.close();
this.text = new String(buffer,"UTF-8");
- main
主函数起始入口
计算模块接口部分的性能改进
文件读取是这段程序里耗时最长的!改进了读取算法就加快了运行速度!
作业完成较晚,直接采用室友告诉我的一次性读入所有文本数据,现阶段运行最快(在以后的学习中继续寻找更快的方式)
计算模块部分单元测试展示
- 统计文件的字符数(对应输出第一行):只需要统计Ascii码,汉字不需考虑空格,水平制表符,换行符,均算字符

- 结果
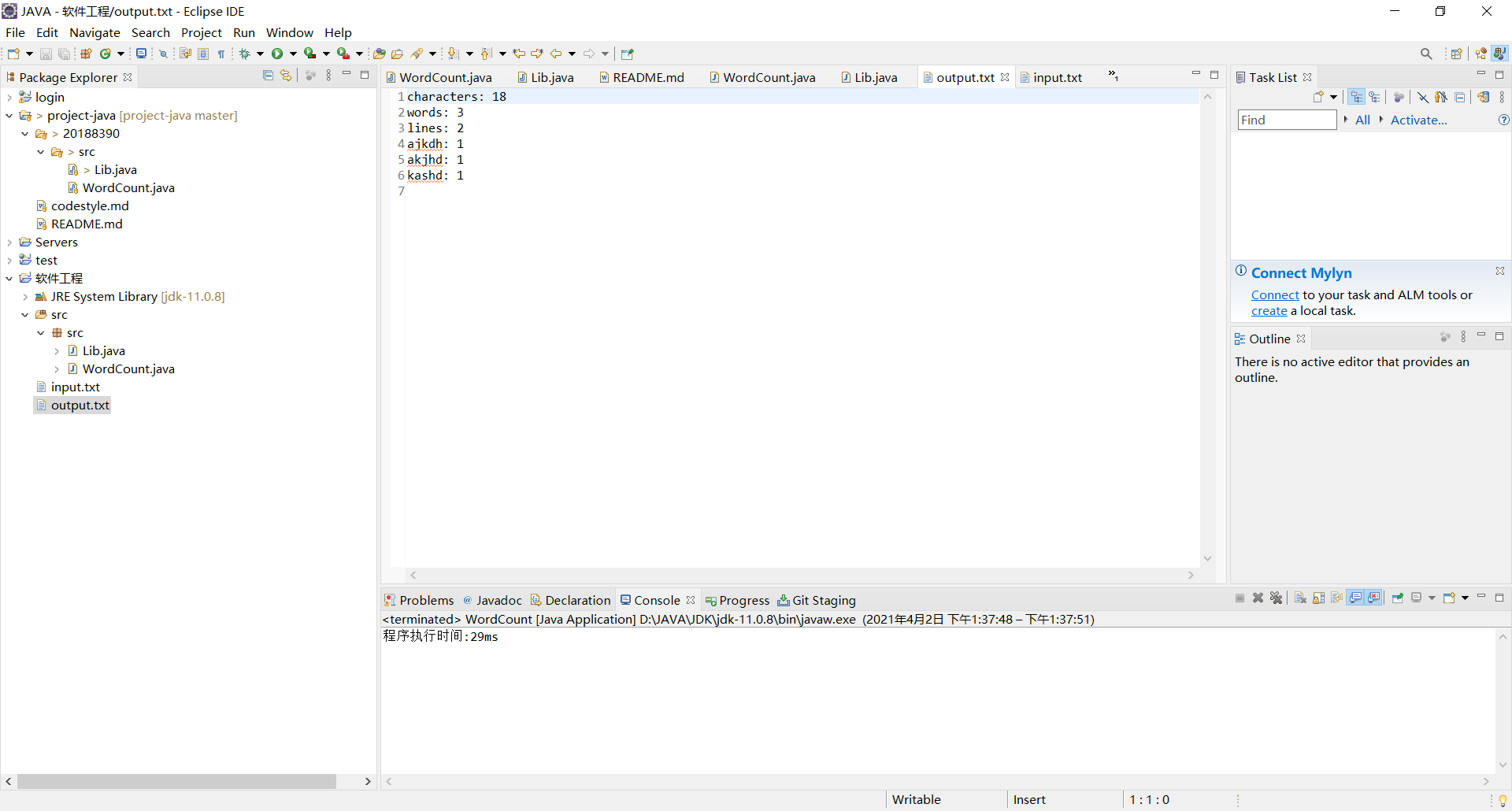
- 统计文件的单词总数(对应输出第二行),单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 结果
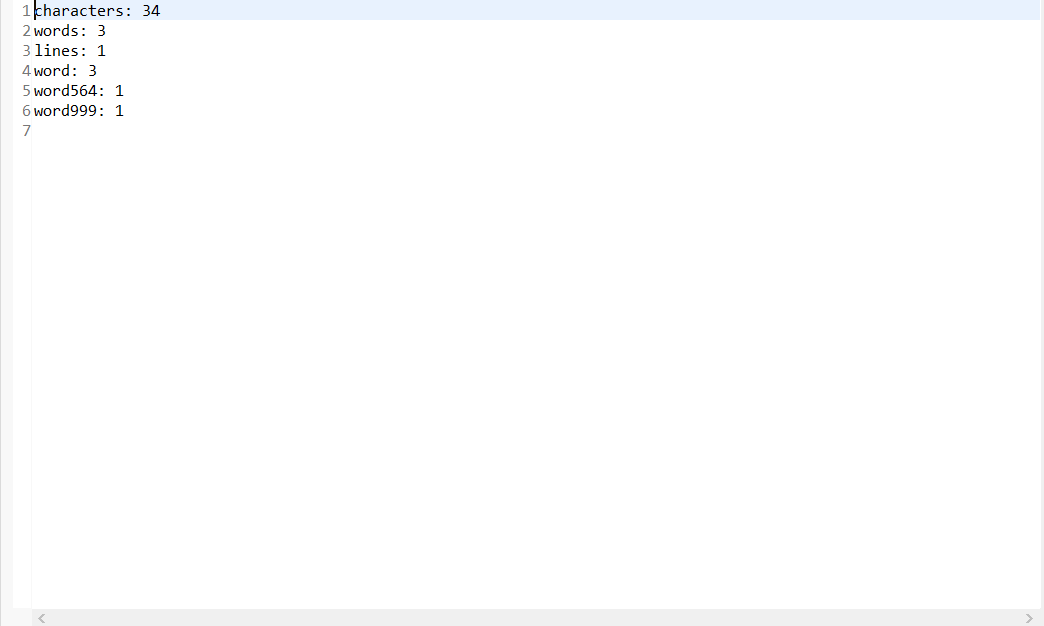
- 统计文件的有效行数(对应输出第三行):任何包含非空白字符的行,都需要统计。

