1 Linux Namespace
Linux Namespaces机制提供一种资源隔离方案。PID,IPC,Network等系统资源不再是全局性的,而是属于特定的Namespace。每个Namespace里面的资源对其他Namespace都是透明的。要创建新的Namespace,只需要在调用clone时指定相应的flag。Linux Namespaces机制为实现基于容器的虚拟化技术提供了很好的基础,LXC(Linux containers)就是利用这一特性实现了资源的隔离。不同Container内的进程属于不同的Namespace,彼此透明,互不干扰。Linux Namespace 有如下种类:

传统上,在Linux以及其他衍生的UNIX变体中,许多资源是全局管理的。例如,系统中的所有进程按照惯例是通过PID标识的,这意味着内核必须管理一个全局的PID列表。命名空间提供了一种不同的解决方案,所需资源较少。在虚拟化的系统中,一台物理计算机可以运行多个内核,可能是并行的多个不同的操作系统。而命名空间则只使用一个内核在一台物理计算机上运作,这使得可以将一组进程放置到容器中,各个容器彼此隔离。隔离可以使容器的成员与其他容器毫无关系。但也可以通过允许容器进行一定的共享,来降低容器之间的分隔。例如,容器可以设置为使用自身的PID集合,但仍然与其他容器共享部分文件系统。这样改变全局属性不会传播到父进程命名空间,而父进程的修改也不会传播到子进程。
隔离主要通过三个系统调用实现:1、clone()–实现线程的系统调用,用来创建一个新的进程,并可以通过设计参数达到隔离。2、unshare()–使某进程脱离某个namespace。3、setns()–把某进程加入到某个namespace。
PID("chroot"进程树) Namespace:
当调用clone时,设定了CLONE_NEWPID,就会创建一个新的PID Namespace,clone出来的新进程将成为Namespace里的第一个进程。一个PID Namespace为进程提供了一个独立的PID环境,PID Namespace内的PID将从1开始,在Namespace内调用fork,vfork或clone都将产生一个在该Namespace内独立的PID。新创建的Namespace里的第一个进程在该Namespace内的PID将为1,就像一个独立的系统里的init进程一样。该Namespace内的孤儿进程都将以该进程为父进程,当该进程被结束时,该Namespace内所有的进程都会被结束。PID Namespace是层次性,新创建的Namespace将会是创建该Namespace的进程属于的Namespace的子Namespace。子Namespace中的进程对于父Namespace是可见的,一个进程将拥有不止一个PID,而是在所在的Namespace以及所有直系祖先Namespace中都将有一个PID。系统启动时,内核将创建一个默认的PID Namespace,该Namespace是所有以后创建的Namespace的祖先,因此系统所有的进程在该Namespace都是可见的。
IPC(进程间通信) Namespace:
当调用clone时,设定了CLONE_NEWIPC,就会创建一个新的IPC Namespace,clone出来的进程将成为Namespace里的第一个进程。一个IPC Namespace有一组System V IPC objects 标识符构成,这标识符有IPC相关的系统调用创建。在一个IPC Namespace里面创建的IPC object对该Namespace内的所有进程可见,但是对其他Namespace不可见,这样就使得不同Namespace之间的进程不能直接通信,就像是在不同的系统里一样。当一个IPC Namespace被销毁,该Namespace内的所有IPC object会被内核自动销毁。PID Namespace和IPC Namespace可以组合起来一起使用,只需在调用clone时,同时指定CLONE_NEWPID和CLONE_NEWIPC,这样新创建的Namespace既是一个独立的PID空间又是一个独立的IPC空间。不同Namespace的进程彼此不可见,也不能互相通信,这样就实现了进程间的隔离。
Mount(挂载点) Namespace:
当调用clone时,设定了CLONE_NEWNS,就会创建一个新的mount Namespace。每个进程都存在于一个mount Namespace里面,mount Namespace为进程提供了一个文件层次视图。如果不设定这个flag,子进程和父进程将共享一个mount Namespace,其后子进程调用mount或umount将会影响到所有该Namespace内的进程。如果子进程在一个独立的mount Namespace里面,就可以调用mount或umount建立一份新的文件层次视图。该flag配合pivot_root系统调用,可以为进程创建一个独立的目录空间。
Network(网络访问,包括接口) Namespace:
