https://www.jianshu.com/p/e6f2036621f4
https://zhuanlan.zhihu.com/p/36731397

https://blog.csdn.net/weixin_33938733/article/details/92513096
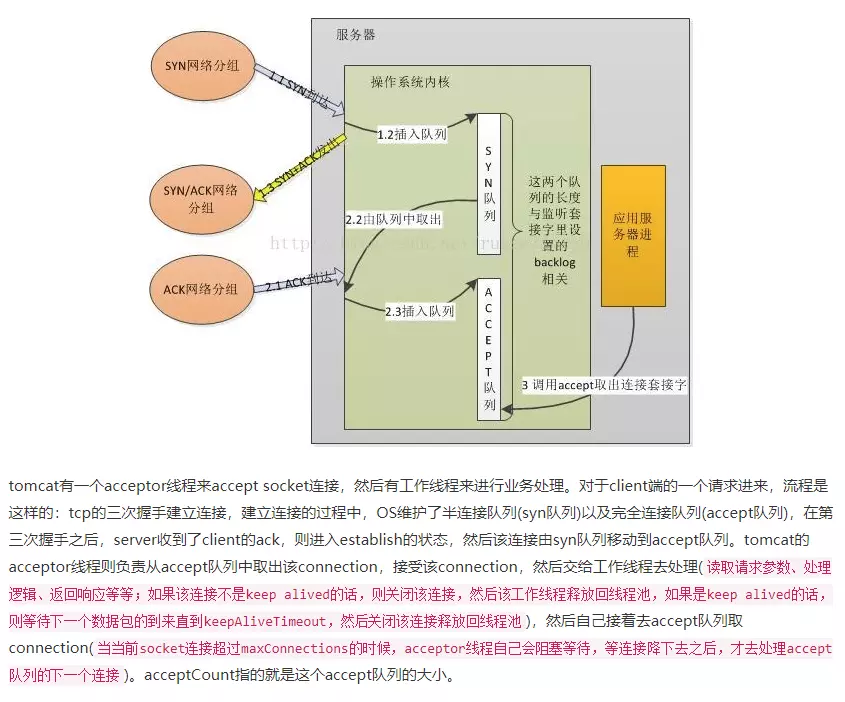
tomcat最根本就是一个Socket Server,于是我找到了org.apache.tomcat.util.net.DefaultServerSocketFactory#createSocket(int port, int backlog),最终就是这个方法执行new java.net.ServerSocket(port, backlog)启动了一个ServerSocket实例。
查看ServerSocket API就发现@param backlog the maximum length of the queue.
明确了,tomcat的acceptCount就是ServerSocket的等待队列。
但设置的acceptCount怎么设置到backlog上呢,我翻了好一会儿代码才注意到org.apache.catalina.connector.Connector中有一个变态的HashMap通过这个HashMap把参数名做了一次转换,再赋值给Http11Protocol使用。这样的变态我想应该是想方便tomcat的使用者吧,毕竟整一个backlog参数谁知道是干什么的,另外这个HashMap也把其它参数名做了转换,代码如下
- protected static HashMap replacements = new HashMap();
- static {
- replacements.put("acceptCount", "backlog");
- replacements.put("connectionLinger", "soLinger");
- replacements.put("connectionTimeout", "soTimeout");
- replacements.put("connectionUploadTimeout", "timeout");
- replacements.put("clientAuth", "clientauth");
- replacements.put("keystoreFile", "keystore");
- replacements.put("randomFile", "randomfile");
- replacements.put("rootFile", "rootfile");
- replacements.put("keystorePass", "keypass");
- replacements.put("keystoreType", "keytype");
- replacements.put("sslProtocol", "protocol");
- replacements.put("sslProtocols", "protocols");
- }
- // ------------------------------------------------------------- Properties
- /**
- * Return a configured property.
- */
- public Object getProperty(String name) {
- String repl = name;
- if (replacements.get(name) != null) {
- repl = (String) replacements.get(name);
- }
- return IntrospectionUtils.getProperty(protocolHandler, repl);
- }
- /**
- * Set a configured property.
