爬虫调度端:启动爬虫,停止爬虫,监视爬虫运行情况
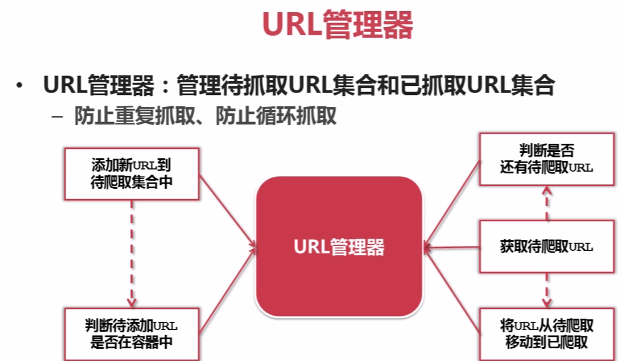
URL管理器:对将要爬取的和已经爬取过的URL进行管理;可取出带爬取的URL,将其传送给“网页下载器”
网页下载器:将URL指定的网页下载,存储成一个字符串,在传送给“网页解析器”
网页解析器:解析网页可解析出①有价值的数据②另一方面,每个网页都包含有指向其他网页的URL,解析出来后可补充进“URL管理器”

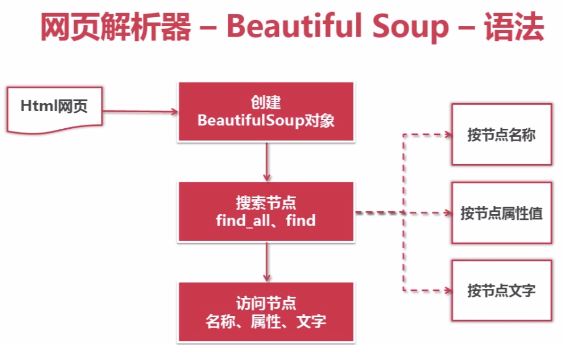
网页解析器——Beautiful Soup-语法:
例如以下代码:

对应的代码:
1、创建BeautifulSoap对象
2、搜索节点(find_all,find)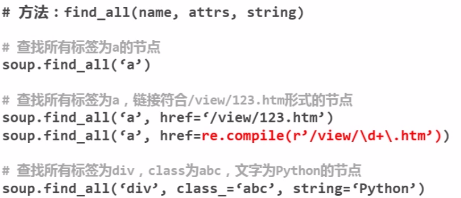
3、访问节点信息
# -*- coding: UTF-8 -*- from bs4 import BeautifulSoup import re html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ soup = BeautifulSoup(html_doc,'html.parser', from_encoding='utf-8')#(文档字符串,解析器,指定编码utf-8) print('获取所有的连接:') links = soup.find_all('a') for link in links: print link.name, link['href'],link.get_text() print('获取Lacie的连接:') link_node = soup.find('a', href='http://example.com/lacie')#text='Lacie' print link_node.name,link_node['href'],link_node.get_text() print('正则匹配') link_node = soup.find('a', href=re.compile(r'ill')) print link_node.name,link_node['href'],link.get_text() print('获取p段落文字:') p_node = soup.find('p', class_='title')#class_ print p_node.name, p_node.get_text()