谁来执行Rebalance以及管理consumer的group呢
coordinator来执行对于consumer group的管理,当consumer group的第一个consumer启动的时候,它会去和kafka server确定谁是它们组的coordinator。之后该group内的所有成员都会和该coordinator进行协调通信
如何确定coordinator?
consumer group如何确定自己的coordinator是谁呢, 消费者向kafka集群中的任意一个broker发送一个GroupCoordinatorRequest请求,服务端会返回一个负载最小的broker节点的id,并将该broker设置为coordinator.
JoinGroup的过程
整个rebalance的过程分为两个步骤,Join和Sync
join: 表示加入到consumer group中,在这一步中,所有的成员都会向coordinator发送joinGroup的请求。一旦所有成员都发送了joinGroup请求,那么coordinator会选择一个consumer担任leader角色,并把组成员信息和订阅信息发送消费者
leader选举算法比较简单,如果消费组内没有leader,那么第一个加入消费组的消费者就是消费者leader,如果这个时候leader消费者退出了消费组,那么重新选举一个leader,这个选举很随意,类似于随机算法
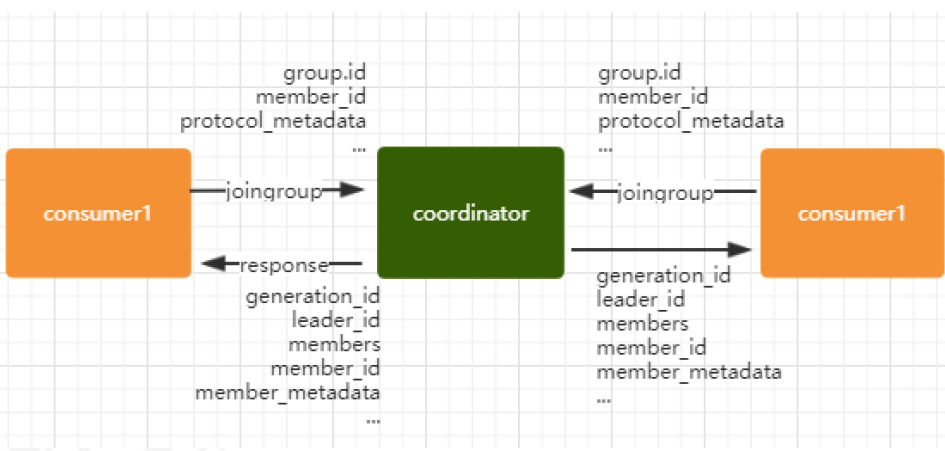
protocol_metadata: 序列化后的消费者的订阅信息
leader_id: 消费组中的消费者,coordinator会选择一个座位leader,对应的就是member_id
member_metadata 对应消费者的订阅信息
members:consumer group中全部的消费者的订阅信息
generation_id: 年代信息,类似于之前讲解zookeeper的时候的epoch是一样的,对于每一轮rebalance,generation_id都会递增。主要用来保护consumer group。隔离无效的offset提交。也就是上一轮的consumer成员无法提交offset到新的consumer group中。
确定分区分配策略
每个消费者都可以设置自己的分区分配策略,对于消费组而言,会从各个消费者上报过来的分区分配策略中选举一个彼此都赞同的策略来实现整体的分区分配,这个"赞同"的规则是,消费组内的各个消费者会通过投票来决定.
在joingroup阶段,每个consumer都会把自己支持的分区分配策略发送到coordinator,coordinator手机到所有消费者的分配策略,组成一个候选集,每个消费者需要从候选集里找出一个自己支持的策略,并且为这个策略投票
最终计算候选集中各个策略的选票数,票数最多的就是当前消费组的分配策略
Synchronizing Group State阶段
完成分区分配之后,就进入了Synchronizing Group State阶段,主要逻辑是向GroupCoordinator发送SyncGroupRequest请求,并且处理SyncGroupResponse响应,简单来说,就是leader将消费者对应的partition分配方案同步给consumer group 中的所有consumer
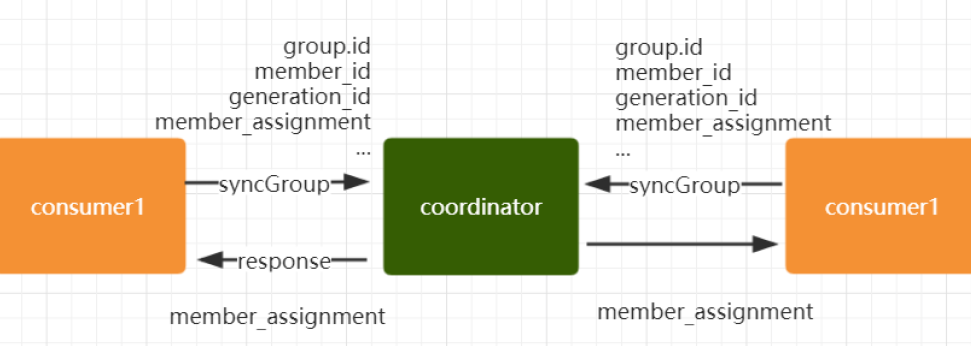
每个消费者都会向coordinator发送syncgroup请求,不过只有leader节点会发送分配方案,其他消费者只是打打酱油而已。当leader把方案发给coordinator以后,coordinator会把结果设置到SyncGroupResponse中。这样所有成员都知道自己应该消费哪个分区。
Ø consumer group的分区分配方案是在客户端执行的!Kafka将这个权利下放给客户端主要是因为这样做可以有更好的灵活性.
