好记忆不如烂笔头,之前西瓜书这章也看过几次但还是掌握不够,今天又拿来翻翻顺便做个笔记;
前面写了几篇线性回归与逻辑回归的文章,是说模型训练的但是模型的性能怎样该怎么选择使用最小二乘法还是梯度下降法呢,我们总得要比较模型的性能再做选择吧;所以就有了这里所说的模型评估与选择;
既然是读书比较我们先看看书本里讲了什么:

从五个方面讲了模型的评估与选择:
1、经验误差与过拟合
2、评估方法
3、性能度量
4、比较检验
5、偏差与方差
一、经验误差与过拟合

在分类模型中把分类错误样本数占总样本的比例成为:错误率(error rate)
M个样本、a个样本分类错误,错误率为:E=a/m,精度=1-错误率*100%
在实际的模型中,不可能存在分类错误率为0、分类精度为100%,一旦出现就可以说该模型过拟合了;
过拟合为NP问题,在训练模型时要注意好过拟合与欠拟合之间的尺度;
二、评估方法

在对模型进行泛化误差评估时通常使用一个测试集(testing set)来测试模型对新样本的判别能力;
通常我们只有个训练集,这时需要把训练集分为训练记与测试集两个部分,并且要保证测试集与训练集尽可能互斥,使得测试样本尽可能未在训练中使用过,从而保证能够真实的评估出模型的泛化能力;
有M个样例数据集: 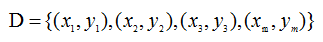
怎么把数据集分为训练集S与测试集T呢,下面介绍几种常用的方法:
1、留出法(hold-out)
留出法:直接将数据集D划分为两个互斥的集合,训练集S与测试集T;
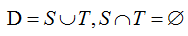
用S训练出模型,用T评估测试误差作为泛化误差的估计;
通常使用2/3~4/5的样本用于训练;
2、交叉验证法(cross validation):
交叉验证法:将数据集划分为k个大小相似互斥子集,

每个子集尽可能保持数据分布一致性,每次使用k-1个子集作为训练集,剩下一个作为测试集,这可取得k组训练、测试集进行k次训练与测试取k个测试结果的均值作为模型的评估结果;交叉验证法又称k折交叉验证;
3、自助法(bootstrapping):
留出法与交叉验证法由于保留部分样本用于测试,使得实际评估模型使用训练集比D小,这时可能会由于样本规模小导致偏差,从而存在欠拟合;自助法正是不错的解决方案;
自助法以自助采样为基础,在给定m个样本的数据集D,进行采样产生数据集D1;
产生方法为:每次随机从D中挑选一个样本,拷贝放入D1中,再将样本放回数据集D,该样本在下次仍然可能被采样到,重复m次得到包含m个样本的数据集D1;
样本在m次采样中不被采样到的概率为:

使用自助法初始数据集中仍然有36.8%样本未被使用过,实际评估模型与期望评估的模型都使用m个训练样本;自助法在训练集小规模不够时比较适合;
三、性能度量

在之前的线性回归中说过梯度下降法、最小二乘法都是求出方差最小时的参数值;
样本集: ,其中y为样本的真实值,评估模型性能就是拿模型预测值f(x)与真实的样本值y进行比较;
,其中y为样本的真实值,评估模型性能就是拿模型预测值f(x)与真实的样本值y进行比较;
均方误差(mean squared error)

错误率:

精度:

1、查准率、查全率、F1
错误率只能评估模型多多少样本预测错了,如模型是判别垃圾邮件,错误率只能评估模型有多少邮件被判别错了,如要想知道所有垃圾邮件中多少比例被判别出来了,错误率就不能评估了;
在使用逻辑回归进行二分类预测时,模型预测值与真实的类别组合可分为:
真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative),分别用TP、FP、TN、FN表示相应样例数,样例总数为:TP+FP+TN+FN;分类结果混淆矩阵;


通常查准率高时查全率低,查全率高时查准率低;
可以通过P-R曲线来取两者的平衡值,但更常用的使用F1来衡量查准率与查全率;
F1基于查准率与查全率的调和平均;

四、比较检验

统计假设检验(hypothesis test):对模型进行性能比较时基于假设检验可以推断出测试集上观察到的A比B好则A的泛化性能是否在统计意义上优于B;
假设检验:假设是对模型泛化错误率分布的某种判断与猜想,实际中并不知道泛化错误率,通常使用测试错误率推出泛化错误率分布;
Friedman检验与Nemenyi后续检验:交叉验证、McNamar验证为在一个数据集上对模型进行比较,Friedman校验在一组数据集上对多个模型进行比较
五、偏差与方差

偏差-方差分解(bias-variance decomposition)为解释模型泛化性能的工具;为什么模型具有如此泛化性能;
期望输出与真实标记的差别称为偏差(bias),期望值与实际值的偏离程度;
方差(variance):衡量相同样本数目,不同训练集 预测值的变化程度离期望值越远方差越大;
泛化误差可分解为:偏差、方差、噪声之和
偏差较大导致欠拟合 、过于接近训练集,不够泛化,方差过大导致过拟合;
参考资料:
周志华 Machine Learning