- */
- public boolean setProperty(String name, String value) {
- String repl = name;
- if (replacements.get(name) != null) {
- repl = (String) replacements.get(name);
- }
- return IntrospectionUtils.setProperty(protocolHandler, repl, value);
- }
总结:acceptCount参数其实就是new java.net.ServerSocket(port, backlog)的第二个参数,了解后再设置就不会盲目了。
myblog
https://www.iteye.com/blog/shilimin-1607722
TCP连接的ACCEPT队列
https://blog.csdn.net/sinat_20184565/article/details/87887118
服务器accept队列溢出及其解决
之前对我的NetServer服务器进行测试,在经压力测试一段时间之后,数据曲线降0,之后所有的连接都连不上,我认为不是服务器挂了就是监听端口出问题了,于是看了下服务器还在运行,端口还在listened(通过命令查看:netstat -ltp),非常奇怪,这说明监听正常,能够进行三次握手的。
后来抓包分析,发现三次握手正常建立,但是服务器竟然重传了第二次握手包,总共5次,根据这个现象来看,表面上是服务器没有收到客户端的ACK确认才会触发第二次握手的重传的,但是实际上抓包抓到了ACK ,而且单机内部测试不太可能在传输过程中丢包。
猜测:收到ACK包后,内核协议栈处理出问题了,并没有把连接放到全连接队列中,可能全连接队列已满并溢出。
网上看内核协议栈的TCP连接建立过程如下:
于是我执行命令netsta -s | grep -i listen,ss -lnt 发现队列真的溢出了。
网上查找解决办法,调大accept队列,listen参数和somaxconn(默认128),而且又查到了tcp_abort_on_overflow,等于0时直接丢弃,定时器继续计时;等于1时发送RST给客户端,断开连接。
之后又看到相关的网络内核参数优化的博客:
1. time_wait 问题解决
cat /etc/sysctl.conf
net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;复用连接,1s后;服务器无效
net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。3.5*RTO 内回收
net.ipv4.tcp_timestamps
2.常见网络内核参数优化 https://www.cnblogs.com/jking10/p/5472386.html
net.ipv4.tcp_syncookies=1
表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
3.net.ipv4.tcp_max_syn_backlog = 16384
————————————————
版权声明:本文为CSDN博主「shhchen」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/shhchen/article/details/88554161
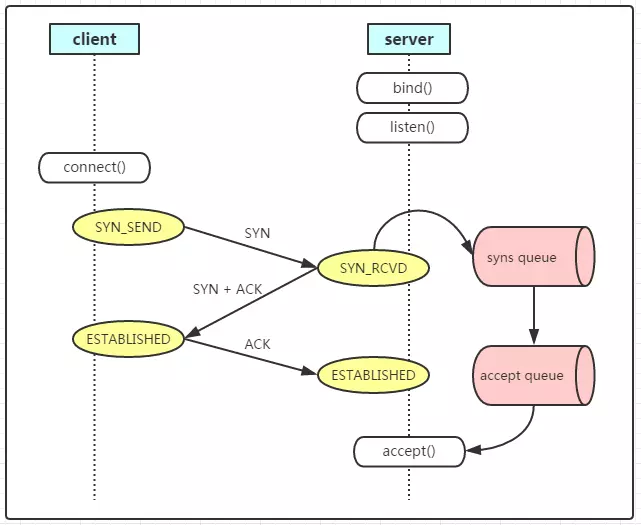
这可以理解成:Client的连接请求已经过来了,只不过还没有完成“三次握手”。因此,Server端需要把当前的请求保存到一个队列里面,直至当Server再次收到了Client的ACK之后,Server进入ESTABLISHED状态,此时:serverSocket 从accpet() 阻塞状态中返回。也就是说:当第三次握手的ACK包到达Server端后,Server从该请求队列中取出该连接请求,同时Server端的程序从accept()方法中返回。
那么这个请求队列长度,就是由 backlog 参数指定。那这个队列是如何实现的呢?这个就和操作系统有关了,感兴趣的可参考:How TCP backlog works in Linux
https://www.cnblogs.com/hapjin/p/5774460.html
在 SYN queue 未满的情况下,在收到 SYN 包后,TCP 协议栈自动回复 SYN,ACK 包,之后在收到 ACK 时,根据 accept queue 状态进行后续处理;
若 SYN queue 已满,在收到 SYN 时
若设置 net.ipv4.tcp_syncookies = 0 ,则直接丢弃当前 SYN 包;
若设置 net.ipv4.tcp_syncookies = 1 ,则令 want_cookie = 1 继续后面的处理;
若 accept queue 已满,并且 qlen_young 的值大于 1 ,则直接丢弃当前 SYN 包;
若 accept queue 未满,或者 qlen_young 的值未大于 1 ,则输出 "possible SYN flooding on port %d. Sending cookies.
",生成 syncookie 并在 SYN,ACK 中带上;
若 accept queue 已满,在收到三次握手最后的 ACK 时
若设置 tcp_abort_on_overflow = 1 ,则 TCP 协议栈回复 RST 包,并直接从 SYN queue 中删除该连接信息;
若设置 tcp_abort_on_overflow = 0 ,则 TCP 协议栈将该连接标记为 acked ,但仍保留在 SYN queue 中,并启动 timer 以便重发 SYN,ACK 包;当 SYN,ACK 的重传次数超过 net.ipv4.tcp_synack_retries 设置的值时,再将该连接从 SYN queue 中删除;
https://blog.csdn.net/weixin_33675507/article/details/91961139
记一次惊心的网站 TCP 队列问题排查经历
当前最流行的DoS(拒绝服务攻击)与DDoS(分布式拒绝服务攻击)的方式之一,这是一种利用TCP协议缺陷,导致被攻击服务器保持大量SYN_RECV状态的“半连接”,并且会重试默认5次回应第二个握手包,塞满TCP等待连接队列,资源耗尽(CPU满负荷或内存不足),让正常的业务请求连接不进来。
————————————————
版权声明:本文为CSDN博主「weixin_37478507」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_37478507/article/details/80319089