总结
我们再来总结一下consumer group rebalance的过程
- Ø 对于每个consumer group子集,都会在服务端对应一个GroupCoordinator进行管理,GroupCoordinator会在zookeeper上添加watcher,当消费者加入或者退出consumer group时,会修改zookeeper上保存的数据,从而触发GroupCoordinator开始Rebalance操作
- Ø 当消费者准备加入某个Consumer group或者GroupCoordinator发生故障转移时,消费者并不知道GroupCoordinator的在网络中的位置,这个时候就需要确定GroupCoordinator,消费者会向集群中的任意一个Broker节点发送ConsumerMetadataRequest请求,收到请求的broker会返回一个response作为响应,其中包含管理当前ConsumerGroup的GroupCoordinator,
- Ø 消费者会根据broker的返回信息,连接到groupCoordinator,并且发送HeartbeatRequest,发送心跳的目的是要要奥噶苏GroupCoordinator这个消费者是正常在线的。当消费者在指定时间内没有发送心跳请求,则GroupCoordinator会触发Rebalance操作。
Ø 发起join group请求,两种情况
- 如果GroupCoordinator返回的心跳包数据包含异常,说明GroupCoordinator因为前面说的几种情况导致了Rebalance操作,那这个时候,consumer会发起join group请求
- 新加入到consumer group的consumer确定好了GroupCoordinator以后,消费者会向GroupCoordinator发起join group请求,
- GroupCoordinator会收集全部消费者信息之后,来确认可用的消费者,并从中选取一个消费者成为group_leader。并把相应的信息(分区分配策略、leader_id、…)封装成response返回给所有消费者,但是只有group leader会收到当前consumer group中的所有消费者信息。
- 当消费者确定自己是group leader以后,会根据消费者的信息以及选定分区分配策略进行分区分配接着进入Synchronizing Group State阶段,
- 每个消费者会发送SyncGroupRequest请求到GroupCoordinator,但是只有Group Leader的请求会存在分区分配结果(Leader负责根据分区分配规则进行分区分配),GroupCoordinator会根据Group Leader的分区分配结果形成SyncGroupResponse返回给所有的Consumer。
- consumer根据分配结果,执行相应的操作
注: 参照自咕泡mic
kafka集群中的一个broker中最多只能有一个副本,leader副本所在的broker节点的 分区叫leader节点,follower副本所在的broker节点的分区叫follower节点, follow节点不支持client端的请求.
ISR副本:包含了leader副本和所有与leader副本保持同步的follower副本,注意是所有的副本,而不只是 leader副本。
LEO:即日志末端位移(log end offset),记录了该副本底层日志(log)中下一条消息的位移值。注意是下 一条消息!也就是说,如果LEO=10,那么表示该副本保存了10条消息,位移值范围是[0, 9]。另外, leader LEO和follower LEO的更新是有区别的。
HW:即上面提到的水位值。对于同一个副本对象而言,其HW值不会大于LEO值。小于等于HW值的所 有消息都被认为是“已备份”的(replicated)。同理,leader副本和follower副本的HW更新是有区别的 从生产者发出的 一 条消息首先会被写入分区的leader 副本,不过还需要等待ISR集合中的所有 follower副本都同步完之后才能被认为已经提交,之后才会更新分区的HW, 进而消费者可以消费 到这条消息。
ISR
ISR表示目前“可用且消息量与leader相差不多的副本集合,这是整个副本集合的一个子集”
一个新leader被选举并被接受客户端的消息成功写入。Kafka确保从同步副本列表中选举一个副本为 leader;leader负责维护和跟踪ISR(in-Sync replicas , 副本同步队列)中所有follower滞后的状态。当 producer发送一条消息到broker后,leader写入消息并复制到所有follower。消息提交之后才被成功复 制到所有的同步副本。
具体来说,ISR集合中的副本必须满足两个条件
1. 副本所在节点必须维持着与zookeeper的连接
2. 副本最后一条消息的offset与leader副本的最后一条消息的offset之间的差值不能超过指定的阈值 (replica.lag.time.max.ms) replica.lag.time.max.ms:如果该follower在此时间间隔内一直没有追 上过leader的所有消息,则该follower就会被剔除isr列表
3. ISR数据保存在Zookeeper的 /brokers/topics//partitions//state 节点中
follower副本把leader副本LEO之前的日志全部同步完成时,则认为follower副本已经追赶上了leader 副本,这个时候会更新这个副本的lastCaughtUpTimeMs标识,
kafk副本管理器会启动一个副本过期检 查的定时任务,这个任务会定期检查当前时间与副本的lastCaughtUpTimeMs的差值是否大于参数 replica.lag.time.max.ms 的值,如果大于,则会把这个副本踢出ISR集合