广度(BFS)和深度(DFS)优先算法这俩个算法是图论里面非常重要的两个遍历的方法。
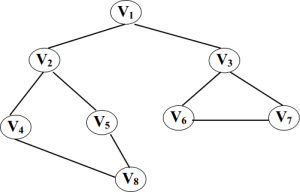
下面一个例子迷宫计算,如下图


解释:
所谓广度,就是一层一层的,向下遍历,层层堵截,看下面这幅图,我们如果要是广度优先遍历的话,我们的结果是V1 V2 V3 V4 V5 V6 V7 V8。
广度优先搜索的思想:
① 访问顶点vi ;
② 访问vi 的所有未被访问的邻接点w1 ,w2 , …wk ;
③ 依次从这些邻接点(在步骤②中访问的顶点)出发,访问它们的所有未被访问的邻接点; 依此类推,直到图中所有访问过的顶点的邻接点都被访问;
说明:
为实现③,需要保存在步骤②中访问的顶点,而且访问这些顶点的邻接点的顺序为:先保存的顶点,其邻接点先被访问。 这里我们就想到了用标准模板库中的queue队列来实现这种先进现出的服务。
步骤:
1.将V1加入队列,取出V1,并标记为true(即已经访问),将其邻接点加进入队列,则 <—[V2 V3]
2.取出V2,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V3 V4 V5]
3.取出V3,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V4 V5 V6 V7]
4.取出V4,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V5 V6 V7 V8]
5.取出V5,并标记为true(即已经访问),因为其邻接点已经加入队列,则 <—[V6 V7 V8]
6.取出V6,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V7 V8]
7.取出V7,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V8]
8.取出V8,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[]
区别:
深度优先遍历:对每一个可能的分支路径深入到不能再深入为止,而且每个结点只能访问一次。不全部保留结点,占用空间少;有回溯操作(即有入栈、出栈操作),运行速度慢。
广度优先遍历:又叫层次遍历,从上往下对每一层依次访问,在每一层中,从左往右(也可以从右往左)访问结点,访问完一层就进入下一层,直到没有结点可以访问为止。保留全部结点,占用空间大; 无回溯操作(即无入栈、出栈操作),运行速度快。
时间复杂度:
深度优先
数组表示:查找所有顶点的所有邻接点所需时间为O(n2),n为顶点数,算法时间复杂度为O(n2)
广度优先
数组表示:查找每个顶点的邻接点所需时间为O(n2),n为顶点数,算法的时间复杂度为O(n2)