一.什么是垃圾回收机制
-
垃圾回收机制(简称GC), python解释器自带的一种机制
-
它是一种动态存储管理技术,自动释放不再被程序引用的对象所占用的内存空间
二.为什么要有垃圾回收机制
- 程序的运行过程中会申请大量的内存空间
- 对于一些无用的空间如果不及时清理的话会导致内存溢出(不够用),程序就会崩溃
- 管理内存是非常复杂的事情,垃圾回收机制就把程序员从复杂的内存管理中解放出啦
三.垃圾回收机制的原理
1.引用计数
引用计数就是变量名与变量值的关联次数, 以此来跟踪和回收垃圾
- 直接引用
通过变量名直接引用
x = 18 #18被引用了一次,计数为1
y = x #18被引用加1次,计数为2
z = y #18被引用加1次,计数为3
print(id(x)) #140725488808736
print(id(y)) #140725488808736
print(id(z)) #140725488808736
- 间接引用
容器对其的引用都是间接
x = 18 #18被引用一次,计数为1
li = [1,2,x] #通过列表引用,计数加1,为2
dic = {'age': x} #通过字典引用, 计数加1,为3
print(id(x)) #140725486514976
print(id(li[2])) #140725486514976 列表引用,计数4
print(id(dic['age'])) #140725486514976 字典引用,计数5
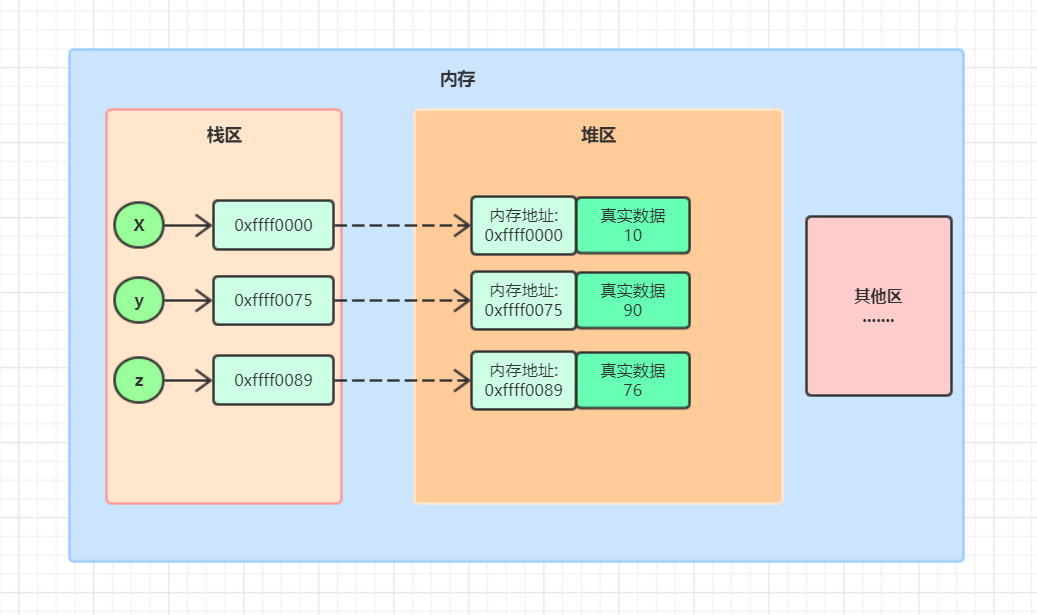
2.栈区 / 堆区
- 栈区 : 存放的是变量名与变量值的内存地址映射关系
- 堆区 : 存放的是值真正的位置
3.总结
- 直接引用指的是从栈区出发直接引用到的内存地址
- 间接引用指的是从栈区出发引用到堆区后,再通过进一步引用才能到达的内存地址
四.标记清除
1.循环引用问题(也叫交叉引用)
我们先定义列表
l1=[0] # 列表1被引用一次,列表1的引用计数变为1
l2=[1] # 列表2被引用一次,列表2的引用计数变为1
将列表加入另一个列表
l1.append(l2) # 把列表2追加到l1中作为第二个元素,列表2的引用计数变为2
