一,is 和==的区别
python中存在一个小数据池的概念
# a = 128 # print(id(a)) # a = "alex" # 这是第一次产生alex # b = "alex" # 这句话不会产生新的字符串
# print(id(a), id(b)) # a = "谦虚" # b = "谦虚" # lst = ["jj", 'jay',"谦虚"] # lst2 = ["jj", 'jay',"谦虚"] # # print(id(lst), id(lst2)) # 在python中一般的字符串都是会被缓存的. 为了节约内存 # a = "alex@wusir" # b = "alex@wusir" # print(id(a), id(b))
# a = [1,2,3] # b = a # c = b
# # 列表的创建 # print(c == a) # 判断的是值. # print(c is a) # 判断两个变量指向的是否是同一个对象
python中两个数据类型存在小数据池:
int范围: -5 ~ 256
str:
is 和== 有什么区别??
1,is 比较的是内存地址.
2,== 比较的是值
2. 复习编码
1. ASCII, 英文, 数字, 一些特殊符号 8bit 1byte
2. GBK, 国标码, 汉字. 16bit 2byte 必须兼容ASCII
3. UNICODE, 万国码, 32bit 4byte , 兼容ASCII
4. UTF-8 可变长度的万国码
英文: 8bit 1byte
欧洲: 16bit 2byte
汉字: 24bit 3byte
python2的版本. 默认使用ASCII
python3的版本. 默认使用unicode. 在计算的时候会非常方便
在网络传输和数据存储的时候. 换gbk, utf-8(90%)
编码(encode): unicode变成你需要的编码
编码之后的内容是字节(bytes类型)
s = "你好啊" # bs = s.encode("utf-8") # print(bs)
# ascii中的内容编码之后还是原来的内容 # 中文编码之后是x # bs = b'xe4xbbx8axe5xa4xa9xe6x99x9axe4xb8x8axe7xbaxa6xe4xb9x88?' # 用什么编码就要用什么解码 # s = bs.decode("utf-8") # print(s)
解码(decode): 把目标bytes转换成字符串
# gbk的一句话 bs = b'xc4xe3xb3xd4xc1xcbxc3xb4' # 想要发给别人. # 把这句话翻译成字符串 # s = bs.decode("gbk") # bbs = s.encode("utf-8") # print(bbs) # utf-8 a = [[11, 22, 33], [44, 55, 66]] b = [[77,88,99], [88,99,10]] f = zip(*a, *b) print(list(f))
三. 对之前的知识点进行补充.
1. str中的join方法. 把列表转换成字符串
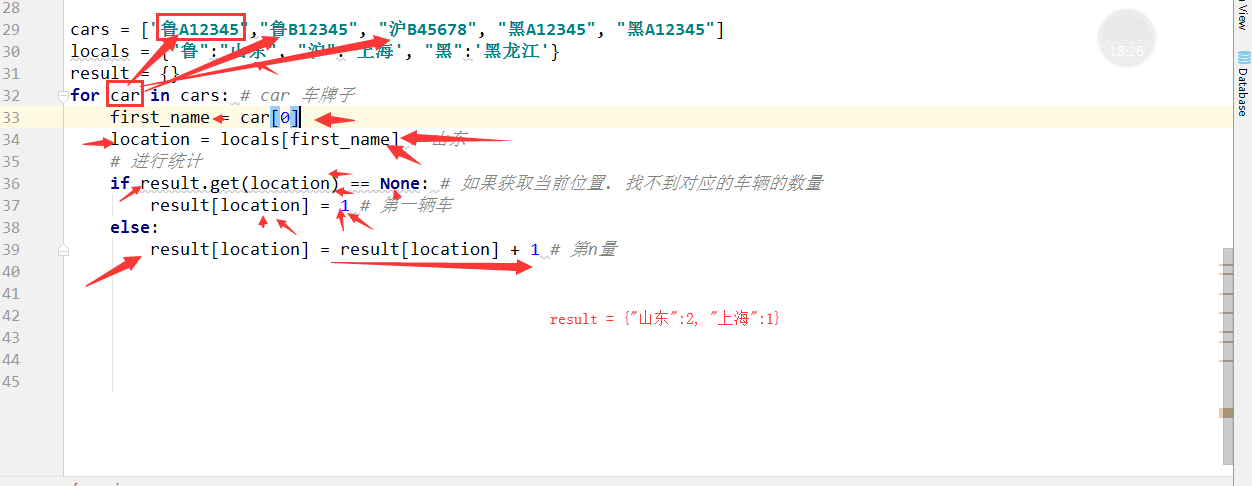
2. 列表和字典在循环的时候不能直接删除.