Java Socket 之参数测试-backlog
之前在做项目的时候,刚好用到Spring-Integration的TCP/IP组件,在定义ServerSocket的过程中,有一个参数backlog比较突出,通过网上的查阅,才知道这是原生Java中ServerSocket的参数。通过查API得知,ServerSocket的构造参数:public ServerSocket(int port,int backlog),API对于backlog的解析是这样的:requested maximum length of the queue of incoming connections;大意就是说TCP连接请求队列的最大容量。最初的理解就是如果ServerSocket由于请求太多处理不过来,后续的客户端连接就会放到阻塞队列里面,当队列满了(超过backlog定义的容量,默认为50),就会拒绝后续的连接。
1. 先上代码,再说结论:
Server端:

public class TestBackLog {
public static void main(String[] args) throws IOException, InterruptedException {
int backlog = 3;
ServerSocket serverSocket = new ServerSocket(5000, backlog);
//此处会造成客户端的连接阻塞,这时就会把request connection放到请求队列,而请求队列的容量就是backlog的值
//当程序启动,此处睡眠50秒,马上启动客户端,客户端每一秒钟起一个,起到第二个的时候,第三个就无法获得到ServerSocket
//只能等待,前两个连接已获取ServerSocket连接,只有等这两个处理完了,后续第三个才会拿到连接,进行处理(可从客户端输出得出此结论)
Thread.sleep(50000);//模拟服务端处理高延时任务
while (true) {
Socket socket = serverSocket.accept();
InputStream is = socket.getInputStream();
OutputStream os = socket.getOutputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
PrintWriter out = new PrintWriter(new OutputStreamWriter(os));
int length = -1;
char[] buffer = new char[200];
while (-1 != (length = br.read(buffer, 0, buffer.length))) {
String string = new String(buffer, 0, length);
System.out.println("TestBackLog receive String "
+ socket.getInetAddress() + ":" + socket.getLocalPort() + string);
out.write("server welcome!");
out.flush();
socket.shutdownOutput();
}
out.close();
br.close();
socket.close();
}
}
}
Client 端:
public class TcpClient {
public static void main(String[] args) throws UnknownHostException, IOException, InterruptedException {
for(int i=0; i<10; i++) {
Thread.sleep(1000);//创建端口太快,降低创建速率
new Thread(new ClientThread()).start();
}
}
}
class ClientThread implements Runnable {
@Override
public void run() {
try {
Socket client = new Socket("127.0.0.1", 5000);
System.out.println("client connected server");
InputStream is = client.getInputStream();
OutputStream os = client.getOutputStream();
os.write("clinet hello world!".getBytes());
client.shutdownOutput();//这一句非常重要啊,如果没有这句,服务端的read()会一直阻塞
int length = 0;
byte[] buffer = new byte[200];
while(-1 != (length = is.read(buffer, 0, buffer.length))) {
System.out.println("client");
String receiveString = new String(buffer, 0, length);
System.out.println("receiveString : " + receiveString);
}
} catch(Exception e) {
e.printStackTrace();
}
}
}
2. 步骤:在win7 64位的机器上运行的,先启动TestBackLog,TestBackLog创建ServerSocket之后,会进入睡眠状态。马上再运行TcpClient,一旦客户端连上服务端,将会在控制台输出:client connected server
3. 观察现象并得出结论:当服务端创建服务之后,main线程会睡眠,会睡眠50秒,那如果现在运行TcpClient,将会创建10个客户端,这时将会出现什么情况?实际情况就是:在控制台只输出了三次:client connected server,那就意味着只有三个客户端连上服务端,刚好与backlog所设定的请求队列容量一致,后续的客户端再进行连接,则会抛出异常:java.net.ConnectException: Connection refused: connect(这是在windows会发生的情况,在mac上运行也是只有三次输出,但是其他的客户端没有被拒绝,而是直到连接超时)。当服务端睡眠结束,处理最初三个客户端的请求,之后再把后面的客户端请求处理完(前提是客户端的连接没有超时)。
这个实验刚好验证了请求的缓存队列,队列里的客户端已经跟服务端建立连接,等待服务端处理。但是后面未进入的队列的客户端,会进行new Socket(ip, port),还在苦苦地跟服务端进行连接啊~
