PrivateSQL:一种差分隐私SQL查询的引擎
这篇文章是作者杜克大学的Ios Kotsogiannis所做的工作,并且这篇文章是作者的博士论文工作的一部分,他的博士论文叫 Query Answering in Muti-Relation Databases Under Differential Privacy ,这篇文章是作者把100多页的博士论文压缩到了14页上发的PVLDB的数据库的顶刊上,足以看到这篇文章所包含的内容之多。
这篇文章的主要比较对象是FLEX,FLEX是论文(Towards Practical Differential Privacy for SQL Queries)提出的工具,并且也构建了一个开源的工具,Presto:Distributed SQL Query Engine for Big Data 这个工具的网址是 https://prestodb.io
摘要:
因为前面的研究都是单表查询或者无约束的单关系查询,但是在实际中确实有约束的多关系模式最为常见,虽然存在针对特定类型的关系数据(例如图形)的定义和专用算法的变体,但是对于具有约束的多关系模式,没有通用的隐私定义,也没有系统允许对SQL查询进行精确的差异私有应答。所以导致只能有专业人士才能使用差分隐私私有查询,对于非专业人士十分不友好,所以作者就提出了第一个端到端差异私有关系数据库系统,实验证明效果还不错。
所以重点是提出了将差异私有化的sql查询系统,并且考虑到了差分隐私,即使进行了很多次的私有隐私差分查询,也可以保证数据的隐私安全。
一、介绍:
差分隐私是在分析数据中广泛考虑使用的用于保护隐私的手段,具体的实现是通过在输出上添加噪音,使用户无法根据自己拥有的全部最大背景知识通过输出结果来获得原始数据库的数据特征,从而保证了数据的隐私安全。比如google,apple公司就用到了这项技术。
但是存在的最大局限性是只有专业人士才能使用,无法在社会中广泛的使用,因为涉及到了算法的选择隐私预算分配等专业性极强的工作,对于每一种的数据都需要设计一种精确的算法来实现差分隐私。
首先当原始的数据库涉及到多个表的时候,这个时候算法设计的挑战更大。其次,还没有已知的算法可以在关系数据库上准确回答复杂的查询,比如连接,分组依据和相关子查询。当然目前面临的最大的对手是FLEX。 第三,没有已知的算法可以在公共隐私预算下准确回答复杂的查询集。
我们的愿景是通过建立一个差分私有关系数据库来降低非专家的进入门槛。(a)支持具有多个表的现实关系模式下的隐私策略,(b)允许分析师通过涉及以下内容的聚合查询以声明方式查询数据库标准的SQL运算符(例如联接,分组依据和相关子查询),(c)自动设计一个调整到隐私策略和分析师查询的错误率低的策略,并且(d)使用固定的隐私预算来确保针对系统的所有查询的差异性隐私。
文章的贡献在于1.PrivateSQL是同类中第一个端到端差异私有关系数据库系统。2.PrivateSQL使用新颖的差分隐私泛化功能,对具有约束的多关系数据库使用多种分辨率指定隐私。3.PrivateSQL采用一种新的方法来在固定的隐私预算下回答复杂的SQL计数查询。4.PrivateSQL使用各种新技术,例如策略感知的重写,截断和约束可忽略的敏感性分析,可确保根据数据所有者的隐私策略,从视图生成的私有概要可证明地确保了隐私,并具有很高的准确性。5.实验证明结果很好。
二、概述:
PrivateSQL有三个最主要的目标是:1.工作量(条件是隐私首先的工作量)2.复杂的查询(如连接,分组和相关子查询)3.多分辨率隐私。
系统架构的介绍:
2.1中心思想
设计该系统架构的五个主要的中心思想:
1.为了支持查询的工作量,选择构造摘要。2.为了支持复杂查询,选出了一定的视图并且为每个视图都构造摘要。3.介绍了用于计算视图灵敏度界限的新颖技术,因为有时候灵敏度是无界无限制的的。4.我们的第四个关键思想是将差异隐私扩展到多关系设置。5.第五个是我们使用视图重写来确保正确的(这个还没弄明白,需要继续去读文章 Answering Queries Using Views:A Survey)。
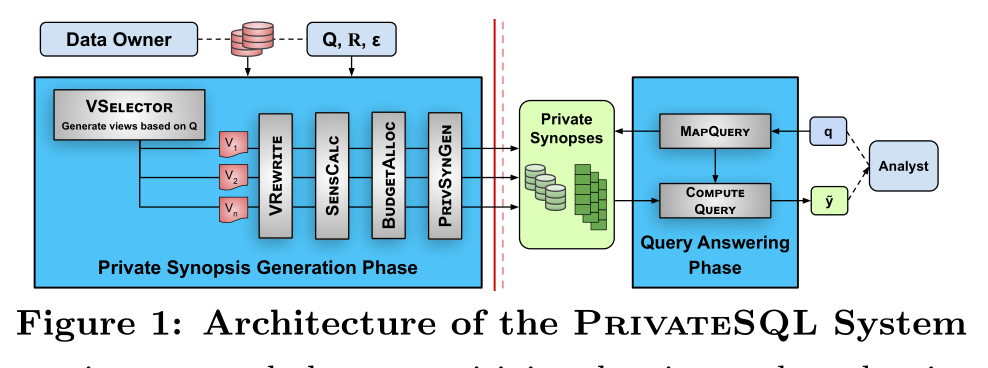
系统架构图
2.2系统结构
两个主要阶段操作的算法。1.摘要生成。2.查询回答。
在摘要生成中又有几个算法 视图的选择,截断重写,敏感度的计算 半连接重写 私有概要生成和隐私预算分配。(这几个算法到目前为止都没有完全理解,还需要一个一个地击破)
在查询回答中主要有MAPQUERYTOVIEW 将查询语句映射到视图上。这个MAPQUERYTOVIEW算法还需要进一步理解。
三、注释
这部分主要介绍了一些基本概念,这个地方我认为去看这个网址的内容会更好理解一点。
https://blog.csdn.net/Ano_onA/article/details/100550926?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522160652862419726891157079%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=160652862419726891157079&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-1-100550926.first_rank_v12_rank_v28p3&utm_term=%E5%B7%AE%E5%88%86%E9%9A%90%E7%A7%81&spm=1018.2118.3001.4449
里面介绍了 查询、邻近数据库、差分隐私、敏感度(包含全局敏感度、局部敏感度)、实现机制(拉普拉斯机制和指数机制)以及组合原理,对于刚入们的人非常友好。对于差分隐私的理解可以去知乎中搜索了解。
四、隐私模型
其中介绍了单个关系的差分隐私定义和多个关系的差分隐私定义。以及次要私人关系、视图的全局敏感度,以及多重关系的差分隐私定义,这个地方没搞懂的是如何将差分隐私与图联系起来,需要去读文章(Private Analysis of Graph Struct)

