Redis
Redis(REmote Dictionary Service) 远程字典服务,最开始 Redis 只支持 List。
Redis的特性
对于Redis,我们大部分时候的认识是一个缓存的组件,只是在很多互联网应用里面,他作为缓存发挥了最大的作用。
要了解特性之前,需要先回答以下问题:
1.为什么要把数据放在内存中?
1)内存的速度更快,10w QPS
2)减少计算的时间,减轻数据库压力
2.如果使用内存的数据结构作为缓存,为什么不用HashMap或者Memcached?
1)更丰富的数据类型
2)支持多种编程语言
3)功能丰富:持久化机制、内存淘汰策略、事务、发布订阅、pipeline、lua
4)支持集群、分布式
3.Memcached和Redis的主要区别是什么?
Memcached只能存储KV、没有持久化机制、不支持主从复制、是多线程的。
Redis的6.0版本发布。
redis的基本数据类型
最基本也是最常用的数据类型就是String。set和get命令就是String的操作命令。
Reids的字符串被叫做二进制安全的字符串,为什么是Binary-safe Strings呢?
下面对于所有的数据类型我们都会从4个维度来分析:存储类型、操作命令、存储结构、应用场景。
String字符串
存储类型
可以用来存储INT(整数)、float(单精度浮点数)、String(字符串)。
操作命令
# 获取指定范围的字符
getrange snail 0 1
# 获取值长度
strlen snail
# 字符串追加内容
append snail good
# 设置多个值(批量操作,原子性)
mset snail 0 xiaobai 666
# 获取多个值
mget snail xiaobai
# 设置值。如果key存在,则不成功
setnx snail 11
# 基于此可实现分布式锁。用del key释放锁。
# 但如果释放锁的操作失败了,导致其他节点永远获取不到锁,怎么办?
# 加过期时间。单独用expire加过期,也失败了,无法保证原子性,怎么办?多参数
set key value [expiration EX seconds|PX milliseconds][NX|XX]
#使用参数的方式
set k1 v1 EX 10 NX
# (整数)值递增(值不存在会得到1)
incr snail
incrby snail 100
# (整数)值递减
decr snail
decrby snail 100
# 浮点数增量
set mf 2.6
incrbyfloat mf 7.3
存储(实现)原理
数据模型
Redis是KV的数据库。Key-Value我们一般会用什么结构存储呢?哈希表。Redis的最外层确实是通过hashTable实现的(我们把这个叫做外层的哈希)。
在Redis里面,这个哈希表怎么实现?C语言源码,每个键值对都是一个dictEntry,通过指针指向key的存储结构和value的存储结构,而且next存储了指向下一个键值对的指针。
# dict.h 47行
typedef struct dictEntry {
void *key;/* key关键字定义*/
union {
void *val; /* value定义 */
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; /*指向下一个键值对节点 */
} dictEntry;
实际上最外层是redisDb,redisDb里面放的是dict,后面hash我们会把这部分串起来,源码server.h 661行
typedef struct redisDb {
dict *dict; /* 所有的键值对 */ /* The keyspace for this DB */
dict *expires; /* 设置了过期时间的键值对 */ /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
这里以set hello word为例,因为key是字符串,Redis自己实现了一个字符串类型,叫做SDS,所以hello指向了一个SDS的结构。
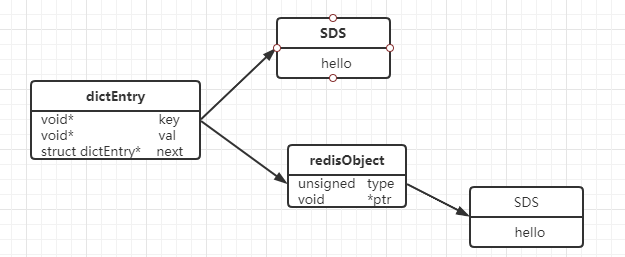
value是world,同样是一个字符串,是不是也用SDS存储呢?
