Elastic Stack生态圈

- Logstash:数据处理管道,负责数据采集和转换,可以实时获取IP,排斥敏感字段,拓展插件多,安全等特性
- Beat:轻量数据采集器
- Kibana:数据可视化工具
- Elasticsearch:数据存储
- X-Pack:商业化套件,负责安全
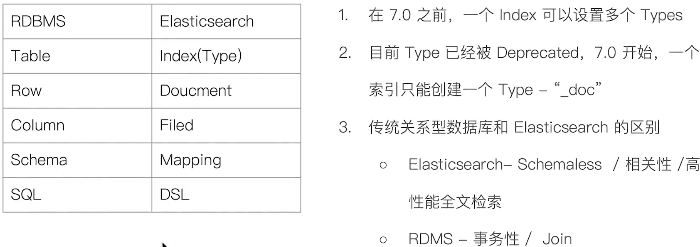
概念和数据库类比
运维维度,节点、分片
主要围绕两个概念:高可用和拓展性
高可用:简称 HA,是系统一种特征或者指标,体现如下两点:
- 服务可用性:允许部分节点停止服务,整体服务没有影响
- 数据可用性:允许部分节点丢失,最终不会丢失数据
拓展性:将原来节点和增量数据重新从 10 个节点分布到 100 个节点,应对数据的猛增;
节点:是一个ES实例,本质上就是一个java进程,一个机器上可以运行多个实例,但是生产环境建议一台机器上只运行一个ES实例;
节点类型
- Master-eligible Node 和 Master Node:Master Node 负责同步集群状态信息
- Data Node 和 Coordinating Node:数据节点,用于保存数据
- Hot & Warm Node:不同硬件配置的 Data Node,用来实现冷热数据节点架构,降低运维部署的成本
- Machine Learning Node:负责机器学习的节点
- Tribe Node:负责连接不同的集群。支持跨集群搜索 Cross Cluster Search
- master node:通过 node.master 配置,默认 true
- data node:通过 node.data 配置,默认 true
- ingest node:通过 node.ingest 配置,默认 true
- coordinating node:默认每个节点都是 coordinating 节点,设置其他类型全部为 false。
- machine learning:通过 node.ml 配置,默认 true,需要通过 x-pack 开启。
分片
主分片:用来解决数据水平扩展的问题
副本分片:用来备份数据,提高数据的高可用性。副本分片是主分片的拷贝
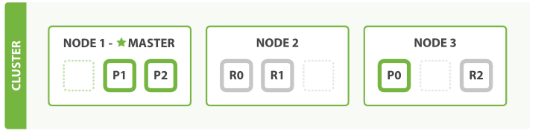
节点、索引、分片总结
- 一个节点,对应一个实例
- 一个节点,可以多个索引
- 一个索引,可以多个分片
- 一个分片,对应底层一个 lucene 分片
倒排索引
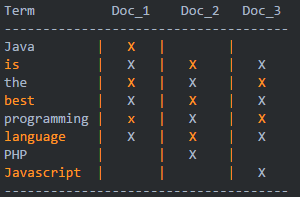
1、举例
1)正排索引

2)倒排索引

2、倒排索引核心组成
-
词条(Term):索引里面最小的存储和查询单元,对于英文来说是一个单词,对于中文来说一般指分词后的一个词。
-
词典(Term Dictionary):或字典,是词条 Term 的集合。搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
-
倒排表(Post list):一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过以及出现的位置。
每条记录称为一个倒排项(Posting)。倒排表记录的不单是文档编号,还存储了词频等信息。
-
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
词典和倒排表是 Lucene 中很重要的两种数据结构,是实现快速检索的重要基石。词典和倒排文件是分两部分存储的,词典在内存中而倒排文件存储在磁盘上。
举例:
-
Java is the best programming language.
-
PHP is the best programming language.
-
Javascript is the best programming language.