一、Tensor用于自动求梯度
"tensor"这个单词⼀般可译作“张量”,张量可以看作是⼀个多维数组。标量可以看作是0维张量,向量可以看作1维张量,矩阵可以看作是⼆维张量。
在深度学习中,我们经常需要对函数求梯度(gradient)。PyTorch提供的autograd 包能够根据输⼊和前向传播过程⾃动构建计算图,并执⾏反向传播。本节将介绍如何使⽤autograd包来进⾏⾃动求梯度的有关操作。
概念
Pytorch中的Tensor 是这个包的核⼼类,如果将其属性 .requires_grad 设置为 True ,它将开始追踪(track)在其上的所有操作(这样就可以利⽤链式法则进⾏梯度传播了)。完成计算后,可以调⽤ .backward() 来完成所有梯度计算。此 Tensor 的梯度将累积到 .grad 属性中。
注意在
y.backward()时,如果y是标量,则不需要为backward()传⼊任何参数;否则,需要传⼊⼀个与y同形的Tensor。
如果不想要被继续追踪,可以调⽤ .detach() 将其从追踪记录中分离出来,这样就可以防⽌将来的计算被追踪,这样梯度就传不过去了。此外,还可以⽤ with torch.no_grad() 将不想被追踪的操作代码块包裹起来,这种⽅法在评估模型的时候很常⽤,因为在评估模型时,我们并不需要计算可训练参数(requires_grad=True)的梯度。
Function 是另外⼀个很重要的类。 Tensor 和 Function 互相结合就可以构建⼀个记录有整个计算过程的有向⽆环图(DAG)。每个 Tensor 都有⼀个 .grad_fn 属性,该属性即创建该 Tensor 的Function , 就是说该 Tensor 是不是通过某些运算得到的,若是,则 grad_fn 返回⼀个与这些运算相关的对象,否则是None。
import torch
# 通过设置`requires_grad=Ytue`,使得操作通过链式法则进行梯度传播
x = torch.ones(2, 2, requires_grad=True)
print(x)
print(x.grad_fn)
# +的运算操作
y = x+2
print(y)
print(y.grad_fn)
print(x.is_leaf,y.is_leaf)
# 复杂一点的运算操作
z = y*y*2
print(z)
print(z.grad_fn)
out = z.mean()
print(z, out)
输出结果:

二、梯度
因为 out 是⼀个标量,所以调⽤ backward() 时不需要指定求导变量:
# 通过`requires_grad()`来用`in-place`的方式来改变`requieres_grad`属性
a = torch.rand(2,2)
a = ((a*3)/(a-1))
print(a.requires_grad) #False
a.requires_grad_(True)
print(a.requires_grad) #True
b = (a*a).sum()
print(b.grad_fn)
输出结果:

因为 out 是⼀个标量,所以调⽤ backward() 时不需要指定求导变量:
# 因为 out 是⼀个标量,所以调⽤ backward() 时不需要指定求导变量:
out.backward()
print(x.grad)
输出结果:(教程是4.5,因为前面我的数据处理不同)
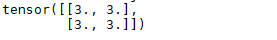
量都为向量的函数(vec y = fleft(vec x ight)) , 那么(vec y) 关于(vec x)的梯度就是⼀个雅可⽐矩阵(Jacobian matrix):
⽽ torch.autograd 这个包就是⽤来计算⼀些雅克⽐矩阵的乘积的。例如,如果v 是⼀个标量函数的(l = g left(vec y
ight))的梯度:
那么根据链式法则我们有(l) 关于(vec x) 的雅克⽐矩阵就为:
注意:grad在反向传播过程中是累加的(accumulated),这意味着每⼀次运⾏反向传播,梯度都会累加之前的梯度,所以⼀般在反向传播之前需把梯度清零。
再来反向传播⼀次,注意grad是累加的:
out2 = x.sum()
out2.backward()
print(x.grad)
out3 = x.sum()
x.grad.data.zero_()
out3.backward()
print(x.grad)
输出结果:

Question:为什么在 y.backward() 时,如果 y 是标量,则不需要为 backward() 传⼊任何参数,否则,需要传⼊⼀个与 y 同形的 Tensor ?
Ans:为了避免向量(或者更高维张量)对张量进行求导,而转换成标量对张量进行求导(通过将所有张量的元素加权求和的方式转化为标量。)。