当value存储一个字符串的时候,Redis并没有直接使用SDS存储,而是存储在redisObject中。实际上五种常用的数据类型的任何一种的value,都是通过redisObject来存储的。
最终redisObject再通过一个指针指向实际的数据结构,比如字符串或者其他。
redisObject定义:
//源码src/server.h 622行
typedef struct redisObject {
unsigned type:4; /* 对象的类型,包含:OBJ_STRING、OBJ_LIST、OBJ_HASH、OBJ_SET、OBJ_ZSET*/
unsigned encoding:4; /* 具体的数据结构 */
/* 24位, 对象最后一次被命名程序访问的时间,与内存回收有关 */
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount; /* 引用计数。当refcount为0的时候,表示该对象已经不被任何对象引用,则可以进行垃圾回收了 */
void *ptr; /* 指向对象实际的数据结构 */
} robj;
用type命令看到的类型就是type的内容:
type snail -> String
为什么一个value会有一钟对外的类型,还有一种实际的编码呢?我们刚才的字符串使用SDS存储,那么这个redisObject的value就会指向一个SDS:

那么实际的编码到底是什么呢?
内部编码
set number 1
set snail "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
set xiaobai yes
type number
type xiaobai
type snail
object encoding number
object encoding snail
object encoding xiaobai
虽然对外都是String,用的String的命令,但是出现了三种不同的编码。
这三种编码有什么区别呢?
1、int ,存储8个自己的长整型(long , 2^63-1)。
2、embstr,代表embstr格式的SDS,存储小于44个字节的字符串。
3、raw,存储大于44个字节的字符串。
/* object.c*/
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
QA:
1.SDS是什么?
Redis中字符串的实现,Simple Dynamic String简单动态字符串。
源码:sds.h 51行
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */ /* 当前字符数组的长度 */
uint8_t alloc; /* excluding the header and null terminator */ /* 当前字符串数据总共分配的内存大小*/
unsigned char flags; /* 3 lsb of type, 5 unused bits */ /* 当前字符数组的属性、用来标识到底是sdshdr8还是sdshdr16等 */
char buf[];/* 字符串真正的值 */
};
本质上其实还是字符数组。
SDS又有多种结构(sds.h):sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64,用于存储不同的长度的字符串,分别代表2^5=32byte, 2^8=256byte, 2^16=65536byte=64k, 2^32byte=4GB。
2、为什么Redis要用SDS实现字符串?
因为C语言没有字符串类型,只能用字符数组char[]实现。
1.使用字符数组必须先给目标变量分配足够的空间,否则可能会溢出。
2.如果要获取字符长度,必须遍历字符数组,时间复杂度O(n)。
3.C字符串长度的变更会对字符数组做内存重分配。
4.通过从字符串开始到结尾碰到的第一个'�'来标记字符串的结束,因此不能保存图片、音频、视频、压缩文件等二进制(bytes)保存的内容,二进制不安全。
SDS的特点:
1、不用担心内存溢出问题,如果需要会对SDS进行扩容。
2、获取字符串长度时间复杂度O(1),因为定义了len属性。
3、通过"空间预分配"(sdsMakeRoomFor)和"惰性空间释放",防止多次重分配内存。
4、判断是否结束的标志是len属性,可以包含'�'(它同样以'�'结尾是因为这样就可以使用C语言中函数库操作字符串的函数了)。
存储二进制:BytesTest.java
| c字符数组 | SDS |
|---|---|
| 获取字符串长度的复杂度为O(N) | 获取字符串长度的复杂度为O(1) |
| API是不安全的,可能会造成缓冲区溢出 | API是安全的,不会造成缓冲区溢出 |
| 修改字符串长度N次必然需要执行N次内存重分配 | 修改字符串长度N次最多需要执行N次内存重分配 |
| 只能保存文本数据 | 可以保存文本或者二进制数据 |
| 可以使用所有<string.h>库中的函数 | 可以使用一部分<string.h>库中的函数 |
3、embstr和raw编码的区别?为什么要为不同大小设计不同的编码?
