实现一个功能,截一张图片,利用百度文字识别技术识别出图片内容,然后利用在线翻译网站翻译此内容。
实现此功能的前提是电脑有截屏功能,此文利用的是QQ截屏的功能,当然也可以使用微信截屏功能等,只不过快捷键不同罢了。
第一步,清空剪切板,需要导入from ctypes import windll, c_int这些方法,剪切板中的图片存放在内存中。
# ============== 清空剪切板, c_int(0)内存中的存储区域 user32 = windll.user32 # 打开剪切板 user32.OpenClipboard(c_int(0)) # 清空剪切板 user32.EmptyClipboard() # 关闭剪切板 user32.CloseClipboard()
第二步,截屏,因为用的QQ截屏,所以快捷键是ctrl+alt+a,wait()函数会在此阻塞,直到你按下截屏键才会往下继续
# 检测键盘按下,没检测到按下截图键,继续等待,检测到了,代码往下走。此处有个阻塞 keyboard.wait(hotkey="ctrl+alt+a")
# 获取图片内容 while True: image = ImageGrab.grabclipboard() if image: image.save(img_path) break else: time.sleep(2)
注意:为什么要用while True,截屏是不是需要时间去选区域,然后点完成,在这期间,剪切板上是没有数据的,用while True只是不断的从剪切板扫描图片而已,当发现图片就退出循环了。
第三步,图片转文字,这个是使用的百度api,另外写的一个py文件中。
word = get_text_from_image("screen.png")
第四步,翻译文本
result = requests.post( url="http://fy.iciba.com/ajax.php?a=fy", data={"f": "auto", "t": "auto", "w": word} ).json()
如此几步,就可以完成一个简单的图片翻译过程了。
百度api,自己可以注册申请账号,创建AppId、API Key、Secret Key,然后开始图片转文本工作,推荐博客:https://blog.csdn.net/student_zz/article/details/91491955?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
Python文字识别快速入门链接:https://ai.baidu.com/ai-doc/OCR/Dk3h7yf8m
不过我倒是没有创建新的AppId、API Key、Secret Key,直接用的博客主分享出来的,谢谢博客主的分享,链接:https://blog.csdn.net/qq_33333654/article/details/102723118
源码
translation.py


#!/usr/bin/env python # _*_ coding: UTF-8 _*_ """================================================= @Project -> File : six-dialog_design -> translation.py @IDE : PyCharm @Author : zihan @Date : 2020/5/26 18:10 @Desc : 1. 清空剪切板 2. 监测键盘按键"ctrl_alt+a", 阻塞程序直到得到截图 3. 将图片中的文字提取出来,用的是百度云的api 4. 翻译文字,用的是网页上在线翻译的接口:http://fy.iciba.com/ =================================================""" import requests from ctypes import windll, c_int from PIL import ImageGrab import keyboard import time from aip_baidu_img2text_recognition import get_text_from_image from pprint import pprint # 清空剪切板 def clear_clipboard(): # ============== 清空剪切板, c_int(0)内存中的存储区域 user32 = windll.user32 # 打开剪切板 user32.OpenClipboard(c_int(0)) # 清空剪切板 user32.EmptyClipboard() # 关闭剪切板 user32.CloseClipboard() # 获取截图 def get_image(img_path): # 获取图片内容 while True: image = ImageGrab.grabclipboard() if image: image.save(img_path) break else: time.sleep(2) # 翻译文本 def translation(word): result = requests.post( url="http://fy.iciba.com/ajax.php?a=fy", data={"f": "auto", "t": "auto", "w": word} ).json() return result def main(): # 清空剪切板 clear_clipboard() # 检测键盘按下,没检测到按下截图键,继续等待,检测到了,代码往下走。此处有个阻塞 keyboard.wait(hotkey="ctrl+alt+a") # 得到截屏的图片存放到剪切板 get_image("screen.png") print("开始识别!") # 获取图片中的文字 word = get_text_from_image("screen.png") # 翻译文字 result = translation(word) # pprint(result) # 中文转英文 print(result["content"]["out"]) # 英文转中文 # print(result["content"]["word_mean"]) if __name__ == '__main__': main()
aip_baidu_img2text_recognition.py
#!/usr/bin/env python # _*_ coding: UTF-8 _*_ """================================================= @Project -> File : six-dialog_design -> aip_baidu_img2text_recognition.py @IDE : PyCharm @Author : zihan @Date : 2020/5/26 18:44 @Desc :借用api:https://blog.csdn.net/qq_33333654/article/details/102723118 文字识别接口说明:https://ai.baidu.com/ai-doc/OCR/Dk3h7yf8m =================================================""" from aip import AipOcr """你的 APPID AK SK""" APP_ID = "17593750" API_KEY = "VExogNuAiDslahMNe2uRn5IB" SECRET_KEY = "zILi6zsRwgKa1dTmbv2Rw8uG1oPGyI9A" client = AipOcr(APP_ID, API_KEY, SECRET_KEY) def get_text_from_image(image_path): if isinstance(image_path, bytes): image = image_path else: with open(image_path, "rb") as f: image = f.read() result_data = client.basicAccurate(image) # print(result_data) result_str = "" if result_data["words_result"]: for data in result_data["words_result"]: result_str += data['words'] else: result_str = "No content" return result_str
成功,目前只试过截取单词或者中文词组,没有试过句子,哈哈哈。
至于为什么用post,看图,在哪儿看就不多说了,自己尝试翻译一个单词就知道了。

post哪些数据来源, 继续看图
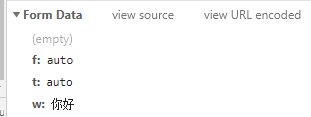
可以看出,当前需要翻译的数据是"你好"。