https://blog.csdn.net/z69183787/article/details/81199836
最近碰到一个client端连接异常问题,然后定位分析并查阅各种资料文章,对TCP连接队列有个深入的理解
查资料过程中发现没有文章把这两个队列以及怎么观察他们的指标说清楚,希望通过这篇文章能把他们说清楚一点
问题描述
JAVA的client和server,使用socket通信。server使用NIO。
1.间歇性的出现client向server建立连接三次握手已经完成,但server的selector没有响应到这连接。
2.出问题的时间点,会同时有很多连接出现这个问题。
3.selector没有销毁重建,一直用的都是一个。
4.程序刚启动的时候必会出现一些,之后会间歇性出现。
分析问题
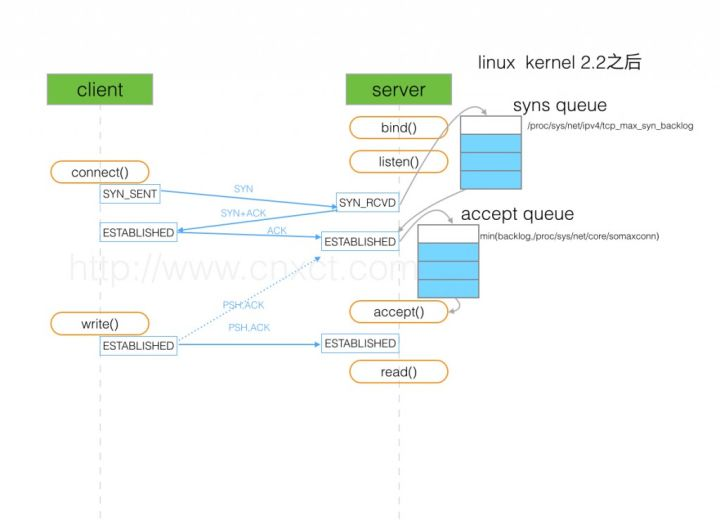
正常TCP建连接三次握手过程:
 image.png
image.png
- 第一步:client 发送 syn 到server 发起握手;
- 第二步:server 收到 syn后回复syn+ack给client;
- 第三步:client 收到syn+ack后,回复server一个ack表示收到了server的syn+ack(此时client的56911端口的连接已经是established)
从问题的描述来看,有点像TCP建连接的时候全连接队列(accept队列)满了,尤其是症状2、4. 为了证明是这个原因,马上通过 ss -s 去看队列的溢出统计数据:
667399 times the listen queue of a socket overflowed
反复看了几次之后发现这个overflowed 一直在增加,那么可以明确的是server上全连接队列一定溢出了
接着查看溢出后,OS怎么处理:
# cat /proc/sys/net/ipv4/tcp_abort_on_overflow
0
tcp_abort_on_overflow 为0表示如果三次握手第三步的时候全连接队列满了那么server扔掉client 发过来的ack(在server端认为连接还没建立起来)
为了证明客户端应用代码的异常跟全连接队列满有关系,我先把tcp_abort_on_overflow修改成 1,1表示第三步的时候如果全连接队列满了,server发送一个reset包给client,表示废掉这个握手过程和这个连接(本来在server端这个连接就还没建立起来)。
接着测试然后在客户端异常中可以看到很多connection reset by peer的错误,到此证明客户端错误是这个原因导致的。
于是开发同学翻看java 源代码发现socket 默认的backlog(这个值控制全连接队列的大小,后面再详述)是50,于是改大重新跑,经过12个小时以上的压测,这个错误一次都没出现过,同时 overflowed 也不再增加了。
到此问题解决,简单来说TCP三次握手后有个accept队列,进到这个队列才能从Listen变成accept,默认backlog 值是50,很容易就满了。满了之后握手第三步的时候server就忽略了client发过来的ack包(隔一段时间server重发握手第二步的syn+ack包给client),如果这个连接一直排不上队就异常了。
深入理解TCP握手过程中建连接的流程和队列

(图片来源:http://www.cnxct.com/something-about-phpfpm-s-backlog/)
如上图所示,这里有两个队列:syns queue(半连接队列);accept queue(全连接队列)
三次握手中,在第一步server收到client的syn后,把相关信息放到半连接队列中,同时回复syn+ack给client(第二步);
比如syn floods 攻击就是针对半连接队列的,攻击方不停地建连接,但是建连接的时候只做第一步,第二步中攻击方收到server的syn+ack后故意扔掉什么也不做,导致server上这个队列满其它正常请求无法进来
第三步的时候server收到client的ack,如果这时全连接队列没满,那么从半连接队列拿出相关信息放入到全连接队列中,否则按tcp_abort_on_overflow指示的执行。
这时如果全连接队列满了并且tcp_abort_on_overflow是0的话,server过一段时间再次发送syn+ack给client(也就是重新走握手的第二步),如果client超时等待比较短,就很容易异常了。
在我们的os中retry 第二步的默认次数是2(centos默认是5次):
net.ipv4.tcp_synack_retries = 2
如果TCP连接队列溢出,有哪些指标可以看呢?
上述解决过程有点绕,那么下次再出现类似问题有什么更快更明确的手段来确认这个问题呢?
netstat -s
[root@server ~]# netstat -s | egrep "listen|LISTEN"
667399 times the listen queue of a socket overflowed
667399 SYNs to LISTEN sockets ignored
比如上面看到的 667399 times ,表示全连接队列溢出的次数,隔几秒钟执行下,如果这个数字一直在增加的话肯定全连接队列偶尔满了。
ss 命令
[root@server ~]# ss -lnt
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 50 *:3306 *:*
上面看到的第二列Send-Q 表示第三列的listen端口上的全连接队列最大为50,第一列Recv-Q为全连接队列当前使用了多少
全连接队列的大小取决于:min(backlog, somaxconn) . backlog是在socket创建的时候传入的,somaxconn是一个os级别的系统参数
半连接队列的大小取决于:max(64, /proc/sys/net/ipv4/tcp_max_syn_backlog)。 不同版本的os会有些差异
实践验证下上面的理解
把java中backlog改成10(越小越容易溢出),继续跑压力,这个时候client又开始报异常了,然后在server上通过 ss 命令观察到:
Fri May 5 13:50:23 CST 2017
Recv-Q Send-QLocal Address:Port Peer Address:Port
11 10 *:3306 *:*
按照前面的理解,这个时候我们能看到3306这个端口上的服务全连接队列最大是10,但是现在有11个在队列中和等待进队列的,肯定有一个连接进不去队列要overflow掉
容器中的Accept队列参数
Tomcat默认短连接,backlog(Tomcat里面的术语是Accept count)Ali-tomcat默认是200, Apache Tomcat默认100.
