总介:缓存穿透(查不到)、缓存击穿(量太大,缓存过期)、缓存雪崩
1.缓存穿透
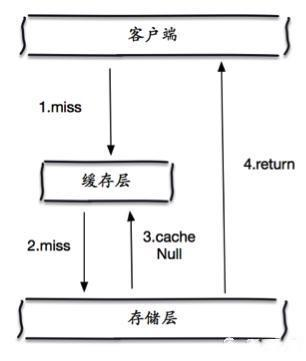
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中(秒杀!),于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
解决方式:
(1)缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同时设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源;
但是这种方法会存在俩个问题:
- 如果空置能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多空值的键;
- 即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响;
(2)布隆过滤器
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免对底层存储系统的查询压力;

2.缓存击穿(量太大,缓存过期)
缓存击穿和缓存穿透的区别,缓存击穿是指一个key非常热点,在不停的扛着大并发,大并发集中对这个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就想在一个屏障上凿开一个洞。
当某个可以在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,会同时访问数据库来查询最新数据,并且会写缓存,会导致数据库瞬间压力过大
解决方案:
(1)设置热点数据永不过期
从缓存层面来看,没有设置过期时间,所以不会出现热点key过期后产生的问题;
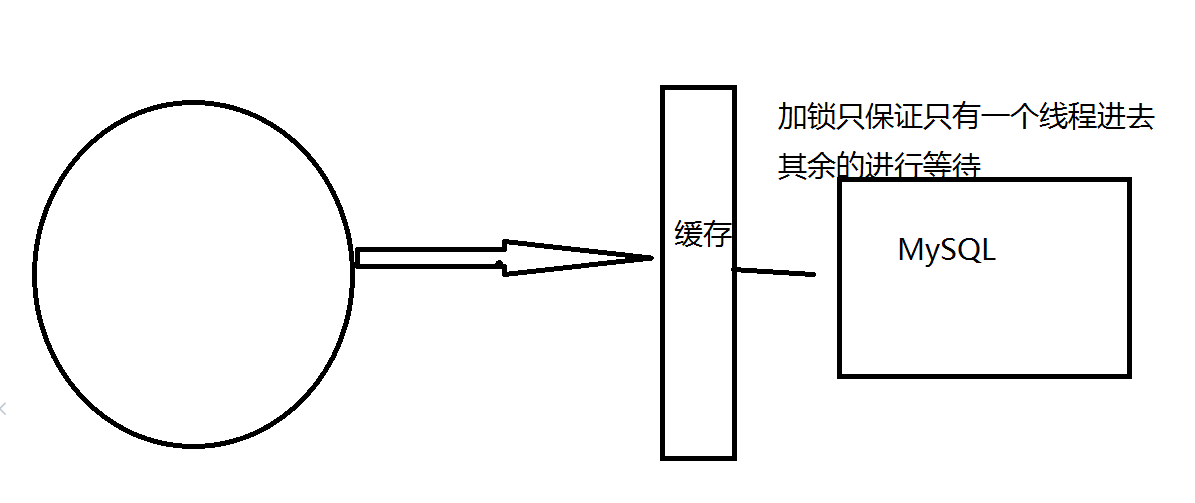
(2)加互斥锁
分布式锁:使用分布式锁,保证对于每一个key同时只有一个线程去查询后端服务,其它线程没有获得分布式锁的权限,因此只需要等待即可,这种方式将高并发的压力转移到了分布式锁,因此对分布式的考验很大。
3.缓存雪崩
缓存雪崩,是指在某一个时间段,缓存集中过期失效,Redis宕机。
产生雪崩的原因之一,比如在双十一,抢购商品时间比较集中,假设对这些商品进行缓存一小时,一小时之后,这批商品的缓存过期,而对这批商品的访问查询都落到了数据库中,那么对于数据库而言,机会产生周期性的压力波峰。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
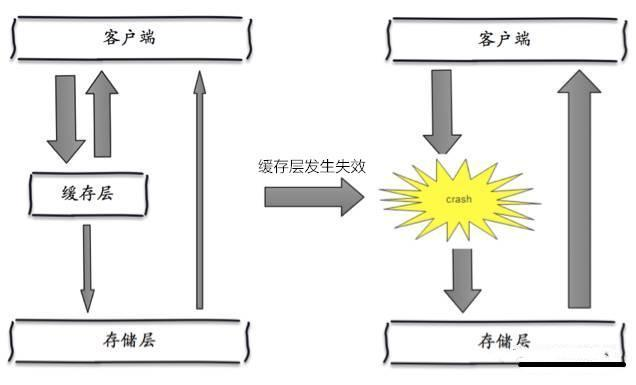
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,这个时候,数据库也是可以顶住压力的。无非就是对数据库产生周期性的压力而已。而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮。
解决方案:
(1)redis高可用
这个思想的含义是,既然redis有可能挂掉,那就多设几台redis,这样一台挂掉后其他的还可以继续工作,其实就是搭建的集群。(异地多活)
(2)限流降级
这个解决方案的思想是,在缓存过期失效后,通过加锁或者队列来控制数据库写缓存的线程数量,比如某个key只允许一个线程查询数据和写缓存,其它线程等待;
(3)数据预热
数据预热的含义就是在正式部署之前,把可能高频的数据预先先访问一遍,这样部分可能大量访问的数据就会加载到缓存中,在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
参考至:https://space.bilibili.com/95256449