昨天刚刚把MNIST的代码在电脑上运行,还没有仔细看代码的含义,今天就跟着中文官网一起继续。
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片,也包含每一张图片对应的标签,告诉我们这张图片是数字几。
MNIST数据集
首先我们可以通过python的源代码用于自动下载和安装这个数据集。
import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
下载下来的数据集被分成两部分:60000行的训练数据集( mnist.train )和10000行的测试数据集( mnist.test )。
每一个MNIST数据单元都有两部分组成:一张包含手写数组的图片和一个对应的标签。我们把这些图片设为"xs",把这些标签设为”ys"。寻训练数据集和测试数据集都包含xs和ys,比如训练数据集的图片是mnist.train.images ,训练数据集的标签是mnist.train.labels。
每一张图片包含28像素X28像素。我们可以用一个数字数组来表示这张图片: 我们把这个数组展开成一个向量,长度是28x28 = 784。,在MNIST训练数据集中,mnist.train.imags是一个形状为[60000,784]的张量,第一个维度数字用来索引图片,第二个纬度数字用来索引每张图片中的像素点。因此张量里的每一张元素,都表示某张图片里的某个像素的强度值,值介于0和1之间。
我们把这个数组展开成一个向量,长度是28x28 = 784。,在MNIST训练数据集中,mnist.train.imags是一个形状为[60000,784]的张量,第一个维度数字用来索引图片,第二个纬度数字用来索引每张图片中的像素点。因此张量里的每一张元素,都表示某张图片里的某个像素的强度值,值介于0和1之间。
相对应的MNIST数据集的标签是介于0到9的数字,用来描述给定图片里表示的数字,为了用于这个教程,我们使标签数据是“one-hot vectors"。一个one-hot向量除了是某一一位的数字似乎1以外其余各维度数组都是0.所以在此教程总,数字n将表示成一个只有在第维度(从0开始)数字为1的10维向量。比如,标签0将表示成([1,0,0,0,0,0,0,0,0,0])。因此,mnist.train.labels是一个[60000,10]的数字矩阵。
softmax回归
我们使用softmax回归其实就是来给不同的对象分配概率。
softmax回归分为两步:
第一步:
为了得到一张给定图片属于某个特定数字类的证据,我们对图片像素值进行加权求和。如果这个像素有很轻的证据说明这张图片不属于该类,那么相应的权值为负数,反之,权值是正数。
此外,我们还需要一个额外的偏置量,因为输入往往会带有一些无关的干扰量。
可得softmax模型函数
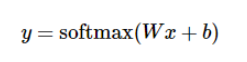
(详见:http://www.tensorfly.cn/tfdoc/tutorials/mnist_beginners.html)
实现回归模型
首先,导入Tensorflow
import tensorflow as tf
创建可操作的交互单元
x = tf.placeholder("float", [None, 784])
#x是一个占位符placeholder,在运行计算时具体输入x的值
#[None, 784]表示张量形状
#None表示此张量的第一个维度可以时任何长度的
设权重值和偏置量
W = tf.Variable(tf.zeros([784,10])) b = tf.Variable(tf.zeros([10])) # Variable 代表一个可修改的张量 #全为零的张量用来初始化w和b, # W 的维度是[784,10] # b 的形状是[10]
实现模型
y = tf.nn.softmax(tf.matmul(x,W) + b) # tf.matmul(X,W) 表示 x 乘以 W
训练模型
这里使用交叉熵来评估这个模型
#训练模型
#添加一个新的占位符用于输入正确值
y_ = tf.placeholder("float", [None,10])
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
#要求TensorFlow用梯度下降算法以0.01的学习速率最小化交叉熵
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
#始化我们创建的变量
init = tf.initialize_all_variables()
#启动模型并初始化变量
sess = tf.Session()
sess.run(init)
#训练模型,让模型循环训练1000次
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
评估模型
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
#确定正确预测项的比例
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
#计算所学习到的模型在测试数据集上面的正确率
print (sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))