CF
1 概述
协同过滤(Collaborative Filtering,CF)是推荐系统中最为流行和成熟的一种技术。协同过滤通常分为基于用户和基于项目的协同过滤的两种情况,通过考虑用户与用户之间、物品与物品之间的相似度,来对目标用户进行合适的推荐。在各大电商网站中得到广泛的青睐。例如亚马逊、淘宝、京东等。
在推荐系统中最常用的协同过滤包括:
- 基于用户的协同过滤
- 基于物品的协同过滤
- 基于模型的协同过滤
- 混合协同过滤
对于上述4种协同过滤,它们的应用场景各不相同。其中,基于用户的协同过滤和基于物品的协同过滤都是基于内存的协同过滤,对于数据量小的应用场景十分合适,可以在线进行实时推送。基于模型的协同过滤一般用于离线计算,它采用机器学习的方法,将用户的偏好行为分为2个数据集,一个为训练集,一个为测试集,使用训练集来训练出推荐模型,再使用测试集来评估模型的精度,当模型的精度满足阈值时,就可以将推荐模型应用于线上;混合协同过滤就是将上述3种推荐模型进行融合,可以克服每一种协同过滤本身的缺点,比如基于内存的协同过滤不适合大数据集,基于模型的协同过滤需要消耗大量的时间,不适合在线推荐场景。所以将两者的优点整合,创建出一种更加完美的推荐系统,使其更加具备应用和现实意义。
2 相似度计算
基于协同过滤的推荐方法,通过计算用户或者物品之间的相似度进行个性化推荐,对于相似度计算的问题,很多学者都提出了独特的见解,但是对于实际应用场景中,大多数推荐系统还是依赖于更加原始的相似度计算,因为最初的计算方法稳定性最好。下面对于常用的相似性计算方法进行介绍。
- 欧几里得距离
又称为欧式距离,在n维欧式空间中,用于计算坐标点之间的距离,计算公式如下:
其中,x,y表示两个点的坐标,d(x,y)表示点x与点y之间的距离
- 皮尔逊相关系数
用于计算两个数据集X,Y之间的距离,计算公式如下:
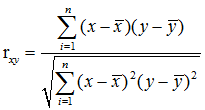
其中,n表示两个数据集X和Y中数据点的个数
用于计算两个向量的夹角的余弦值,表示两个向量的相识性,计算公式如下:

其中,A和B表示两个向量。
3 基于用户的协同过滤
基于用户的协同过滤,不考虑用户、物品的属性信息,直接根据用户对物品的喜爱程度进行推荐,发掘不同用户之间的喜爱相似性。它以用户为中心,通过比较与该用户兴趣相似的一个用户的群体,将这个兴趣的用户群体所感兴趣的其他物品,推荐给该用户。
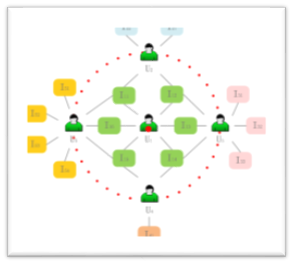
图1 基于用户的协同过滤
如图1所示,以用户U1为中心,用户U1对物品I12、I13、I14有偏好行为,用户U3对物品I12、I13、I14、I31、I32、I33有偏好行为,而物品I12、I13、I14是用户U1和用户U3共同有偏好行为的物品,那么可以将用户U3有偏好行为但是用户U1没有的物品I31、I32、I33推荐给用户U1。
3 基于物品的协同过滤
基于物品的协同过滤,不考虑用户、物品的属性信息,它也是根据用户对物品的喜爱程度,发掘不同物品之间的相似性。不同之处在于,它是以物品为中心,通过比较用户对物品的喜爱程度,将相似的物品计算出来,将这些相似的物品归属为一个类别,然后根据某个用户的历史兴趣计算所属的类别,观察该类别是否属于这些成组类别中的一个,最后将属于该类别所对应的其他物品推荐给该用户。

图2 基于物品的协同过滤
如图2所示,用户U1对物品I5和I6有偏好行为,用户U3对物品I1和I6有偏好行为,那么我们可以向U1推荐用户U3所感兴趣的物品I1。同样,用户U7对物品I3、I4、I7有偏好行为,用户U9对物品I4、I5、I7有偏好行为,那么我们可以向用户U7推荐用户U9所感兴趣的物品I5,因为用户U7和用户U9都对I4、I7有过偏好行为;可以向用户U9推荐用户U7感兴趣的物品I3,这个2个用户可能对彼此其他感兴趣的物品也都会发生偏好行为。
在群体的创建过程中,许多学者对此进行了研究,有基于k-means的聚类,基于标签主题的聚类等等。[1-2]
4 基于模型的协同过滤
基于模型的协同过滤,是采用机器学习的方法,离线计算出来的模型。假设,使用用户-物品的评分矩阵来实现推荐,定义评分矩阵R,那么将R分解为两个低秩矩阵U和M,由于R是稀疏矩阵,只能通过计算使用U和M的乘积近似计算R,为了满足实际需要,可以通过均方误差来作为衡量标准,即目标是使得RMSE最小。计算公式如下:
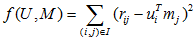
但是,在实际情况下要想使得目标函数最小,需要经过大量的迭代,时间效率是不允许的,因此可以允许一定的误差,在实际操作中,通过设定多个参数来进行控制。
矩阵分解的计算方法有许多种,如:随机梯度下降(Stochastic gradient descent, SGD)、交替最小二乘法(Altermatin Least Squares,ALS)、加权交替最小二乘法(ALS with Weighted- -Rugularization,ALS-WR)。这里采用ALS-WR实现矩阵分解,目标函数如下:
-Rugularization,ALS-WR)。这里采用ALS-WR实现矩阵分解,目标函数如下:

其中,
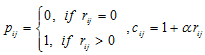
其中, 是置信参数,一般需要指定;
是置信参数,一般需要指定; 表示正则化参数,目的是为了防止模型过拟合。
表示正则化参数,目的是为了防止模型过拟合。
随后的步骤便是通过训练集和测试集确定推荐模型。
5 混合的协同过滤
在实际应用中,最常用的便是混合协同过滤,常用的混合协同过滤方法有以下几种[3]:
- 加权的混合:用线性公式将几种不同的推荐按照一定的权重组合起来,具体的权重需要在测试数据集上反复实验获得。
- 切换的混合:切换的混合就是根据不同的情况,选择合适的推荐算法进行推荐。
- 分区的混合:采用多种推荐机制,并采用不同的推荐结果分不同的区域显示给用户。
- 分层的混合:采用多种推荐机制,并采用一个推荐机制的结果作为另一个推荐算法的输入,运用层次法,进行计算。
参考文献
[1]肖文强,姚世军,吴善明. 一种改进的Top-N协同过滤推荐算法[J]. 计算机应用研究,2018,(01):1-7.
[2]文俊浩,袁培雷,曾骏,王喜宾,周魏. 基于标签主题的协同过滤推荐算法研究[J]. 计算机工程,2017,(01):247-258.