一,kafka概述
Kafka是一个高吞吐量的、持久性的、分布式发布/订阅消息系统。
它主要用于处理活跃的数据(登录、浏览、点击、分享、喜欢等用户行为产生的数据)。
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。
Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker--服务器节点。
无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性
三大特点:
高吞吐量:可以满足每秒百万级别消息的生产和消费——生产消费。需要硬件支撑
持久性:有一套完善的消息存储机制,确保数据的高效安全的持久化——中间存储。
分布式:基于分布式的扩展和容错机制;Kafka的数据都会复制到几台服务器上。当某一台故障失效时,生产者和消费者转而使用其它的机器——整体健壮性。
二,kafka核心组件
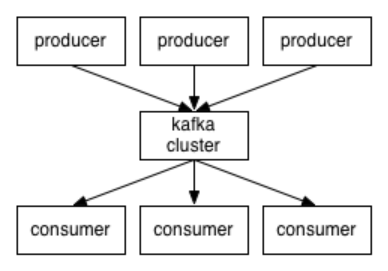
Topic: Kafka处理的消息的不同分类。
Broker:消息代理,Kafka集群中的一个kafka服务节点称为一个broker,主要存储消息数据。存在硬盘中。每个topic都是有分区的。
Partition:Topic物理上的分组,一个topic在broker中被分为1个或者多个partition,分区在创建topic的时候指定。
Message:消息,是通信的基本单位,每个消息都属于一个partition> Kafka服务相关
Producer:消息和数据的生产者,向Kafka的一个topic发布消息。
Consumer:消息和数据的消费者,定于topic并处理其发布的消息。
Zookeeper:协调kafka的正常运行。
三,kafka集群部署
1,下载,解压安装包。关闭防火墙。
2,修改配置文件。
//全局唯一编号,不能重复 broker.id=0 //监听连接的端口,producer或consumer将在此端口建立连接 port=9092 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 ocket.send.buffer.bytes=102400 log.dirs=/home/kafka-logs num.partitions=2 zookeeper.connect=localhost:2181 zookeeper.connection.timeout.ms=6000
3,分发安装包
scp -r /export/servers/kafka_2.11-0.8.2.2 kafka02:/export/servers 然后分别在各机器上创建软连 cd /export/servers/ ln -s kafka_2.11-0.8.2.2 kafka
4,再次修改配置文件
依次修改各服务器上配置文件的的broker.id,分别是0,1,2不得重复。
5,启动集群
依次在各节点上启动kafka
bin/kafka-server-start.sh config/server.properties
四,kafka常用操作的命令
查看当前服务器中的所有topic bin/kafka-topics.sh --list --zookeeper server1:2181 创建topic bin/kafka-topics.sh --create --zookeeper server1:2181 --replication-factor 1 --partitions 1 --topic test replication-factor 备份个数 删除topic,慎用,只会删除zookeeper中的元数据,消息文件须手动删除 sh bin/kafka-topics.sh --delete --zookeeper server1:2181 --topic test 需要server.properties中设置delete.topic.enable=true否则只是标记删除或者直接重启。 通过shell命令发送消息 kafka-console-producer.sh --broker-list server1:9092 --topic t 通过shell消费消息 sh bin/kafka-console-consumer.sh --zookeeper server1:2181 --from-beginning --topic t 查看消费位置 sh kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper zk01:2181 --group testGroup 查看某个Topic的详情 sh kafka-topics.sh --topic test --describe --zookeeper zk01:2181
五,通过java调用kafka
1,priduce代码
package com;
import java.util.Properties;
import java.util.Scanner;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
/**
* 模拟生产者发送消息,通过循环去发送消息给kafka
*
*
*/
public class producer {
private static KafkaProducer<String, String> producer ;
@SuppressWarnings("resource")
public static void main(String[] args) {
Properties perties=new Properties();
//服務器地址
perties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "server1:9092");
//客户端的名字 随便起 的
perties.put(ProducerConfig.CLIENT_ID_CONFIG, "DemoProducer");
perties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
perties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
producer=new KafkaProducer<String, String>(perties);
int num=0;
while(true){
String data=new Scanner(System.in).nextLine();
producer.send(new ProducerRecord<String, String>("test1",num+"", data+num), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
// TODO Auto-generated method stub
if(metadata!=null)
System.out.println(metadata.toString());
}
});
num++;
}
}
}
2,consumer代码
package com;
import java.util.Collections;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
/**kafka-topics.sh --list --zookeeper server1:2181
*
*
*/
public class consumer {
private static KafkaConsumer<String, String> consumer;
public static void main(String[] args) {
Properties perties=new Properties();
//服務器地址
perties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"server1:9092");
perties.put(ConsumerConfig.GROUP_ID_CONFIG, "DemoConsumer");
perties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
perties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
perties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
perties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
perties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");
consumer=new KafkaConsumer<>(perties);
consumer.subscribe(Collections.singletonList("test1"));
while (true) {
ConsumerRecords<String, String> datas = consumer.poll(1000);
for(ConsumerRecord<String, String> data:datas) {
System.out.println(data.key()+"----"+data.value());
}
}
}
}
注意:代码中的topic 要在linux虚拟机中的存在,若没有则创建。