1. 什么是数据挖掘?
数据挖掘是从大量数据中提取或“挖掘”知识,很多人也把数据挖掘视作“数据库中的知识发现”(KDD)。
数据挖掘的步骤包括:
- 数据清理(消除噪音或不一致数据)
- 数据集成(多种数据源可以组合在一起)
- 数据选择(从数据库中提取与分析任务相关的数据)
- 数据变换(数据变换或统一成适合挖掘的形式;如,通过汇总或聚集操作)
- 数据规约(属性规约、数值规约)
- 数据挖掘(基本步骤,使用智能方法提取数据模式)
- 模式评估(根据某种兴趣度度量,识别提供知识的真正有趣的模式)
- 知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)
2. 什么是数据仓库?
数据仓库是一个从多个数据源收集的信息储存,存放在一个一致的模式下,并通常驻留在单个站点。通俗讲,数据仓库是通过数据清理、数据变换、数据集成、数据装入和定期数据刷新构造。通常,数据仓库用多维数据库结构建模。数据仓库提供联机分析处理(OLAP)工具,用于各种粒度的多维数据分析,有利于有效的数据分析。构造数据仓库涉及数据清理和数据集成,是数据挖掘的一个重要的预处理步骤。
数据仓库是一个面向主题的,集成的,时变的,非易失的数据集合。
面向主题:数据仓库围绕一些主题,如顾客、供应商、产品和销售组织。数据仓库关注决策者的数据建模与分析,而不是构造组织机构的日常操作和事务处理。因此,数据仓库排除对于决策无用的数据,提供特定主题的简明视图。
集成的:通常,构造数据仓库是将多个异种数据源,如关系数据库、一般文件和联机事务处理记录,集成在一起。使用数据清理和数据集成技术,确保命名约定、编码结构、属性度量的一致性。
时变的:数据存储从历史的角度(例如,过去 5-10 年)提供信息。数据仓库中的关键结构,隐式或显式地包含时间元素。
非易失的:数据仓库总是物理地分离存放数据;这些数据源于操作环境下的应用数据。由于这种分离,数据仓库不需要事务处理、恢复和并行控制机制。通常,它只需要两种数据访问:数据的初始化装入和数据访问。
既然操作数据库存放了大量数据,为什么不直接在这种数据库上进行联机分析处理,而是另外花费时间和资源去构造一个分离的数据仓库?
分离的主要原因是为了提高两个系统的性能,操作数据库是为已知的任务和负载设计的,如使用主关键字索引和散列,检索特定的记录,和优化“罐装的”查询。另一方面,数据仓库的查询通常是复杂的,涉及大量数据在汇总级的计算,可能需要特殊的数据组织、存取方法和基于多维视图的实现方法。在操作数据库上处理 OLAP 查询,可能会大大降低操作任务的性能。
此外,操作数据库支持多事务的并行处理,需要加锁和日志等并行控制和恢复机制,以确保一致性和事务的强健性。通常,OLAP 查询只需要对数据记录进行只读访问,以进行汇总和聚集。如果将并行控制和恢复机制用于这种 OLAP 操作,就会危害并行事务的运行,从而大大降低 OLTP 系统的吞吐量。
最后,数据仓库与操作数据库分离是由于这两种系统中数据的结构、内容和用法都不相同。决策支持需要历史数据,而操作数据库一般不维护历史数据。在这种情况下,操作数据库中的数据尽管很丰富,但对于决策,常常还是远远不够的。决策支持需要将来自异种源的数据统一(如,聚集和汇总),产生高质量的、纯净的和集成的数据。相比之下,操作数据库只维护详细的原始数据(如事务),这些数据在进行分析之前需要统一。由于两个系统提供很不相同的功能,需要不同类型的数据,因此需要维护分离的数据库。然而,许多关系数据库管理系统卖主正开始优化这种系统,使之支持 OLAP 查询。随着这一趋势的继续,OLTP 和 OLAP 系统之间的分离可望消失。
3. 什么是数据集市
数据集市搜集了整个组织的主题信息,因此,它是企业范围的。另一方面,数据集市是数据仓库的一个部门子集,它聚焦在选定的主题上,是部门范围的。
4. OLTP和OLAP区别
数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
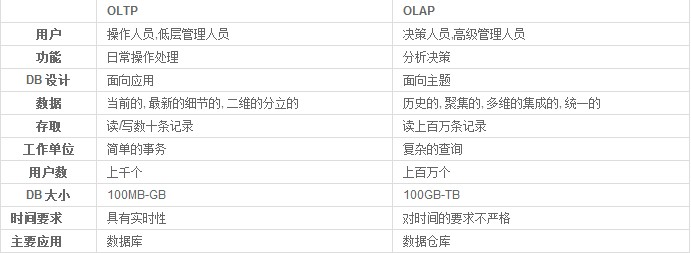
OLTP和OLAP的区别概述如下:
用户和系统的面向性:OLTP 是面向顾客的,用于办事员、客户、和信息技术专业人员的事务和查询处理。OLAP 是面向市场的,用于知识工人(包括经理、主管、和分析人员)的数据分析。
数据内容:OLTP 系统管理当前数据。通常,这种数据太琐碎,难以方便地用于决策。OLAP 系统管理大量历史数据,提供汇总和聚集机制,并在不同的粒度级别上存储和管理信息。这些特点使得数据容易用于见多识广的决策。
数据库设计:通常,OLTP 系统采用实体-联系(ER)模型和面向应用的数据库设计。而 OLAP 系统通常采用星形或雪花模型(和面向主题的数据库设计。
视图:OLTP 系统主要关注一个企业或部门内部的当前数据,而不涉及历史数据或不同组织的数据。相比之下,由于组织的变化,OLAP 系统常常跨越数据库模式的多个版本。OLAP 系统也处理来自不同组织的信息,由多个数据存储集成的信息。由于数据量巨大,OLAP 数据也存放在多个存储介质上。
访问模式:OLTP 系统的访问主要由短的、原子事务组成。这种系统需要并行控制和恢复机制。然而,对 OLAP 系统的访问大部分是只读操作(由于大部分数据仓库存放历史数据,而不是当前数据),尽管许多可能是复杂的查询。
多维数据模型上的OLAP操作包含:上卷、下钻、切片和切块(切片在数据方的一个维上进行选择,切块是在两个或多维选择)、转轴等。
5. 多维数据模型
数据仓库和 OLAP 工具基于 多维数据模型,该模型将数据看作数据方形式。数据方允许以多维对数据建模和观察,它由维和事实定义。一般地, 维是透视或关于一个组织想要记录的实体。例如,创建一个数据仓库 sales ,记录商店的销售,涉及维 time, item, branch , 和 location 。这些维使得商店能够记录商品的月销售,销售商品的分店和地点。每一个维都有一个表与之相关联。该表称为维表,它进一步描述维。例如, item 的维表可以包含属性 item_name, branch, 和 type 。维表可以由用户或专家设定,或者根据数据分布自动产生和调整。
通常,多维数据模型围绕中心主题(例如, sales )组织。该主题用事实表表示。 事实是数值度量的。例如,数据仓库 sales 的事实包括 dollars_sold , units_sold 和 amount_budgeted 。事实表包括事实的名称或度量,以及每个相关维表的关键字。
6. 元数据
元数据是关于数据的数据。在数据仓库中,元数据是定义仓库对象的数据。对于给定数据仓库的数据名和定义,创建元数据。其它元数据包括对提取数据添加的时间标签、提取数据的源、被数据清理或集成处理添加的字段等。