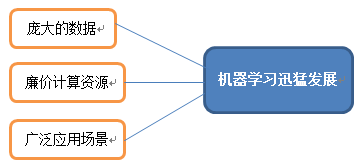
近几年机器学习非常火,机器学习并不是近来才出现的已经出现了几十年了,但随着互联网、移动互联网、计算资源的迅猛发展使得机器学习有了庞大的数据、 廉价的计算资源、 广泛的应用场景;三种条件可以说缺一不可,互联网、移动互联网带来了大数据与广泛的应用场景,摩尔定律使得机器越来越便宜云计算的出现又让计算资源更廉价了;使得机器学习有了快速的发展并引爆技术圈;现在比较火的深度学习其实也只是机器学习的升级版;
应用场景
机器学习的应用场景非常广泛,这里简单介绍几个场景:个性化推荐、 垃圾邮件分类、 信贷风险预测;
个性化推荐现在可以说是每个网民再熟悉不过的了,电商对机器学习应用最早的或许就是亚马逊了,电商中我们看得到的既熟悉又陌生的机器学习应用场景就是“千人千面”,也就是电商的推荐系统,据说亚马逊靠这个技术带来的营收超过5%,千人千面简单简单讲就是每个用户登陆看到的推荐商品都是不一样的,这些都是通过用户购买记录、社交关系通过算法计算出来的;
垃圾邮件每一个人都知道,但垃圾邮件是怎么拦截的可以说知道的人不多;垃圾邮件分类其实用的就是机器学习的分类算法,通过收集垃圾邮件数据集通过特征工程抽取改数据集中共有的特征,特征可以是包含某些关键字、邮件的长度等等,然后通过训练出模型新接受的邮件都通过这个模型来进行垃圾邮件与非垃圾邮件的分类;现在贝叶斯分类器用得比较多;
信贷风险预测也就是金融机构对贷款客户的风控分析,其实也是机器学习的分类算法,收集历史贷款客户的数据房产、职业、资产、社交等等,给出风控模型,然后通过模型预测客户分类为1、2、3、4等,为客户的风险系数;
机器学习怎么做
前面说了不少概念性的东西,接下来说说机器学习到底是怎么应用数据进行学习的; 机器学习从学习方式上分可以简单的分为这么两类:监督学习、无监督学习;

监督学习(supervised learning):用来学习的数据集样本中已经中包含了特征、标签(结果);例如要去预测房价已经有这么一个数据集:位置、是否学区、户型、朝向、价格,这个样本集中前面四项就是特征、后面一项就是标签,为模型预测出来的结果;这样的算法就成为监督学习算法;训练模型就是调整生成特征与标签关系映射的最优函数;
无监督学习(unsupervised learning):数据集样本中只包含特征并没有标签;例如要对房子进行归类,有这么一个数据集:位置、是否学区、户型、朝向,数据集只有特征没有标签,可以通过算法如聚类算法来训练模型,用于对房子进行归类;
模型训练流程
下图是最基本机器学习训练流程:

上图中有几个机器学习算法中很重要的几个元素:假设函数(hypothesis function)、 代价函数(cost function) 、theta,这几个可以说是机器学习算法的基础元素;
假设函数:这与我们的模型息息相关如果是线性回归模型则假设函数是线性函数,如是逻辑回归模型通常假设函数为S函数(Sigma Function)对监督学习而言假设函数可以理解为特征到结果的映射函数,而机器学习就是学习假设函数中参数theta的过程;
代价函数:也称损失函数(Loss Function),用于判断假设函数的优劣,简单的说就是对假设函数进行评分也就是判断当前参数theta下假设函数是否已达到最优化,否则调整参数theta继续学习;代价函数通常有平方误差函数、0-1损失函数、指数损失函数等;
Theta:也称为参数,模型的参数假设函数的参数,通常的机器学习就是学习最优参数的过程,也就是说通过学习参数使得代价函数的损失最小,达到最优化或者损失函数的阈值;
近年来的强化学习、深度学习等其实都是从传统机器学习的基础上发展而来的,机器学习、统计学习就是这些技术的源头;