float和double都可以表示浮点类型,但是它们可以表示的数据类型范围和精度是不同的。下面的代码便演示了这两种数据类型在一些场景下的差别。
1 int a = 1219; 2 int b = 56; 3 __int64 c = 1503050028000; 4 int d = 1000; 5 float e = 0.883889; 6 7 8 __int64 r1 = c + __int64((a - b))*d / e; 9 10 __int64 r2 = __int64((a - b))*d / e; 11 12 __int64 r3 = c + r2;
这段代码运行后,结果是:
r1=1503051382784
r2=1315776
r3=1503051343776
这不科学,小学三年级的学生都知道这不对。
让我们来看看编译器是如何处理这段代码的吧。
执行完第8行代码前:

执行完第8行代码后:

我们看到,编译器使用了CVTSD2SS指令将__int64类型转换为了float类型。正是这一转换过程,导致了精度的丢失。数值从原来的1503050028000变成了1503050152687.
最终的执行结果:

我们看到,不仅c的值发生了变化,__int64((a - b))*d=1163000的值也发生了变化。只是这个变化比较小,对最终的结果影响不大而已。
解决办法1:将float转换为double
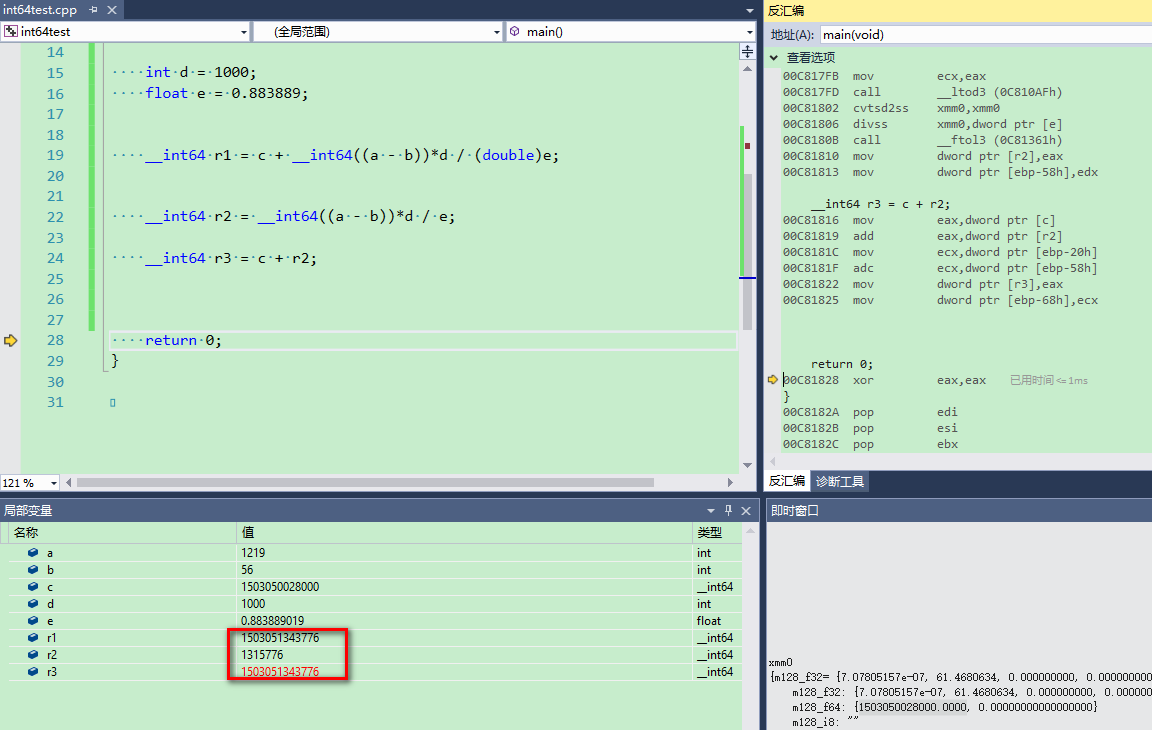
解决办法2:如同办法1,将算术运算分成多行,结果也正确。因为__int64并不会被转换为flloat从而丢失精度了。
所以,float和double的精度差别以及可表示的数值范围确实对数据的运算结果有着很大影响。
参考
https://stackoverflow.com/questions/5098558/float-vs-double-precision