- 如何有效管理应用的大量配置
目前现在应用的大量配置信息全部保存在xml文档中,方便修改和读取,Hadoop同样采取这样的方式。
那么让我们来看看Hadoop是如何管理自己的配置信息的。
Hadoop中管理配置信息的类为:

configuration类实现了iterable接口,该接口返回一个iterator类,这样就可以从集合的开始位置遍历元素

可以看出整个配置信息的管理类就是一个大的hashmap
可以看出整个配置信息的管理类就是一个大的hashtable(通过getProps知道容器为properties类,而此类为hashtable的子类。)
那么这里为什么不直接取hashtable的iterator?通过注释知道,由于getProps方法得到的配置信息可能包含非string to string的key-value对,所以要将这些过滤掉(另见hashmap与hashtable的源码分析)
那么configuration是如何从xml文件读取配置信息并装入hashtable的?
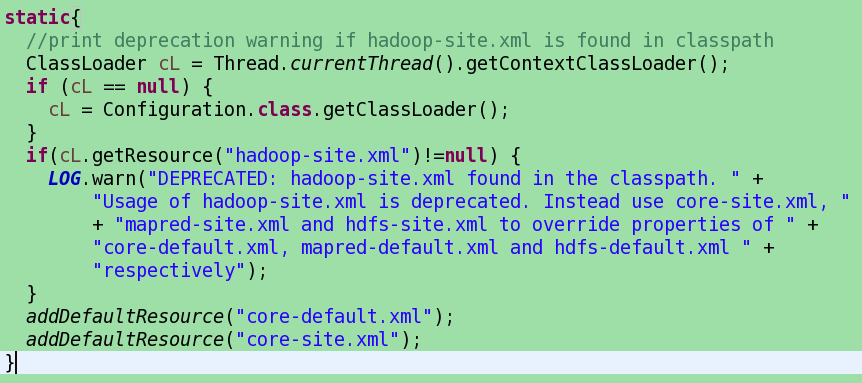
通过上面代码可以看出configuration类在其静态初始化块中创建classloader,并在classpath中加入默认的配置文件名。也就是说在Hadoop运行的classpath中只要有上述文件名的配置文件都会起作用。
下面是具体读取xml配置的代码
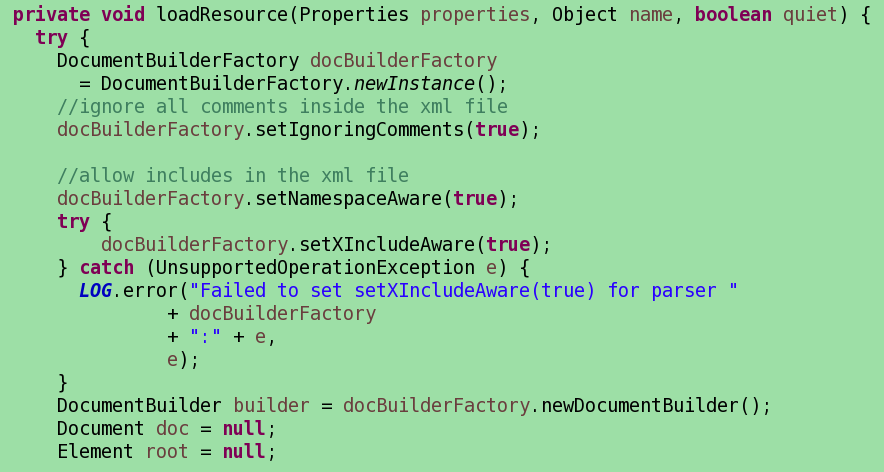

通过classloader获取xml的url,通过documentbuilder将xml解析成为dom树,接下来自然就是获取所有子节点并装入properties咯

整个配置文件的结构为configuration为dom树,每个配置项以propertiy标记,并且设置final的配置项不能修改
程序将xml配置信息读取后,应用程序如何获取到这些配置呢,configuration提供了get(String)方法,该方法既可以查找普通字符窜,还能查找类似${var}的系统环境变量

上面的正则表达式编译后为 ${[^}$s]+}
翻译成文法即为:
俩个字符为${,接着是除了}和$和空格一个或多个其他字符,然后是}完成一次匹配