#ss -lnt
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 100 *:8080 *:*
Nginx默认是511
$sudo ss -lnt
State Recv-Q Send-Q Local Address:PortPeer Address:Port
LISTEN 0 511 *:8085 *:*
LISTEN 0 511 *:8085 *:*
因为Nginx是多进程模式,也就是多个进程都监听同一个端口以尽量避免上下文切换来提升性能
进一步思考
如果client走完第三步在client看来连接已经建立好了,但是server上的对应连接实际没有准备好,这个时候如果client发数据给server,server会怎么处理呢?(有同学说会reset,还是实践看看)
先来看一个例子:
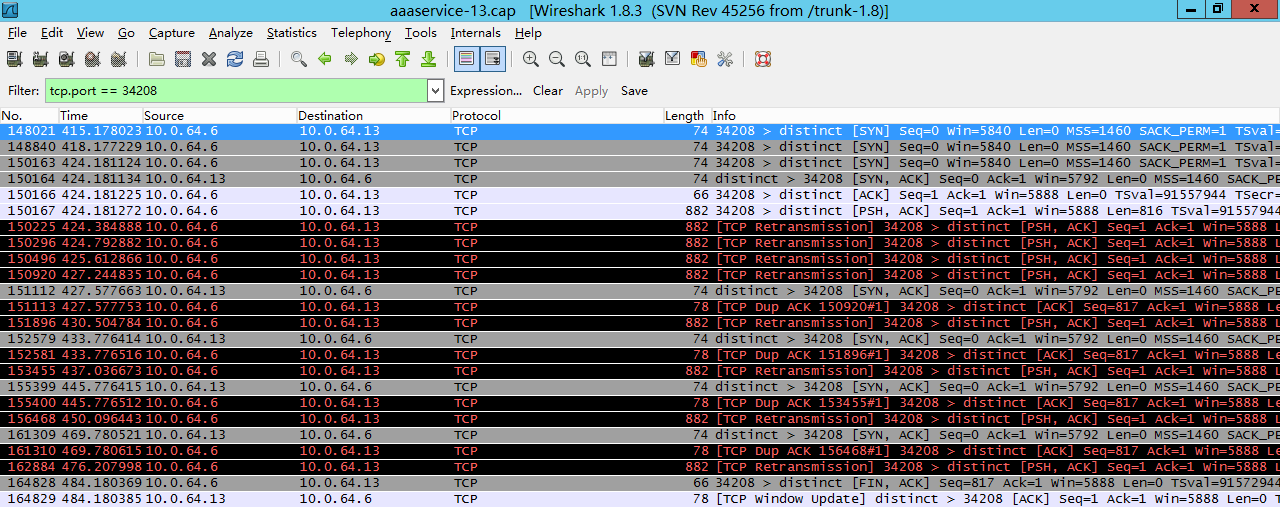 image.png
image.png
(图片来自:http://blog.chinaunix.net/uid-20662820-id-4154399.html)
如上图,150166号包是三次握手中的第三步client发送ack给server,然后150167号包中client发送了一个长度为816的包给server,因为在这个时候client认为连接建立成功,但是server上这个连接实际没有ready,所以server没有回复,一段时间后client认为丢包了然后重传这816个字节的包,一直到超时,client主动发fin包断开该连接。
这个问题也叫client fooling,可以看这里:https://github.com/torvalds/linux/commit/5ea8ea2cb7f1d0db15762c9b0bb9e7330425a071 (感谢浅奕的提示)
从上面的实际抓包来看不是reset,而是server忽略这些包,然后client重传,一定次数后client认为异常,然后断开连接。
过程中发现的一个奇怪问题
[root@server ~]# date; netstat -s | egrep "listen|LISTEN"
Fri May 5 15:39:58 CST 2017
1641685 times the listen queue of a socket overflowed
1641685 SYNs to LISTEN sockets ignored
[root@server ~]# date; netstat -s | egrep "listen|LISTEN"
Fri May 5 15:39:59 CST 2017
1641906 times the listen queue of a socket overflowed
1641906 SYNs to LISTEN sockets ignored
如上所示:
overflowed和ignored居然总是一样多,并且都是同步增加,overflowed表示全连接队列溢出次数,socket ignored表示半连接队列溢出次数,没这么巧吧。
翻看内核源代码(http://elixir.free-electrons.com/linux/v3.18/source/net/ipv4/tcp_ipv4.c):
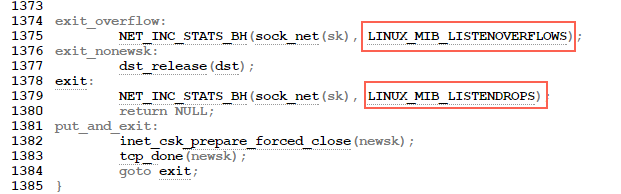 image.png
image.png
可以看到overflow的时候一定会drop++(socket ignored),也就是drop一定大于等于overflow。
同时我也查看了另外几台server的这两个值来证明drop一定大于等于overflow:
server1
150 SYNs to LISTEN sockets dropped
server2
193 SYNs to LISTEN sockets dropped
server3
16329 times the listen queue of a socket overflowed
16422 SYNs to LISTEN sockets dropped
server4
20 times the listen queue of a socket overflowed
51 SYNs to LISTEN sockets dropped
server5
984932 times the listen queue of a socket overflowed
988003 SYNs to LISTEN sockets dropped
那么全连接队列满了会影响半连接队列吗?
来看三次握手第一步的源代码(http://elixir.free-electrons.com/linux/v2.6.33/source/net/ipv4/tcp_ipv4.c#L1249):
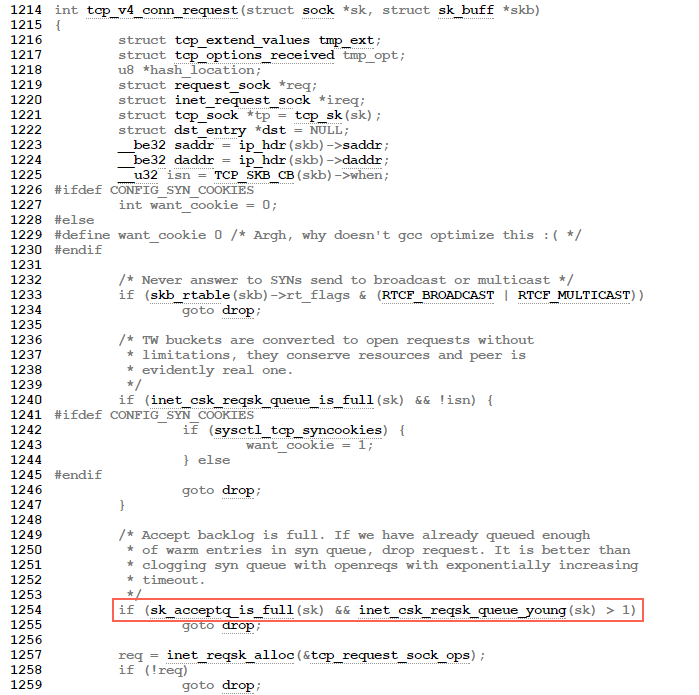 image.png
image.png
TCP三次握手第一步的时候如果全连接队列满了会影响第一步drop 半连接的发生。大概流程的如下:
tcp_v4_do_rcv->tcp_rcv_state_process->tcp_v4_conn_request
//如果accept backlog队列已满,且未超时的request socket的数量大于1,则丢弃当前请求
if(sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_yong(sk)>1)
goto drop;
总结
全连接队列、半连接队列溢出这种问题很容易被忽视,但是又很关键,特别是对于一些短连接应用(比如Nginx、PHP,当然他们也是支持长连接的)更容易爆发。 一旦溢出,从cpu、线程状态看起来都比较正常,但是压力上不去,在client看来rt也比较高(rt=网络+排队+真正服务时间),但是从server日志记录的真正服务时间来看rt又很短。
希望通过本文能够帮大家理解TCP连接过程中的半连接队列和全连接队列的概念、原理和作用,更关键的是有哪些指标可以明确看到这些问题。
另外每个具体问题都是最好学习的机会,光看书理解肯定是不够深刻的,请珍惜每个具体问题,碰到后能够把来龙去脉弄清楚。
参考文章:
http://veithen.github.io/2014/01/01/how-tcp-backlog-works-in-linux.html
http://www.cnblogs.com/zengkefu/p/5606696.html
http://www.cnxct.com/something-about-phpfpm-s-backlog/
http://jaseywang.me/2014/07/20/tcp-queue-%E7%9A%84%E4%B8%80%E4%BA%9B%E9%97%AE%E9%A2%98/
http://jin-yang.github.io/blog/network-synack-queue.html#
http://blog.chinaunix.net/uid-20662820-id-4154399.html
https://www.atatech.org/articles/12919
http://jm.taobao.org/2017/05/25/525-1/
How TCP backlog works in Linux
When an application puts a socket into LISTEN state using the listen syscall, it needs to specify a backlog for that socket. The backlog is usually described as the limit for the queue of incoming connections.

Because of the 3-way handshake used by TCP, an incoming connection goes through an intermediate state SYN RECEIVED before it reaches the ESTABLISHED state and can be returned by the accept syscall to the application (see the part of the TCP state diagram reproduced above). This means that a TCP/IP stack has two options to implement the backlog queue for a socket in LISTEN state:
{kind=link}
-
