数字 int
主要是用于计算的,常用的方法有一种
#既十进制数值用二进制表示时,最少使用的位数
i = 3#3的ASCII为:0000 0011,即两位 s = i.bit_length() print(s)

布尔值
bool True/False
while True:
等价于:
while 1: ###较简便
while 1: print('all trule')

字符串
str 字符串的索引与切片
索引:索引既下标,字符串元素从第一个开始,初始索引为0。以此类推。
s = 'sdfjskjdfl' print(s[0]) print(s[2])

切片:通过索引截取字符串的一段,形成新的字符串。原则:顾首不顾尾。(索引:索引:步长)默认步长为1
print(s[0:2]) print(s[0:4:2]) print(s[:]) #取完 print(s[3:0:-1]) #倒着取,注意,3在0后,方向也必须反向

字符串常用方法:
capitalize():
s = 'sdfjskjdfl' s1 = s.capitalize()#字符串首字母大写 print(s1)

swapcase()
s = 'sdfSKFKKskdfjl' s2 = s.swapcase() #大小写翻转 print(s2)

title()
包括 特殊字符 和 数字 后的字符首字母也是大写
print('here you are'.title()) #每个单词的首字母大写

s = 'afsdf,fsdfsdf.sdf#fsdsg%fs456.2' print(s.title())

center
格式:center(width,'填充物')
print('123'.center(20,'#')) #内容居中,根据长度进行填充,默认填充物是空格

count()
print('name'.count('n')) #字符串中的元素出现的次数 print('name123name123name'.count('n',2,-1)) #可进行切片操作,想取到最后一位是:.count('str',start[int]),后面不要接end[int]就可以了

expandtabs()
print('123 456'.expandtabs())#将 前面的补全,默认将一个tab键变成8个空格,补足为8位;若超8个,则补全16个,以此类推

startswith() 和 endswith()
print('ggasds'.startswith('g'))#判断是否以...开头 print('ggasds'.endswith('s'))#判断是否以...结尾 print('ggasds'.startswith('gg',0,4))#顾首不顾尾 print('ggasds'.endswith('ds',-3))#顾首不顾尾
print('ggasds'.endswith('ds',-3,-1))#顾首不顾尾

find()
print('asdhjksdf'.find('dh',2,5))
print('asdhjksdf'.find('dh',1,3))
print('asdhjksdf'.find('xiao'))

注意:返回的是元素的索引,即'dh'索引,为2。如果找不到则返回-1。可用作判断
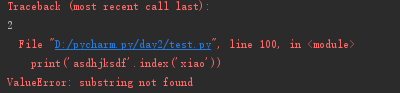
index()
相关方法:index() 找得到返回,找不到则报错。
print('asdhjksdf'.index('dh',2,5)) print('asdhjksdf'.index('xiao'))
split()
str------>list
print('sdfjskdfjsdfllj234j'.split('df'))#以什么进行分割,形成一个列表不包含此分割元素 s = 'title,Tilte,atre,'.rsplit('t',1)#从右边开始,只对第一个操作元素进行分割处理 print(s)

format
format的三种玩法:格式化输出
s = '''name:{} age:{} job:{}'''.format('kk',12,'stu') print(s)

s = 'name:{0},age:{1},job:{2},full-name:{0},real-age:{1},present-job:{2}'.format('dd','10','tea') print(s)

s = 'name:{name},age:{age},job:{job},full-name:{name},real-age:{age},present-job:{job}'.format(age='10',job='tea',name='dd') print(s)#后面变量位置随意调动

strip()
print(' sfsfs '.strip())#去除空格 print('***sdf****'.strip('*'))#去除* print(' sdfdfsd****'.lstrip())#去除左边空格 print(' sdfdfsd****'.rstrip('*'))#去除右边* print('%****&&12%*3%***'.strip('%*'))#只要左右两边出现包含在里面的任意一个字符,就去除 ###遇到不是被去除的字符就终止

replace()
print('i have a dream'.replace('dream','apple'))#全局替换 print('i have a dream,i dream one day...'.replace('dream','apple',1))#只替换第一个匹配到的字符
isalpha() isdigit() isalnum()
print('name123'.isalpha())#只由字母组成 print('name123'.isdigit())#只由数字组成 print('name123'.isalnum())#由字母或数字组成

列表 list
最常用的数据类型,以 [ ] 括起来,每个元素用逗号隔开,里面可以存放各种数据类型,即数据项不需要具有相同的类型。有序,可索引(从0开始)、切片
list1 = ['physics', 'chemistry', 1997, 2000] list2 = [1, 2, 3, 4, 5 ] list3 = ["a", "b", "c", "d"]
print(list1)
print(list2[2])
print(list3[0:3:2])#2是步长

元组tuple
被称为只读列表,以( )括起来,数据只能被查询,不能修改,同样可以进行切片操作。
tup1 = ('physics', 'chemistry', 1997, 2000) tup2 = (1, 2, 3, 4, 5 ) tup3 = "a", "b", "c", "d"
序列都可以进行的操作包括索引,切片,加,乘,检查成员。
列表 list [ ] [ ] [ ] [ ] ================元组tuple ( )( )( )( )
列表的详细操作以及更多数据类型见下一篇:python学习日记(基础数据类型及其方法02)