Redis 全称: Remote Dictionary Service: 远程字典服务.
特点:
redis的存储格式是基于行存储数据, 是一个二维的模式.
Redis 的特性: 1)更丰富的数据类型 2)进程内与跨进程;单机与分布式 3)功能丰富:持久化机制、过期策略 4)支持多种编程语言 5)高可用,集群
Redis 的 Hash 本身也是一个 KV 的结构,类似于 Java 中的 HashMap。 外层的哈希(Redis KV 的实现)只用到了 hashtable。当存储 hash 数据类型时, 我们把它叫做内层的哈希。内层的哈希底层可以使用两种数据结构实现: ziplist:OBJ_ENCODING_ZIPLIST(压缩列表) hashtable:OBJ_ENCODING_HT(哈希表)
ziplist 是一个经过特殊编码的双向链表,它不存储指向上一个链表节点和指向下一 个链表节点的指针,而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能, 来换取高效的内存空间利用率,是一种时间换空间的思想。只用在字段个数少,字段值 小的场景里面。
quicklist(快速列表)是 ziplist 和 linkedlist 的结合体。
应用场景总结
缓存——提升热点数据的访问速度
共享数据——数据的存储和共享的问题
全局 ID —— 分布式全局 ID 的生成方案(分库分表)
分布式锁——进程间共享数据的原子操作保证
在线用户统计和计数
队列、栈——跨进程的队列/栈
消息队列——异步解耦的消息机制
服务注册与发现 —— RPC 通信机制的服务协调中心(Dubbo 支持 Redis)
购物车
新浪/Twitter 用户消息时间线
抽奖逻辑(礼物、转发)
点赞、签到、打卡
商品标签
用户(商品)关注(推荐)模型
电商产品筛选
排行榜
---------------
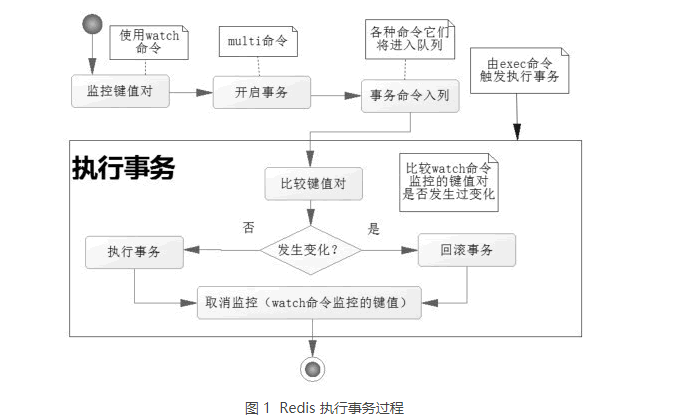
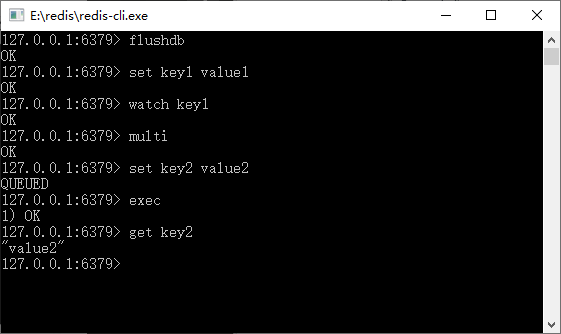
Redis 的事务有两个特点:
- 批量操作在发送 EXEC 命令前被放入队列缓存。
- 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
- 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
事务小结:
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
参照: http://c.biancheng.net/view/4544.html
Lua脚本
1、一次发送多个命令,减少网络开销。 2、Redis 会将整个脚本作为一个整体执行,不会被其他请求打断,保持原子性。 3、对于复杂的组合命令,我们可以放在文件中,可以实现程序之间的命令集复用。
单线程有什么好处呢?
1、没有创建线程、销毁线程带来的消耗
2、避免了上线文切换导致的CPU 消耗
3、避免了线程之间带来的竞争问题,例如加锁释放锁死锁等等
异步非阻塞I/O,多路复用处理并发连接。
Redis过期策略:
1. 定时过期(主动淘汰): 每个设置过期时间的key 都需要创建一个定时器,到过期时间就会立即清除。
优点: 对内存很友好,该策略可以立即清除过期的数据
缺点: 会占用大量的CPU 资源去处理过期的数据,从而影响缓存的响应时间和吞吐量.
2. 惰性过期(被动淘汰):
优点: 可以最大化优化CPU资源.
缺点: 对内存不优化, 极端情况下会出现大量过期的key,占用大量内存.
3. 定期过期: 每隔一定的时间,会扫描一定数量的数据库的expires 字典中一定数量的key,并清除其中已过期的key,
该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU 和内存资源达到最优的平衡效果。
AOF,RDB持久化方案的比较
如果可以忍受一小段时间内数据的丢失,毫无疑问使用RDB 是最好的,定时生成RDB快照(snapshot)非常便于进行数据库备份, 并且RDB 恢复数据集的速度也要比AOF 恢复的速度要快。否则就使用AOF 重写。
但是一般情况下建议不要单独使用某一种持久化机制,而是应该两种一起用,在这种情况下,当redis 重启的时候会优先载入AOF 文件来恢复原始的数据,因为在通常情况下AOF 文件保存的数据集要比RDB 文件保存的数据集要完整。