NameNode High Availability
Background
Hadoop2.0.0之前,NameNode存在单点失败(single point of failure) (SPOF) 问题。
出现单点失败的原因:
(1)NameNode所在的机器挂了;
(2)NameNode所在的机器需要硬件或者软件上的更新维护。
新的NameNode需要
(1)将FS Image加载到内存
(2)Replay edit log
(3)从DataNodes接收到足够的Block报告从而离开安全模式;
才能重新开始服务。
在包含大量文件和Blocks的大的集群中,namenode的冷启动可能需要30min或更久。
NameNode会定期将文件系统的命名空间(文件目录树、文件/目录元信息)保存到FS Image中,从而在NameNode因为掉电或者崩溃而宕机时,NameNode重启动之后可以从磁盘加载出FS Image文件重新构造命名空间。但是如果实时地将命名空间同步到FS Image中,将会消耗大量的系统资源,造成NameNode运行缓慢。因此,NameNode会先将命名空间的修改操作保存着在Edit Log中,然后定期合并FS Image和Edit Log。Hadoop 2.X之前,由Secondary NameNode进行FS Image和Edit Log的合并。Hadoop 2.X之后,由Standby NameNode进行合并,合并完再发送给Active NameNode。
Architecture
NameNode HA包含两个NameNode,在任意一个时刻,只有一个NameNode是的状态是Active,另一个是NameNode的状态是Standby,此外还包含ZooKeeper Failover Controller(ZKFC)、ZooKeeper以及共享编辑日志(share edit log)。 Active NameNode负责所有客户端对集群的操作, Standby NameNode作为slave,维护状态信息以便在提供快速的故障转移。如下图所示。
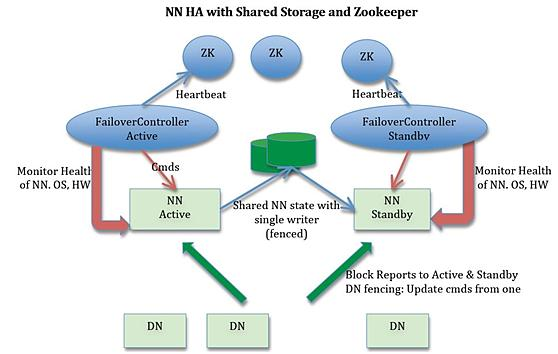
实现HA的流程
(1)集群启动后,一个NameNode处于Active的状态,提供服务,处理客户端和DataNodes的请求,并把修改写到edit log,然后将edit log写到本地和共享编辑日志(NFS、QJM等)。
共享编辑日志分两种:
1:如果是NFS,那么主、从NameNode访问NFS的一个目录或者共享存储设备,Active Node对namespace的修改记录到edit log中,然后将edit log存储到共享目录中。Standby NameNode将共享目录中的edit log 写到自己的namespace
2:如果是QJM,那么主、从NameNode与一组单独的称为Journal Nodes(JNs)的守护线程进行通信,Active Node将修改记录到大多数(> (N / 2) + 1,N是Journal Nodes的数量),Standby NameNode能够从JNs读到修改并写到自己的namespace中
(2)另外一个NameNode处于Standby状态,它启动时加载FS Image文件,Standby NameNode会不断将读入的edit log文件与当前的命名空间合并,从而始终保持着一个最新版本的命名空间,所以Standby NameNode秩序定期将自己的命名空间写入一个新的FS Image文件,并通过HTTP协议将这个FS Image文件传回Active NameNode即可。
在发生故障转移时,Standby节点需要确保自己已经从共享编辑日志读到了所有的edit log之后,才会变成Active节点。这保证了namespace状态的完全同步。
(3)为了实现Standby NameNode在Active NameNode失败之后能够快速提供服务,每个DataNode需要同时向两个NameNode发送块的位置信息和心跳【块报告(block report)】,因为NameNode启动最费时的工作就是处理所有DataNodes的块报告。为了实现热备,增加ZKFC和ZooKeeper,通过ZK选择主节点,Failover Controller通过RPC让NameNode转换为主或从。
(4)当Active NameNode失败时,Standby NameNode可以很快地接管,因为在Standby NameNode的内存中有最新的状态信息(1)最新的edit log(2)最新的block mapping
高可用的共享存储的两种选择:NFS和QJM
quorum journal manager(QJM)是HDFS专门的实现,唯一的目的就是提供高可用的edit log,是大多数HDFS的推荐选择。
QJM的工作过程:QJM运行一组journal nodes,每个edit必须被写入到majority的journal nodes中。通常,journal nodes的数量是3(至少是3个),因此每个edit必须被写入到至少两个journal nodes,允许一个journal nodes失败。【与ZooKeeper相似,但是QJM不是依赖ZooKeeper实现的】
使用 Fencing(隔离)来防止"split-brain"(脑裂)
Why Fencing?
slow network or a network partition可以触发故障转移,即使之前的Active NameNode仍然在正常运转并且认为它自己仍然是Active NameNode,这时HA就需要确保阻止这样的NameNode继续运行。
两种隔离
(1)通过隔离保证在同一时刻主NameNoel和从NameNode只有一个能够写 共享编辑日志
(2)DataNode隔离:对客户端进行隔离,要确保只有一个NameNode能够响应客户端的请求
对于HA集群来说,同一时刻只能有一个Active NameNode,否则namespace的状态很快就会发散成两个,造成数据丢失以及其他不正确的结果,即"split-brain"。为了防止这种情况发生,对于共享存储必须配置隔离(fencing)方法。在故障转移期间,如果不能判定之前的Active 节点放弃了他的Active状态,隔离处理负责切断切断之前的Active节点对共享编辑存储的访问,这就防止了之前Active节点对namespace的进一步编辑,从而使得新的Active节点能够安全地进行故障转移。(即一旦主NameNode失败,那么共享存储需要立即进行隔离,确保只有一个NameNode能够命令DataNodes。这样做之后,还需要对客户端进行隔离,要确保只有一个NameNode能够响应客户端的请求。让访问从节点的客户端直接失败,然后通过若干次的失败后尝试连接新的NameNode,对客户端的影响是增加一些重试时间,但对应用来说基本感觉不到。)
Why QJM recommended?
QJM在同一个时刻只允许一个NameNode写edit log;然而,之前的Active NameNode仍有可能为客户端的旧的读请求服务,此时可以设置SSH fencing命令来杀死NameNode的进程。
由于NFS不可能在同一个时刻只允许一个NameNode向它写数据,因此NFS需要更强的fencing方法,包括:
1、revoking the namenode’s access to the shared storage directory (typically by using a vendor-specific NFS command);
2、disabling its network port via a remote management command;
3、STONITH, or “shoot the other node in the head,” which uses a specialized power distribution unit to forcibly power down the host machine.
Failover Controller
从Active NameNode到Standby NameNode的转换通过Failover Controller实现。Hadoop的FC的默认实现是基于ZooKeeper的,从而确保只有一个Active NameNode。Failover Controller的作用是监控NameNode、操作系统、硬件的健康状态,如果出现NameNode的失败,则进行故障转移。
NOTE:HA集群中的Standby NameNode同时为namespace的状态执行检查点(HA上运行Secondary NameNode, CheckpointNode, or BackupNode是错误的)
参考:
(1)《Hadoop The Definitive Guide 4th》
(2)http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html