The implementation uses a single queue, the size of which is determined by the
backlogargument of thelistensyscall. When a SYN packet is received, it sends back a SYN/ACK packet and adds the connection to the queue. When the corresponding ACK is received, the connection changes its state to ESTABLISHED and becomes eligible for handover to the application. This means that the queue can contain connections in two different state: SYN RECEIVED and ESTABLISHED. Only connections in the latter state can be returned to the application by theacceptsyscall. -
The implementation uses two queues, a SYN queue (or incomplete connection queue) and an accept queue (or complete connection queue). Connections in state SYN RECEIVED are added to the SYN queue and later moved to the accept queue when their state changes to ESTABLISHED, i.e. when the ACK packet in the 3-way handshake is received. As the name implies, the
acceptcall is then implemented simply to consume connections from the accept queue. In this case, thebacklogargument of thelistensyscall determines the size of the accept queue.
Historically, BSD derived TCP implementations use the first approach. That choice implies that when the maximum backlog is reached, the system will no longer send back SYN/ACK packets in response to SYN packets. Usually the TCP implementation will simply drop the SYN packet (instead of responding with a RST packet) so that the client will retry. This is what is described in section 14.5, listen Backlog Queue in W. Richard Stevens’ classic textbook TCP/IP Illustrated, Volume 3.
Note that Stevens actually explains that the BSD implementation does use two separate queues, but they behave as a single queue with a fixed maximum size determined by (but not necessary exactly equal to) the backlog argument, i.e. BSD logically behaves as described in option 1:
The queue limit applies to the sum of […] the number of entries on the incomplete connection queue […] and […] the number of entries on the completed connection queue […].
On Linux, things are different, as mentioned in the man page of the listen syscall:
The behavior of the
backlogargument on TCP sockets changed with Linux 2.2. Now it specifies the queue length for completely established sockets waiting to be accepted, instead of the number of incomplete connection requests. The maximum length of the queue for incomplete sockets can be set using/proc/sys/net/ipv4/tcp_max_syn_backlog.
This means that current Linux versions use the second option with two distinct queues: a SYN queue with a size specified by a system wide setting and an accept queue with a size specified by the application.
The interesting question is now how such an implementation behaves if the accept queue is full and a connection needs to be moved from the SYN queue to the accept queue, i.e. when the ACK packet of the 3-way handshake is received. This case is handled by the tcp_check_req function in net/ipv4/tcp_minisocks.c. The relevant code reads:
child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL);
if (child == NULL)
goto listen_overflow;
For IPv4, the first line of code will actually call tcp_v4_syn_recv_sock in net/ipv4/tcp_ipv4.c, which contains the following code:
if (sk_acceptq_is_full(sk))
goto exit_overflow;
We see here the check for the accept queue. The code after the exit_overflow label will perform some cleanup, update the ListenOverflows and ListenDrops statistics in /proc/net/netstat and then return NULL. This will trigger the execution of the listen_overflow code in tcp_check_req:
listen_overflow:
if (!sysctl_tcp_abort_on_overflow) {
inet_rsk(req)->acked = 1;
return NULL;
}
This means that unless /proc/sys/net/ipv4/tcp_abort_on_overflow is set to 1 (in which case the code right after the code shown above will send a RST packet), the implementation basically does… nothing!