需要把要删除的内容记录在新列表中.
然后循环新列表.删除字典或列表
# s = "_".join("马化腾") # print(s) # # join(可迭代对象)
# lst = ["紫云", "大云", "玉溪", "紫钻","a","b"] # # lst.clear() # new_lst = [] # 准备要删除的信息 # for el in lst: # 有一个变量来记录当前循环的位置 # new_lst.append(el)
# # 循环新列表, 删除老列表 # for el in new_lst: # lst.remove(el) # # # 删除的时候, 发现. 剩余了一下内容. 原因是内部的索引在改变. # # 需要把要删除的内容记录下来. 然后循环这个记录. 删除原来的列表 # # print(lst) # print(new_lst) # lst = ["张国荣", '张铁林', '张国立', "张曼玉", "汪峰"] # # 删掉姓张的 # # 记录姓张的. # zhangs = [] # for el in lst: # if el.startswith("张"): # zhangs.append(el) # for el in zhangs: # lst.remove(el) # print(lst) # print(zhangs) # 字典 # dic = {"提莫":"冯提莫", "发姐":"陈一发儿", "55开":"卢本伟"} # # dic.clear() # lst = [] # for k in dic: # lst.append(k) # # for el in lst: # dic.pop(el) # print(dic) # 综上. 列表和字典都不能再循环的时候进行删除. 字典再循环的时候不允许改变大小
3. fromkeys()
1. 返回新字典. 对原字典没有影响
2. 后面的value.是多个key共享一个value
# dic = {"apple":"苹果", "banana":"香蕉"} # # 返回新字典. 和原来的没关系 # ret = dic.fromkeys("orange", "橘子") # 直接用字典去访问fromkeys不会对字典产生影响 # ret = dict.fromkeys("abc",["哈哈","呵呵", "吼吼"]) # fromkeys直接使用类名进行访问 # print(ret) a = ["哈哈","呵呵", "吼吼"] ret = dict.fromkeys("abc", a) # fromkeys直接使用类名进行访问 a.append("嘻嘻") print(ret)
四. set集合
特点 : 无序, 不重复, 元素必须可哈希(不可变)
作用 : 去重复,本身是可变的数据类型. 有增删改查操作.