l2.append(l1) # 把列表1追加到l2中作为第二个元素,列表1的引用计数变为2
解除比变量名"l1"和"l2"与值的对应关系
del l1
del l2
3.循环引用导致的结果
- 值不再被任何名字关联,但是值的引用计数并不会为0
- 应该被回收但又不能被回收
4.解决方法 : 清除-标记
- 容器对象的的引用都有可能产生循环引用, 而清除-标记就是为解决这个问题的
- 当应用程序可用空间被耗尽时, 清除-标记会停止整个程序, 然后先标记, 再清除
标记
但凡是可以从栈区出发,找到对应堆区内容的(直接或间接引用)就标记存活,非存活则清除
具体点:标记的过程其实就是,遍历所有的"GC Roots"对象(栈区中的所有内容或者线程都可以作为"GC Roots"对象)
然后将所有"GC Roots"的对象可以直接或间接访问到的对象标记为存活的对象,其余的均为非存活对象,应该被清除
清除
遍历堆中的对象,将没有标记存活的对象都清理掉
五.分代回收
1.效率问题
- 基于引用计数的回收机制,每次回收内存,都需要把所有对象的引用计数都遍历一遍
- 这是非常消耗时间的,于是引入了分代回收来提高回收效率
- 分代回收采用的是用“空间换时间”的策略。
2.解决方法 : 分代回收
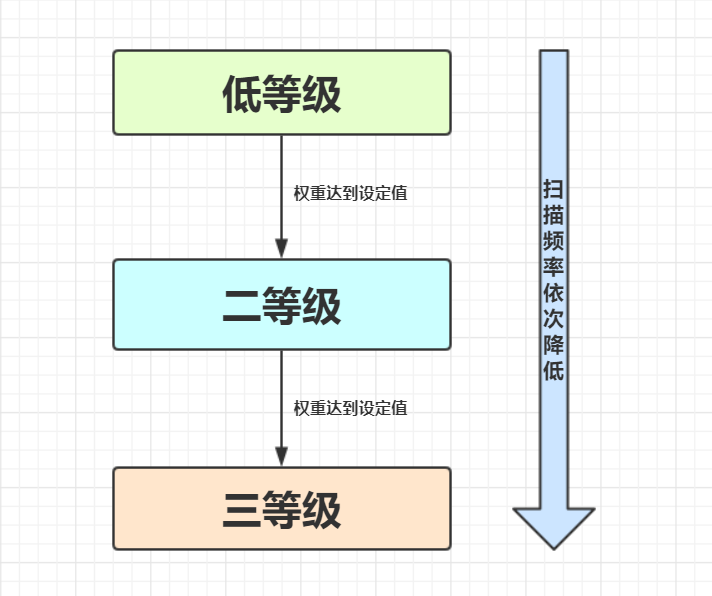
- 分代
分代指的是根据变量的存活时间来划分他们的等级
一个变量经常被引用,等级(权重)就会提高,权重达到设定值就会进入下一个等级
当经过多次扫描都没有被回收,"GC机制"就会认为该变量是常量
于是对其的扫描频率会降低
- 回收
当计数降低,就容易被回收
分代回收可以起到提升效率的效果,但也存在一定的缺点:
比如一个变量刚从低等级转入高等级,它就被解除了绑定关系
它应该被回收,但高等级扫描频率低于低等级
那么这个已被解除绑定关系的变量无法及时得到清理
- 总结
垃圾回收机制是在清理垃圾和释放内存的前提下
允许一些垃圾不被释放为代价(就是等级权重高点的垃圾不会及时被清理)
以此换取引用计数扫描频率的降低,从而提升其性能
这是一种以空间换时间的解决方案