embstr的使用只分配一次内存空间(因为RedisObject和SDS是连续的)。而raw需要分配两次内存空间(分别为RedisObject和SDS分配空间)。
因此与raw相比,embstr的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。
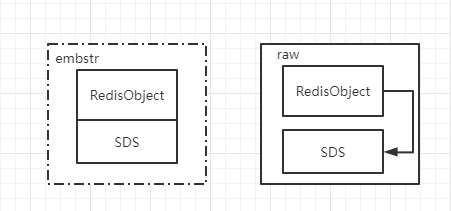
而embstr的坏处也很明显,如果字符串的长度增加需要重新分配内存是,整个RedisObject和SDS都需要重新分配空间,因此Redis中的embstr实现为只读(这种编码的内容是不能修改的)。
4.int和embstr什么时候转化为raw?
1、int数据不再是整数--raw
2、int大小超过了long的范围(2^63-1)--embstr
3、embstr长度超过了44个字节--raw
set k1 1
Object encoding k1
append k1 a
Object encoding k1
set k2 108213812381230812123
object encoding k2
set k3 108213812381230812124
object encoding k3
set k4 aaaaaaaaaaaabbbbbbbbbcccccccccccddddddeeee
object encoding k4
set k5 aaaaaaaaaaaabbbbbbbbbcccccccccccddddddeeeeeee
object encoding k5
set k6 a
object encoding k6
append k6 b
object encoding k6
上面的命令会发现一个问题:明明没有超过44个字节,为什么变成raw了?
前面分析了embstr的结构,由于它的实现是只读的,因此在对embstr对象进行修改时,都会先转化为raw在进行修改、
因此,只要是修改embstr对象,修改后的对象一定是raw的,无论是否到达44个字节。
5、当长度小于阈值的时候,会还原吗?
关于Redis内部编码的转换,都符合以下规律:编码转换在Redis写入数据时完成,且转换过程不可逆,只能从小内存编码向大内存编码转换(但是不包括重新set)。
6、为什么要对底层的数据结构使用redisObject进行一层包装呢?
其实无论是设计redisObject,还是对存储字符设计这么多的SDS,都是为了根据存储的不同内容选择不同的存储方式,这样可以实现尽量的节省内存空间和提升查询速度的目的。
应用场景:
- 缓存
- String类型,缓存热点数据。例如网站首页、报表数据等。
- 可以显著提升热点数据的访问速度。
- 分布式数据共享
- String类型,因为Redis是分布式的独立服务,可以在多个应用之间共享;
- 例如:分布式Session
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
- 分布式锁
- String类型的setnx方法,只有不存在时才能添加成功,返回true。
public Boolean getLock(Object lockObject){
jedisUtil = getJedisConnection();
boolean flag = jedisUtil.setNX(lockObject, 1);
if(flag){
expire(lockObject, 10);
}
return flag;
}
public void releaseLock(Object lockObject){
del(lockObject);
}
-
全局ID
- INT类型,INCRBY,利用原子性
- incrby userid 1000 (分库分表的场景,一次性拿一段)
-
计数器
- INT类型,INCR方法
- 例如:文章的阅读量,微博点赞数,允许一定的延迟,先写入Redis再定时同步到数据库。
-
限流
- INT类型,INCR方法
- 以访问者的IP和其他信息作为key,访问一次增加一次计数,超过次数则返回false。
总结:利用redis本身的特性,String内存的存储内容,以及提供的操作方式,我们可以用来达到很多的业务目的。
如果一个对象的value有多个值的时候,怎么存储?
例如用一个key存储一张表的数据。

序列化的方式?例如JSON/Protobuf/XML,会增加序列化和反序列化的开销,并且不能单独获取、修改一个值。
可以通过key分层的方式来实现,例如:
mset student:1:sno GP16666 student:1:sname 彪哥 student:1:company 京东
# 获取值的时候一次获取多个值,用list接受:
mget student:1:sno student:1:sname student:1:company
缺点: key太长,占用的空间太多。那么有没有好的方式呢?