MYSQL索引分类
在一个表中,主键索引只能有一个,唯一索引可以有多个
-
主键索引:即一个索引只包含单个列,一个表可以有多个单值索引。
--该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL
ALTER TABLE tb1_name ADD RPIMARY KEY(column_list);
-
唯一索引:索引列的值必须唯一,但允许有空值。
--这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)
ALTER TABLE tb1_name ADD UNIQUE index_name(column_list);
-
普通索引:默认,可以使用index,key关键字设置
--添加普通索引,索引值可出现多次
ALTER TABLE tal_name ADD INDEX index_name(column_list);
-
全文索引:在特定的数据引擎下才有(MyISAM),快速定位数据
--该语句指定了索引为FULLTEXT,用于全文索引
ALTER TABLE tb1_name ADD FULLTEXT index_name(column_list);
MYSQL索引结构
-
BTree索引
-
检索原理:B+Tree结构,如下图所示:
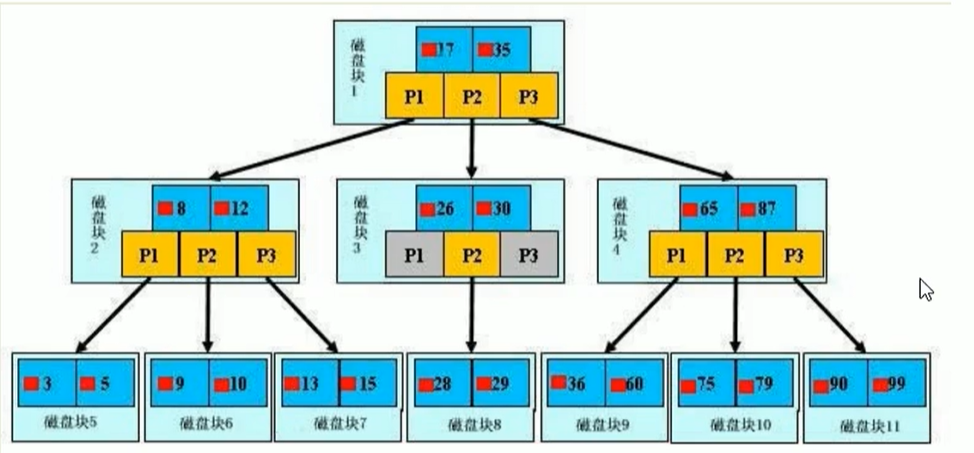
-
Hash索引
-
full-text全文索引
-
R-Tree索引
索引优劣
优势
-
提高数据检索的效率,降低数据库的IO成本
-
通过索引对数据进行排序,降低数据排序的成本,降低了CPU的消耗
劣势
-
实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用空间的
-
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新带来的键值变化后的索引信息。
-
索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询
索引原则
创建索引的情况
-
主键自动建立唯一索引
-
频繁作为查询条件的字段应该创建索引
-
查询中与其它表关联的字段,外键关系建立索引
-
频繁更新的字段不适合创建索引(因为每次更新不单单是更新了记录还会更新索引)
-
Where条件里用不到的字段不创建索引
-
单键、组合索引的选择问题(在高并发下倾向于创建组合索引)
-
查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
-
查询中统计或者分组字段(group by最好是有索引的)
不适合创建索引的情况
-
表记录太少不需要建立
-
经常增删改的表(每次的操作都会重新构建索引,大大降低了操作效率)
-
数据重复且分布平均的表字段,因此应该只为最经常查询和最经常排序的数据列建立索引。(如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果)
索引失效
-
最好使用全值匹配,也就是查询的字段为索引字段
-
最佳左前缀法则:如果索引了多列,要遵守最左前缀法则,指的是查询从索引的最左前列开始并且不跳过索引中的列
-
不在索引列中做任何操作(计算、函数、(自动or手动)),会导致索引失效而转向全表扫描
-
存储引擎不能使用索引中范围条件右边的列
-
尽量使用引擎索引(只访问索引的查询(索引列和查询列一直)),减少select *
-
mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
-
is null,is not null 也无法使用索引
-
like以通配符开头(‘%abc...’)mysql索引失效会变成全表扫描的操作(可以使用组合索引取巧处理)
-
字符串不加单引号索引失效
-
参考博文:http://blog.codinglabs.org/articles/theory-of-mysql-index.html
性能分析
案例:
select * from personnal

-
id:select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
-
id相同,执行顺序由上至下
-
id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
-
id有相同的有不同的,值越大,优先级越高,衍生表(虚表)是DERIVED+id值
-
-
select_type:主要用于区别聚合查询、子查询等的复杂查询
-
SIMPLE:简单的select查询,查询中不包含子查询或者UNION
-
PRIMARY:查询中若包含任何复杂的子部分,最外层查询则被标记为该状态
-
SUBQUERY:在select或where列表中包含子查询
-
DERIVED:在FROM列表中包含的子查询被标记为DERIVED(衍生),Mysql会递归执行这些子查询,把结果放在临时表里。
-
UNION:若第二个select出现在union之后,则被标记为union。若union包含在from子句的子查询中,外层select将被标记为:DERIVED
-
UNION RESULT:从UNION表获取结果的SELECT
-
table:数据是关于哪一张表的
-
type:显示查询使用了何种类型(system>const>eq_ref>ref>range>index>ALL),一般来说,查询至少需要达到range级别,最好能达到ref
-
possible_keys:显示可能应用在这张表中的索引,一个或多个。查询涉及到的字段上若存在索引,则该索引将被列出。但不一定被查询实际使用
-
key:实际使用的索引,如果为NULL,则没有使用索引,查询中若使用了覆盖索引,则该索引仅出现在key列表中
-
key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好,key_len显示的值为索引字段的最长可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。
-
ref:显示索引的哪一列被使用了,如果可能的话,是一个常量。哪些列或常量被用于查找索引列上的值
-
rows:根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数
-
Extra:包含不适合在其它列中显示但十分重要的额外信息
-
Using filesort:说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取,MYSQL中无法利用索引完成的排序操作称为“文件排序”
-
Using temporary:使用了临时表保存中间结果,MySQL在对查询结果排序是使用临时表。常见于排序order by和分组查询group by
-
Using index:①表示相应的select操作中使用了覆盖索引(Convering Index),避免访问了表的数据行,效率不错;②如果同时出现using where,表明索引被用来执行索引键值的查找;③如果没有同时出现using where,表明索引用来读取数据而非执行查找动作;④覆盖索引:解释一:就是select的数据列只用从索引中就能够获取,不必读取数据行,MySQL可以利用索引返回select列表中的字段,而不必根据索引再次读取数据文件,换句话说查询列要被所建索引覆盖。解释二:索引是高效找到行的方法之一,但是一般数据库也能使用索引找到一个列的数据,因此它不必读取整个行。毕竟索引叶子节点存储了它们索引的数据,当能通过读取索引就可以得到想要的数据,那就不需要读取行了。一个索引包含了(或覆盖了)过滤查询的数据就叫做覆盖索引。
①如果要使用覆盖索引,一定要注意select列表中只取出需要的列,不可select *;②因为如果将所有字段一起做索引会导致索引文件过大,查询性能下降。
-
Using where:表明使用了where过滤
-
Using join buffer:使用了连接缓存
-
impossible where:where子句的值总是false,不能用来获取任何元素
-
select tables optimized away:在没有GROUPBY子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。
-
distinct:优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作
-