- 结果

- 统计文件中各单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
输出的单词统一为小写格式

- 结果

计算模块部分异常处理说明

无法找到指定的文件,与我之前搞错了寻找文件路径的方法有关!
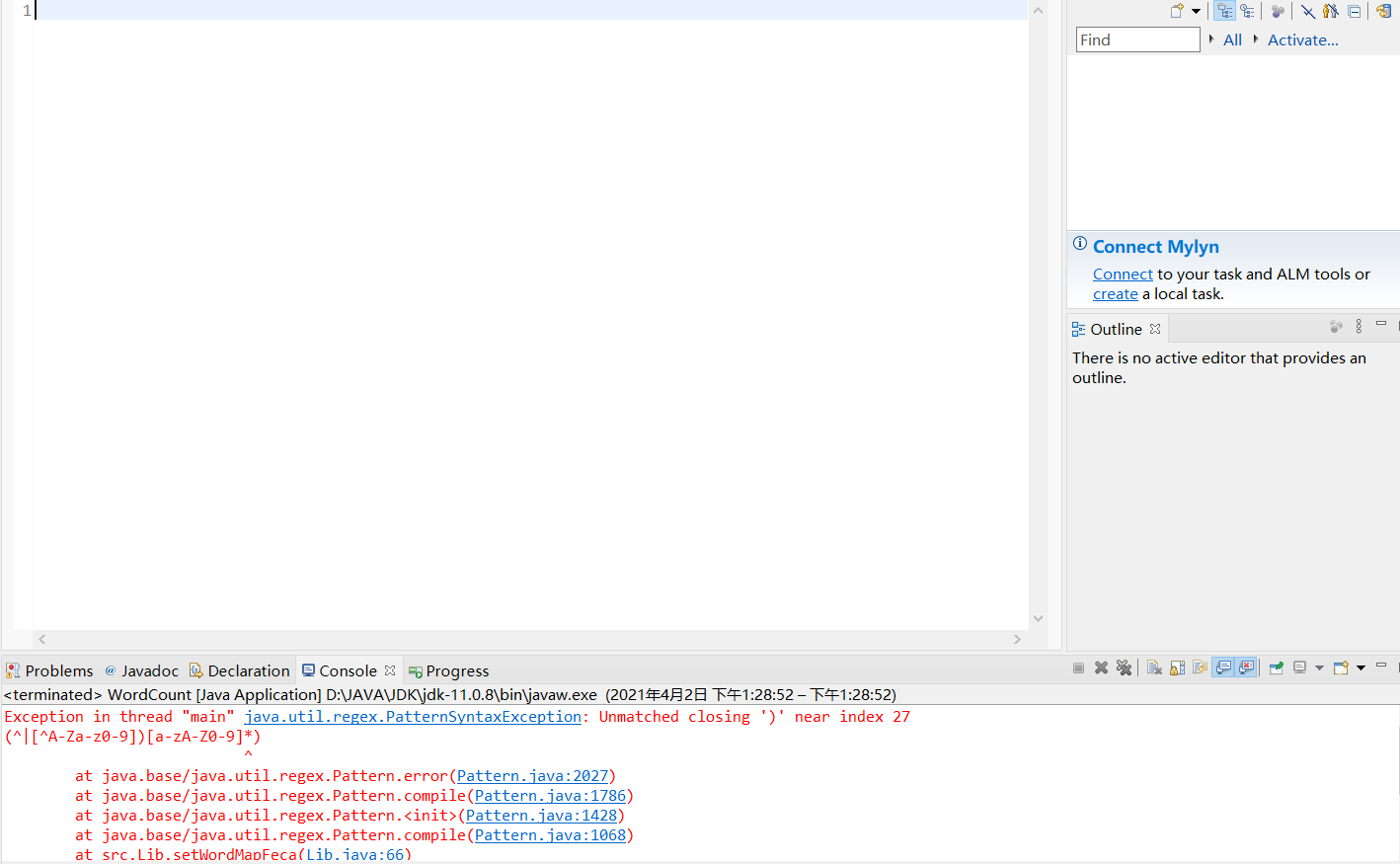
正则表达式错误,无法记录单词
心路历程与收获!
-
收获
- 学习了如何使用Git
- 开发项目之前的分析操作很重要,能帮你少走一些弯路
- PHP表格能规范你的开发过程,能够在一定程度上督促你完成你的计划
- 正则表达式的语法需要继续学习,此语法很重要,有关于文本的方面都需要用到,加深学习
- 自己的思路是局限的,要集思广益,不能在遇到困难时按自己的想法一条路走到黑,如果自己不能解决的事,说不定其他人就有很简洁的办法可以做到你想要的效果
- 代码的规范能够在发现错误后很快的找到并解决这个错误,大大提高了你的时间利用率
-
心路历程
- 刚刚看到作业要求的时候我是很懵的,这是第一次看到这么长的作业要求,这也侧面反映出了我的信息提取能力不足,而后慢慢的仔细阅读要求时发现就是一个统计单词的数量以及单词本身时,觉得不是很难就留在最后几天才开始编写,编写的途中遇到了各种各样的困难,比如怎么把一行中的单词分开一个个的单独提取出来,这里我就遇到了正则表达式知识不足的大问题,花了很久的时间才弄出来;还有如何提取词频top10的单词时,整个人都在抓瞎,经室友的提醒我找到了HashMap类,了解了他的运作原理,懂了原理是一回事,实践使用又是另外一回事,梳理不清其中的逻辑关系,挣扎了很久还是没有解决,只能是使用他人的代码来完成作业。
- 经此一役,我认识到自己还是很菜,这么些天没有编写代码,基础的东西丢了一大块,还是得在以后多多实践。
生命不息,学习不止
这次作业,大多都是寻求他人的帮助,虽然之后我能理解这些代码的意义,但是这样的理解根本没有多大用处,还是得自己能想到这个功能我该用怎样的代码去实现它!
加油!!!