聚集索引:数据行的物理地址顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。
非聚集索引:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。(非聚集索引就像新华字典的偏旁字典,他结构顺序与实际存放顺序不一定一致)
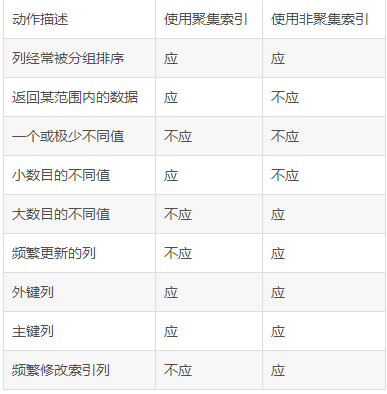
索引在MySQL中也叫做“键”或者"key"(primary key,unique key,还有一个index key),是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要,减少io次数,加速查询。(其中primary key和unique key,除了有加速查询的效果之外,还有约束的效果,primary key 不为空且唯一,unique key 唯一,而index key只有加速查询的效果,没有约束效果)
索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
强调:一旦为表创建了索引,以后的查询最好先查索引,再根据索引定位的结果去找数据
通常,我们会在每个表中都建立一个ID列,以区分每条数据,并且这个ID列是自动增大的,如果我们将这个列设为主键,SQL SERVER会将此列默认为聚集索引.
聚集索引的优势是很明显的,而每个表中只能有一个聚集索引的规则,这使得聚集索引变得更加珍贵。
从我们前面谈到的聚集索引的定义我们可以看出,使用聚集索引的最大好处就是能够根据查询要求,迅速缩小查询范围,避免全表扫描。在实际应用中,因为ID号是自动生成的,我们并不知道每条记录的ID号,所以我们很难在实践中用ID号来进行查询。这就使让ID号这个主键作为聚集索引成为一种资源浪费。其次,让每个ID号都不同的字段作为聚集索引也不符合“大数目的不同值情况下不应建立聚合索引”规则;当然,这种情况只是针对用户经常修改记录内容,特别是索引项的时候会负作用,但对于查询速度并没有影响。
1、添加主键索引:
创建的时候添加: 添加索引的时候要注意,给字段里面数据大小比较小的字段添加,给字段里面的数据区分度高的字段添加. 聚集索引的添加方式 创建的是添加
Create table t1( Id int primary key, ) Create table t1( Id int, Primary key(id) )
表创建完了之后添加 Alter table 表名 add primary key(id)
删除主键索引: Alter table 表名 drop primary key;
2、唯一索引: Create table t1( Id int unique, ) Create table t1( Id int, Unique key uni_name (id) )
表创建好之后添加唯一索引: alter table s1 add unique key u_name(id);
删除: Alter table s1 drop index u_name;
3、普通索引: 创建: Create table t1( Id int, Index index_name(id) )
Alter table s1 add index index_name(id);
Create index index_name on s1(id);
删除: Alter table s1 drop index u_name; DROP INDEX 索引名 ON 表名字;