To summarize, if the TCP implementation in Linux receives the ACK packet of the 3-way handshake and the accept queue is full, it will basically ignore that packet. At first, this sounds strange, but remember that there is a timer associated with the SYN RECEIVED state: if the ACK packet is not received (or if it is ignored, as in the case considered here), then the TCP implementation will resend the SYN/ACK packet (with a certain number of retries specified by /proc/sys/net/ipv4/tcp_synack_retries and using an exponential backoff algorithm).
This can be seen in the following packet trace for a client attempting to connect (and send data) to a socket that has reached its maximum backlog:
0.000 127.0.0.1 -> 127.0.0.1 TCP 74 53302 > 9999 [SYN] Seq=0 Len=0
0.000 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
0.000 127.0.0.1 -> 127.0.0.1 TCP 66 53302 > 9999 [ACK] Seq=1 Ack=1 Len=0
0.000 127.0.0.1 -> 127.0.0.1 TCP 71 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
0.207 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
0.623 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
1.199 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
1.199 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 6#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
1.455 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
3.123 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
3.399 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
3.399 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 10#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
6.459 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
7.599 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
7.599 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 13#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
13.131 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
15.599 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
15.599 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 16#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
26.491 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
31.599 127.0.0.1 -> 127.0.0.1 TCP 74 9999 > 53302 [SYN, ACK] Seq=0 Ack=1 Len=0
31.599 127.0.0.1 -> 127.0.0.1 TCP 66 [TCP Dup ACK 19#1] 53302 > 9999 [ACK] Seq=6 Ack=1 Len=0
53.179 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
106.491 127.0.0.1 -> 127.0.0.1 TCP 71 [TCP Retransmission] 53302 > 9999 [PSH, ACK] Seq=1 Ack=1 Len=5
106.491 127.0.0.1 -> 127.0.0.1 TCP 54 9999 > 53302 [RST] Seq=1 Len=0
Since the TCP implementation on the client side gets multiple SYN/ACK packets, it will assume that the ACK packet was lost and resend it (see the lines with TCP Dup ACK in the above trace). If the application on the server side reduces the backlog (i.e. consumes an entry from the accept queue) before the maximum number of SYN/ACK retries has been reached, then the TCP implementation will eventually process one of the duplicate ACKs, transition the state of the connection from SYN RECEIVED to ESTABLISHED and add it to the accept queue. Otherwise, the client will eventually get a RST packet (as in the sample shown above).
The packet trace also shows another interesting aspect of this behavior. From the point of view of the client, the connection will be in state ESTABLISHED after reception of the first SYN/ACK. If it sends data (without waiting for data from the server first), then that data will be retransmitted as well. Fortunately TCP slow-start should limit the number of segments sent during this phase.
On the other hand, if the client first waits for data from the server and the server never reduces the backlog, then the end result is that on the client side, the connection is in state ESTABLISHED, while on the server side, the connection is considered CLOSED. This means that we end up with a half-open connection!
There is one other aspect that we didn’t discuss yet. The quote from the listen man page suggests that every SYN packet would result in the addition of a connection to the SYN queue (unless that queue is full). That is not exactly how things work. The reason is the following code in the tcp_v4_conn_request function (which does the processing of SYN packets) in net/ipv4/tcp_ipv4.c:
/* Accept backlog is full. If we have already queued enough
* of warm entries in syn queue, drop request. It is better than
* clogging syn queue with openreqs with exponentially increasing
* timeout.
*/
if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS);
goto drop;
}
What this means is that if the accept queue is full, then the kernel will impose a limit on the rate at which SYN packets are accepted. If too many SYN packets are received, some of them will be dropped. In this case, it is up to the client to retry sending the SYN packet and we end up with the same behavior as in BSD derived implementations.
To conclude, let’s try to see why the design choice made by Linux would be superior to the traditional BSD implementation. Stevens makes the following interesting point:
The backlog can be reached if the completed connection queue fills (i.e., the server process or the server host is so busy that the process cannot call
acceptfast enough to take the completed entries off the queue) or if the incomplete connection queue fills. The latter is the problem that HTTP servers face, when the round-trip time between the client and server is long, compared to the arrival rate of new connection requests, because a new SYN occupies an entry on this queue for one round-trip time. […]The completed connection queue is almost always empty because when an entry is placed on this queue, the server’s call to
acceptreturns, and the server takes the completed connection off the queue.
The solution suggested by Stevens is simply to increase the backlog. The problem with this is that it assumes that an application is expected to tune the backlog not only taking into account how it intents to process newly established incoming connections, but also in function of traffic characteristics such as the round-trip time. The implementation in Linux effectively separates these two concerns: the application is only responsible for tuning the backlog such that it can call accept fast enough to avoid filling the accept queue); a system administrator can then tune /proc/sys/net/ipv4/tcp_max_syn_backlog based on traffic characteristics.
http://veithen.io/2014/01/01/how-tcp-backlog-works-in-linux.html
细说SocketOption,就是要让你懂TCP
Java的Socket的API中所有控制TCP的SocketOptions
SO_KEEPALIVE setKeepAlive
SO_OOBINLINE setOOBInline
SO_RCVBUF setReciveBufferSize
SO_SNDBUF setSendBufferSize
SO_TIMEOUT setSoTimeOut
TCP_NODELAY setTcpNoDelay
SO_REUSEADDR setReuseAddress
/**
* Connects this socket to the server with a specified timeout value.
* A timeout of zero is interpreted as an infinite timeout. The connection
* will then block until established or an error occurs.
*
* @param endpoint the <code>SocketAddress</code>
* @param timeout the timeout value to be used in milliseconds.