上图显示了VSelector的执行,对于输入Q,它产生视图V1和V2。查询q1和q2可以通过V1上的线性查询q1和q2来回答。同样,可以从V2上的查询q3和q4回答q3和q4。
个人感觉这个视图选择的q4有点问题。
五、视图选择
视图选择模块VSelector将模式S上的一组代表性查询Q作为输入,并输出一组视图V,以使每个查询q∈Q可以使用一些V∈V线性地回答。这个地方有问题为什么线性回答可以不用添加其他的操作,而非线性的操作却可以。
mapquerytoview操作有三个步骤(1)基准转换(2)去相关(3)去除过滤器(这个需要看论文 Magic sets and other strange ways to implement logic programs(extended abstract))
六、视图敏感度分析
计算SQL视图的全局敏感性是一个难题。这一节是针对单个关系的视图敏感度的分析。
-2020.11.28日早上
2020.11.29日继续更新
6.1 敏感度计算
这节中提到了一个新的概念 Constraint-Oblivious Down Sensitivity 约束不明显的向下敏感度 提到这个新的概念的原因是在简单政策中与实际的敏感度相同。后面再复杂政策中又提到了一个新的概念半连接重写 目的是转换实际需要算的敏感度,转化成可计算的形式
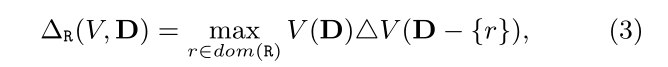
这就是约束不明显的向下敏感度
下图是敏感度计算的规则,其中max-frequency是敏感度的上界

6.2通过截断来限制灵敏度

这个图我看了好半天才看懂,应该是从下往上看,而且这个例子用的是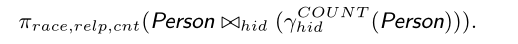
使用了截断处理后,敏感度就不在取决于maxfrequency而是取决于截断阈值,而截断阈值是可以通过截断处理得到的。
6.3 学习截断阈值
这个看懂算法就行,目前还没完全理解这个算法

七、处理复杂政策
这个地方提到了一个新的方法来处理复杂政策,半连接重写,因为不能再使用约束不明显的向下敏感度,他只适用于简单政策,因为复杂政策中会有次要私人关系,会影响到很多行,会产生噪音,所以这个就不再适用了,于是作者就提出了另一个概念,半连接重写,在sql中常见的半连接重写有exist,in这样的操作,于是这样就可以来估算敏感度了,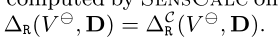
这个地方没看懂,
半连接的定义看不懂,下面的example 4.也没看懂。
八、生成概要
这里作者简要地说明了生成概要的两个步骤,1.私人概要生成器 2.私人预算分配器 这个地方需要去补基础知识,去看别人论文是如何介绍的
九、实验过程
在9.1节,实验使用的是现成的数据,U.S. Census data releases TPC benchmark,在9.2节中,我们介绍了一个端到端的错误评估分析。在9.3节中,我们将与先前的工作进行比较(Flex [24])。最后,在9.4节中,我们评估了PrivateSQL组件的替代选择。
ending。