今天开始对本项目进行收尾工作,添加小程序的文档下载 ,以及完善热词的相关链接。
主要有以下工作:
一、词库选择:
(一)词库比较
我们这个项目主要尝试了jieba库、foolnltk库、中科院的nlpir词库、清华大学的THUOCL(THU Open Chinese Lexicon)词库,下面将对每一个词库进行简要介绍,以及在本项目中的发挥成效进行展示。
1.jieba库:
(1)简要介绍:
支持三种分词模式:
- 精确模式:试图将句子最精确地切开,适合文本分析;
- 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
它还可以支持繁体分词和自定义词典。
实现机制:
基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG),采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合,对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法。
使用效果:
这是我们最早使用的词库,也是相比较于其他三个词库这也是最广泛的库,但是其对于本项目缺少专业性,分词结果的噪音太大。
2.foolnltk———— 可能是最准的开源中文分词,但很慢啊
基于 BiLSTM 模型训练而成,包含分词,词性标注,实体识别, 都有比较高的准确率,用户可以自定义词典,并且训练自己的模型,还可进行数据批量处理。
使用效果:
如果我们的硬件设施再好些,数据量再多一些,或许我们会使用这个词库,因为在实际的操作过程中,即使一篇很短的文章,也跑了将近半个小时,总的来说,并不适用于该项目。
3.中科院的nlpir词库——这次用过的最赞的
主要功能包括中文分词;英文分词;词性标注;命名实体识别;新词识别;关键词提取;支持用户专业词典与微博分析。NLPIR系统支持多种编码、多种操作系统、多种开发语言与平台。
这是nlpir在线词库使用,直接用一个案例进行展示他的强大作用:
(1)采用工信部官网中《2006━2020年国家信息化发展战略》文章,对其进行分析,首先输入网址
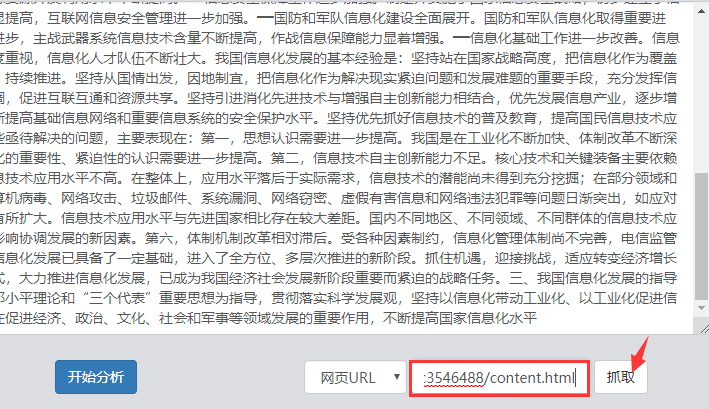
(2)点击上图中的蓝色按钮“开始分析”,查看热词分析结果:

(3)更多功能展示:

(4)这是其中的实体抽取,与本项目的项目意图很契合,只是只能分析一篇文章的词语关联关系,因此我们若要使用它,还得进行优化。
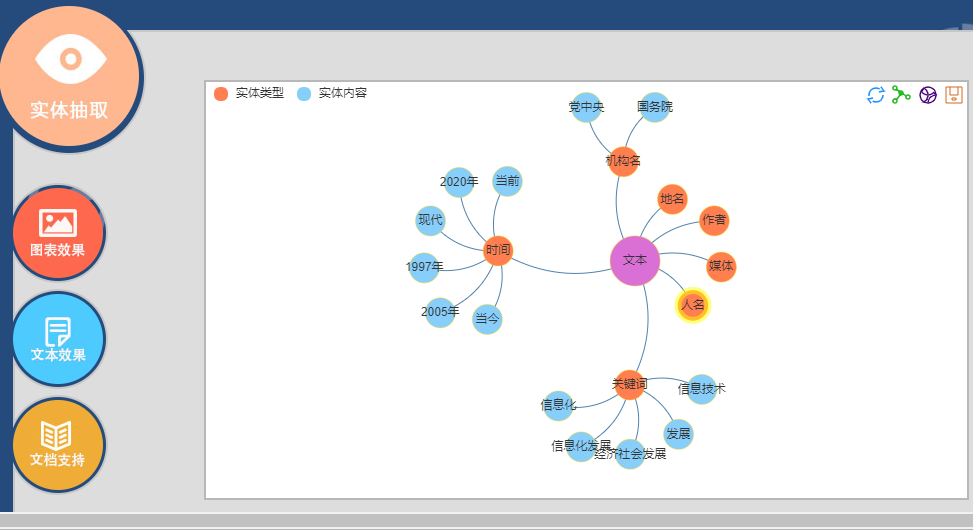
使用效果:
这是我们最终选用的词库,功能实在庞大,对于分词的可视化展示效果很好,推荐学习和使用。
3.清华大学的THUOCL(THU Open Chinese Lexicon)词库
THUOCL(THU Open Chinese Lexicon)是由清华大学自然语言处理与社会人文计算实验室整理推出的一套高质量的中文词库,词表来自主流网站的社会标签、搜索热词、输入法词库等。 THUOCL 具有以下特点: 包含词频统计信息 DF 值(Document Frequency),方便用户个性化选择使用。 词库经过多轮人工筛选,保证词库收录的准确性。
通过本项目也感受到我们还是才疏学浅,对于涉及到算法的东西,目前还仅仅只能做到应用,对其进行改进还需要进一步的钻研。由于开发时间有限,也只能将大佬们的研究成果加以应用。