规则归纳
1 顺序化覆盖
大多数的规则推理系统都是使用一种叫做顺序化覆盖的算法。使用此算法的分类器维持着一组规则,叫做决策列表。
规则化覆盖的基本思想是顺序化的学习一系列的规则去覆盖训练数据。当一条规则产生以后,我们把这条规则所覆盖的所有的训练样例移除掉,然后使用剩下的训练样例继续寻找下一条规则。一条规则覆盖一个样例是指这个样例满足这条规则所描述的所有条件。
算法1 有序化的规则(Ordered Rules)
这个算法在学习一条规则的时候并不预先定义好学习哪个类的规则。在一次迭代之中,学习得到的规则可能是任何一个类的规则。因此,不同类的规则在最终的决策列表中顺序可能是交叉混合的。算法的详细描述如下:
Algorithm sequential-covering-1(D)
Rulelist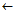
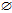
Rule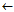 learn-one-rule-1(D)
learn-one-rule-1(D)
While Rule is not NULL AND D
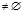 do
do
//一旦学习到一条规则,马上插入到RuleList中
Rulelist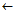 insert Rule at the end of RuleList
insert Rule at the end of RuleList
//移除掉所有被覆盖的样例
Remove from D the examples covered by Rule
Rule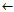 learn-one-rule-1(D)
learn-one-rule-1(D)
Endwhile
//dafult-class用于存储没有被学习到的规律
Insert a default class c at the end of RuleList,where c is the majority class in D
Return RuleList
算法最终生成的规则列表如下:
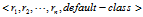
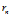 表示一条规则
表示一条规则
算法2 有序化的类(Ordered Classes)
这个算法学习完成一个类的所有规则,然后去学习另外一个类的规则。同一个类的所有规则都放在一起。它首先寻找的是出现频率最低的类的规则,然后再寻找出现频率次低的规则。保证了稀有类的规则也可能被挖掘到。
算法的具体流程如下:
Algorithm sequential-overing-2(D,C)
Rulelist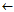

For each class 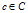 do
do
//Pos包含了D中所有类c的样例,Neg是D中剩余的样例。
Prepare data (Pos,Neg), Where Pos contains all the examples of class c from D, and Neg contains the rest of the examples in D
While Pos 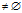 do
do
Rule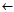 learn-one-rule-2(Pos,Neg,c)
learn-one-rule-2(Pos,Neg,c)
If Rule is NULL then
Exit-while-loop
Else RuleList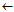 insert Rule at the end of RuleList
insert Rule at the end of RuleList
Remove examples covered by Rule from (Pos,Neg)
endif
endwhile
endfor
Return RuleList
使用规则进行分类
对于一个测试用例,我们按照规则列表中规则的顺序,逐个使用规则与测试用例进行匹配。第一个覆盖测试用例的规则所代表的类就是这个测试用例被分到的类。
2 规则学习
束搜索(beam search) 方法是解决优化问题的一种启发式方法,它是在分枝定界方法基础上发展起来的,它使用启发式方法估计k 个最好的路径,仅从这k 个路径出发向下搜索,即每一层只有满意的结点会被保留,其它的结点则被永久抛弃,从而比分枝定界法能大大节省运行时间。他的目标是并行地搜索几个潜在的最优决策路径以减少回溯,并快速地获得一个解。[1]
learn-One-Rule-1
这个算法使用Beam搜索,Beam的数目为k。BestCond用来存储算法要返回的规则。candidateCondSet存储当前最佳的条件集,它的大小应该小于或者等于k。newCandidateCondSet用来存储所有新的候选条件。
threshold用于评估是否它要比空集好;评估函数evalution()使用类似于决策树的熵函数。
算法如下:
Function learn-one-rule-1(D)
BestCond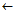
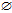
candidateCondSet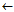 {BestCond}
{BestCond}
//op,离散数据是=;连续数据是{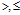 }
}
attributeValuePairs the set of all attribute-value pairs in D of the form(
the set of all attribute-value pairs in D of the form(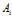 op v),
op v),
where 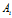 is an attribute and v is a value or an interval;
is an attribute and v is a value or an interval;
while candidateCondSet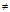
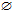 do
do
newCandidateCondSet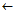
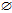 ;
;
for each candidate cond in candidateCondSet do
for each attribute-value pair a in attributeValuePairs do
newCond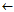 cond
cond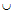 {a};
{a};
newCondidateCondSet newCandidateCondSet
newCandidateCondSet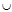 {newCond}
{newCond}
endfor
enfor
remove duplicates and inconsistencies,
for each candidate newCond in newCandidateCondSet do
if evaluation(newCond,D)>evaluation(BestCond,D) then
BestCond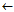 newCond
newCond
endif
endfor
candidateCondSet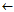 the k best members of newCondidateCondSet according to the results of the evaluation function;
the k best members of newCondidateCondSet according to the results of the evaluation function;
endwhile
if evaluation(BestCond,D)-evaluation(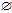 ,D)>threshold then
,D)>threshold then
return the rule:"BestCond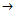 c" where is c the majority class of the data covered by BestCond
c" where is c the majority class of the data covered by BestCond
else return NULL
endif
learn-One-Rule-2
在该函数中,首先使用产生一条规则,然后进行剪枝操作。该方法中,首先将训练数据分为增长集和剪枝集。增长集,包括GrowPos和GrowNeg,用来产生一条规则,剪枝集,包括PrunePos和PruneNeg,用来对规则进行剪枝。
算法如下:
Function learn-one-rule-2(Pos,Neg,class)
split(Pos,Neg) into (GrowPos,GrowNeg) and (PrunePos,PruneNeg)
BestRule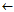 GrowRule (GrowPos,GrowNeg,class)
GrowRule (GrowPos,GrowNeg,class)
BestRule PruneRule (BestRule,PrunePos,PruneNeg)
PruneRule (BestRule,PrunePos,PruneNeg)
if the error rate of BestRule on (PrunePos,PruneNeg) exceeds 50% then
return NULL
endif
return BestRule
参考文献:
[1] http://blog.csdn.net/xiaozhuaixifu/article/details/9131821