frozenset()冻结的集合. 不可变的. 可哈希的
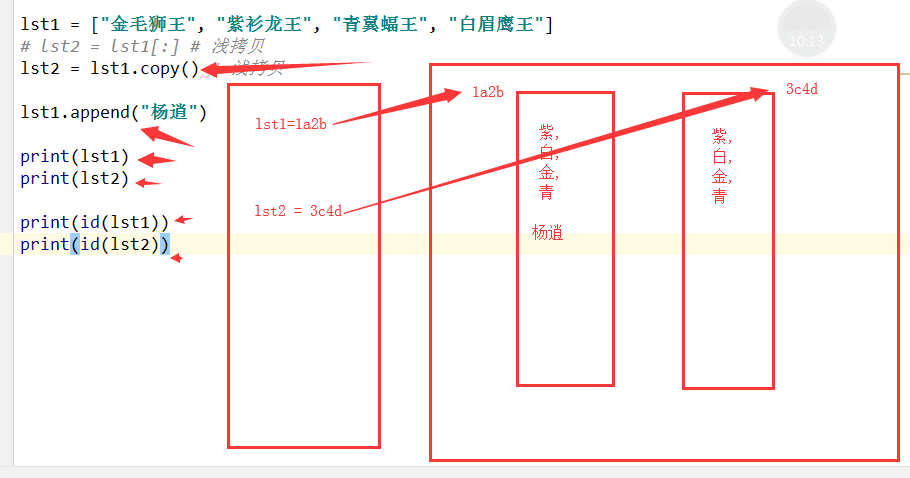
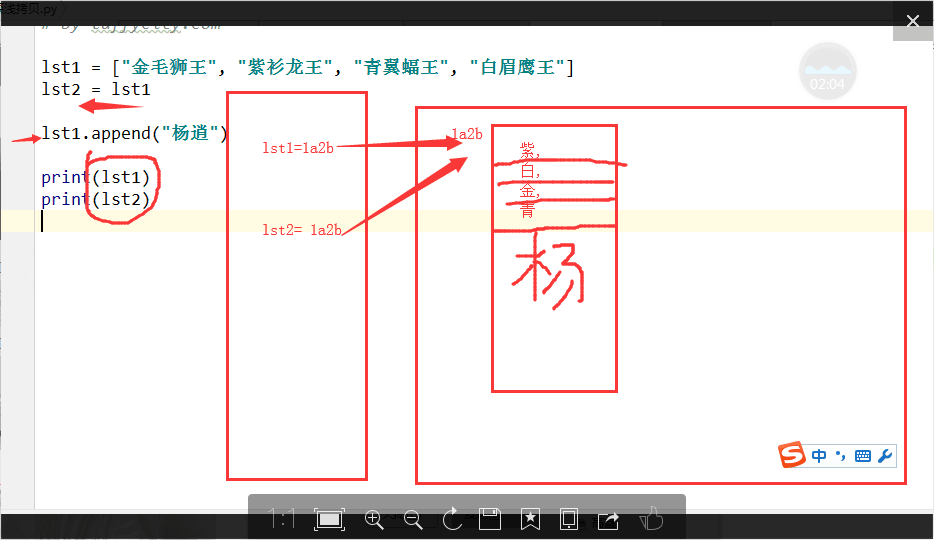
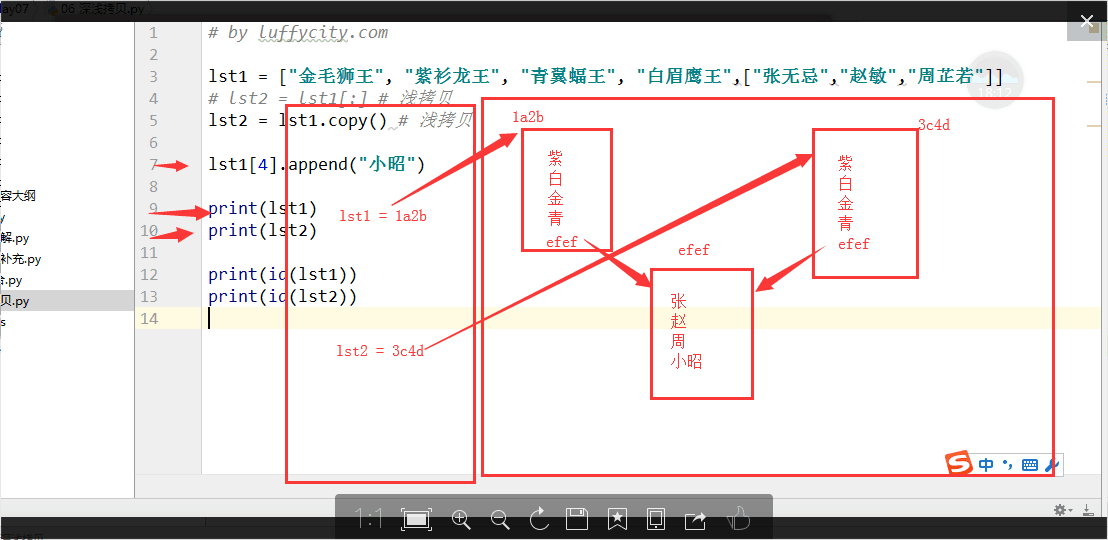
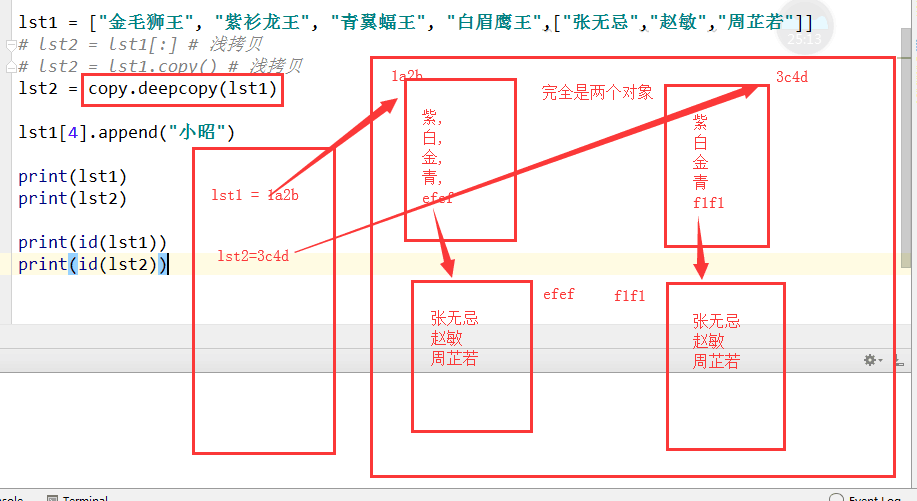
五. 深浅拷贝(难点)
集合中的元素必须是可哈希的. 不重复的. 可以去重. 哈希hash算法
1. 赋值. 没有创建新对象. 公用同一个对象
2. 浅拷贝. 拷贝第一层内容. [:]或copy()
3. 深拷贝. 拷贝所有内容. 包括内部的所有.
# by luffycity.com # s = {"周杰伦", "的老婆","叫昆凌", (1,2,3), "周杰伦"} # lst = [11,5,4,1,2,5,4,1,25,2,1,4,5,5] # s = set(lst) # 把列表转换成集合. 进行去重复 # lst = list(s) # 把集合转换回列表. # print(lst) # 集合本身是可变的数据类型, 不可哈希, 有增删改查操作 s = {"刘嘉玲", '关之琳', "王祖贤"} s.update("麻花藤") # 迭代更新 print(s)
拷贝就是拷贝,何来深浅之说?
Python中,对象的赋值,拷贝(深/浅拷贝)之间是有差异的,如果使用的时候不注意,就可能产生意外的结果
其实这个是由于共享内存导致的结果
拷贝:原则上就是把数据分离出来,复制其数据,并以后修改互不影响。
先看 一个非拷贝的例子
=赋值:数据完全共享(=赋值是在内存中指向同一个对象,如果是可变(mutable)类型,比如列表,修改其中一个,另一个必定改变
如果是不可变类型(immutable),比如字符串,修改了其中一个,另一个并不会变
)
l1 = [1,2,3,[11,22,33]] l2 = l1.copy() print(l2) #[1,2,3,[11,22,33]] l2[3][2]='aaa' print(l1) #[1, 2, 3, [11, 22, 'aaa']] print(l2) #[1, 2, 3, [11, 22, 'aaa']] l1[0]= 0 print(l1) #[0, 2, 3, [11, 22, 'aaa']] print(l2) #[1, 2, 3, [11, 22, 'aaa']] print(id(l1)==id(l2)) #Flase