* @throws IOException if an error occurs during the connection
* @throws SocketTimeoutException if timeout expires before connecting
* @throws java.nio.channels.IllegalBlockingModeException
* if this socket has an associated channel,
* and the channel is in non-blocking mode
* @throws IllegalArgumentException if endpoint is null or is a
* SocketAddress subclass not supported by this socket
* @since 1.4
* @spec JSR-51
*/
public void connect(SocketAddress endpoint, int timeout) throws IOException 三次握手,第二次syn+ack的超时时间
/**
* Create a server with the specified port, listen backlog, and
* local IP address to bind to. The <i>bindAddr</i> argument
* can be used on a multi-homed host for a ServerSocket that
* will only accept connect requests to one of its addresses.
* If <i>bindAddr</i> is null, it will default accepting
* connections on any/all local addresses.
* The port must be between 0 and 65535, inclusive.
* A port number of <code>0</code> means that the port number is
* automatically allocated, typically from an ephemeral port range.
* This port number can then be retrieved by calling
* {@link #getLocalPort getLocalPort}.
*
* <P>If there is a security manager, this method
* calls its <code>checkListen</code> method
* with the <code>port</code> argument
* as its argument to ensure the operation is allowed.
* This could result in a SecurityException.
*
* The <code>backlog</code> argument is the requested maximum number of
* pending connections on the socket. Its exact semantics are implementation
* specific. In particular, an implementation may impose a maximum length
* or may choose to ignore the parameter altogther. The value provided
* should be greater than <code>0</code>. If it is less than or equal to
* <code>0</code>, then an implementation specific default will be used.
* <P>
* @param port the port number, or <code>0</code> to use a port
* number that is automatically allocated.
* @param backlog requested maximum length of the queue of incoming
* connections.
* @param bindAddr the local InetAddress the server will bind to
*
* @throws SecurityException if a security manager exists and
* its <code>checkListen</code> method doesn't allow the operation.
*
* @throws IOException if an I/O error occurs when opening the socket.
* @exception IllegalArgumentException if the port parameter is outside
* the specified range of valid port values, which is between
* 0 and 65535, inclusive.
*
* @see SocketOptions
* @see SocketImpl
* @see SecurityManager#checkListen
* @since JDK1.1
*/
public ServerSocket(int port, int backlog, InetAddress bindAddr) throws IOException {
//backlog:半连接队列的长度,默认50
setImpl();
if (port < 0 || port > 0xFFFF)
throw new IllegalArgumentException(
"Port value out of range: " + port);
if (backlog < 1)
backlog = 50;
try {
bind(new InetSocketAddress(bindAddr, port), backlog);
} catch(SecurityException e) {
close();
throw e;
} catch(IOException e) {
close();
throw e;
}
}
方法和参数详解
一、setSoLinger
在Java Socket中,当我们调用Socket的close方法时,默认的行为是当底层网卡所有数据都发送完毕后,关闭连接
通过setSoLinger方法,我们可以修改close方法的行为
1,setSoLinger(true, 0)
当网卡收到关闭连接请求后,无论数据是否发送完毕,立即发送RST包关闭连接
2,setSoLinger(true, delay_time)
当网卡收到关闭连接请求后,等待delay_time
如果在delay_time过程中数据发送完毕,正常四次挥手关闭连接
如果在delay_time过程中数据没有发送完毕,发送RST包关闭连接
/**
* Specify a linger-on-close timeout. This option disables/enables
* immediate return from a <B>close()</B> of a TCP Socket. Enabling
* this option with a non-zero Integer <I>timeout</I> means that a
* <B>close()</B> will block pending the transmission and acknowledgement
* of all data written to the peer, at which point the socket is closed
* <I>gracefully</I>. Upon reaching the linger timeout, the socket is
* closed <I>forcefully</I>, with a TCP RST. Enabling the option with a
* timeout of zero does a forceful close immediately. If the specified
* timeout value exceeds 65,535 it will be reduced to 65,535.
* <P>
* Valid only for TCP: SocketImpl
*
* @see Socket#setSoLinger
* @see Socket#getSoLinger
*/
二、setKeepAlive
/**
* When the keepalive option is set for a TCP socket and no data
* has been exchanged across the socket in either direction for
* 2 hours (NOTE: the actual value is implementation dependent),
* TCP automatically sends a keepalive probe to the peer. This probe is a
* TCP segment to which the peer must respond.
* One of three responses is expected:
* 1. The peer responds with the expected ACK. The application is not
* notified (since everything is OK). TCP will send another probe
* following another 2 hours of inactivity.
* 2. The peer responds with an RST, which tells the local TCP that
* the peer host has crashed and rebooted. The socket is closed.
* 3. There is no response from the peer. The socket is closed.
*
* The purpose of this option is to detect if the peer host crashes.
* Valid only for TCP socket: SocketImpl
当建立TCP链接后,如果应用程序或者上层协议一直不发送数据,或者隔很长一段时间才发送数据,当链接很久没有数据报文传输时就需要通过keepalive机制去确定对方是否在线,链接是否需要继续保持。当超过一定时间没有发送数据时,TCP会自动发送一个数据为空的报文给对方,如果对方回应了报文,说明对方在线,链接可以继续保持,如果对方没有报文返回,则在重试一定次数之后认为链接丢失,就不会释放链接。
控制对闲置连接的检测机制,链接闲置达到7200秒,就开始发送探测报文进行探测。
net.ipv4.tcp_keepalive_time:单位秒,表示发送探测报文之前的链接空闲时间,默认为7200。
net.ipv4.tcp_keepalive_intvl:单位秒,表示两次探测报文发送的时间间隔,默认为75。
net.ipv4.tcp_keepalive_probes:表示探测的次数,默认9次。
三、backlog
详解:http://jm.taobao.org/2017/05/25/525-1/
————————————————
版权声明:本文为CSDN博主「gold_zwj」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zwjyyy1203/article/details/93932967