当调用clone时,设定了CLONE_NEWNET,就会创建一个新的Network Namespace。一个Network Namespace为进程提供了一个完全独立的网络协议栈的视图。包括网络设备接口,IPv4和IPv6协议栈,IP路由表,防火墙规则,sockets等等。一个Network Namespace提供了一份独立的网络环境,就跟一个独立的系统一样。一个物理设备只能存在于一个Network Namespace中,可以从一个Namespace移动另一个Namespace中。虚拟网络设备(virtual network device)提供了一种类似管道的抽象,可以在不同的Namespace之间建立隧道。利用虚拟化网络设备,可以建立到其他Namespace中的物理设备的桥接。当一个Network Namespace被销毁时,物理设备会被自动移回init Network Namespace,即系统最开始的Namespace。
UTS(主机名) Namespace:
当调用clone时,设定了CLONE_NEWUTS,就会创建一个新的UTS Namespace。一个UTS Namespace就是一组被uname返回的标识符。新的UTS Namespace中的标识符通过复制调用进程所属的Namespace的标识符来初始化。Clone出来的进程可以通过相关系统调用改变这些标识符,比如调用sethostname来改变该Namespace的hostname。这一改变对该Namespace内的所有进程可见。CLONE_NEWUTS和CLONE_NEWNET一起使用,可以虚拟出一个有独立主机名和网络空间的环境,就跟网络上一台独立的主机一样。
以上所有clone flag都可以一起使用,为进程提供了一个独立的运行环境。LXC正是通过clone时设定这些flag,为进程创建一个有独立PID,IPC,FS,Network,UTS空间的container。一个container就是一个虚拟的运行环境,对container里的进程是透明的,它会以为自己是直接在一个系统上运行的。
2 Linux CGroup
Namespace解决的问题主要是环境隔离的问题,这只是虚拟化中最最基础的一步,我们还需要解决对计算机资源使用上的隔离。我们希望对进程进行资源利用上的限制或控制,这就是Linux CGroup出来了的原因。
Linux CGroup全称Linux Control Group,是Linux内核的一个功能,用来限制,控制与分离一个进程组群的资源(如CPU、内存、磁盘输入输出等)。Linux CGroup可让您为系统中所运行任务(进程)的用户定义组群分配资源—比如CPU时间、系统内存、网络带宽或者这些资源的组合。您可以监控您配置的cgroup,拒绝cgroup访问某些资源,甚至在运行的系统中动态配置你的cgroup。
Cgroup主要提供了如下功能:Resource limitation: 限制资源使用,比如内存使用上限以及文件系统的缓存限制;Prioritization: 优先级控制,比如:CPU利用和磁盘IO吞吐;Accounting: 一些审计或一些统计,主要目的是为了计费;Control: 挂起进程,恢复执行进程。
还需要了解这些CGroup 相关概念:任务(task):在 cgroups 中,任务就是系统的一个进程;控制族群(control group):控制族群就是一组按照某种标准划分的进程,Cgroups 中的资源控制都是以控制族群为单位实现,一个进程可以加入到某个控制族群,也从一个进程组迁移到另一个控制族群,一个进程组的进程可以使用 cgroups 以控制族群为单位分配的资源,同时受到 cgroups 以控制族群为单位设定的限制;层级(hierarchy):控制族群可以组织成 hierarchical 的形式,既一颗控制族群树。控制族群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性;子系统(subsystem):一个子系统就是一个资源控制器,比如 cpu 子系统就是控制 cpu 时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。
每次在系统中创建新层级时,该系统中的所有任务都是那个层级的默认 cgroup(我们称之为 root cgroup,此 cgroup 在创建层级时自动创建,后面在该层级中创建的 cgroup 都是此 cgroup 的后代)的初始成员; 一个子系统最多只能附加到一个层级; 一个层级可以附加多个子系统; 一个任务可以是多个 cgroup 的成员,但是这些 cgroup 必须在不同的层级; 系统中的进程(任务)创建子进程(任务)时,该子任务自动成为其父进程所在 cgroup 的成员。然后可根据需要将该子任务移动到不同的 cgroup 中,但开始时它总是继承其父任务的 cgroup。
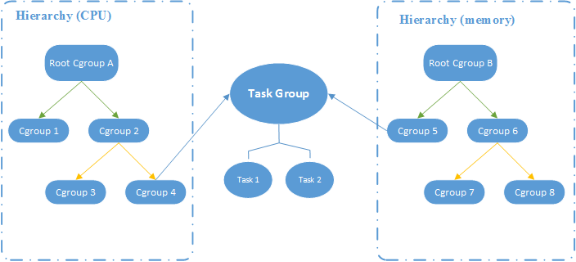
上图所示的 CGroup 层级关系显示,CPU 和 Memory 两个子系统有自己独立的层级系统,而又通过 Task Group 取得关联关系。
3 AUFS
AUFS是一种Union File System,所谓UnionFS就是把不同物理位置的目录合并mount到同一个目录中。AUFS又叫Another UnionFS,后来叫Alternative UnionFS,后来叫成Advance UnionFS。是个叫Junjiro Okajima在2006年开发的,该功能的代码现在仍然没有进到Linux主干里,因为Linus不让,基本上是因为代码量比较多,而且写得烂。不过,很多发行版都用了AUFS,比如:Ubuntu 10.04,Debian6.0,Gentoo Live CD。
AUFS是个很有用的东西,它把多个目录,合并成同一个目录,并可以为每个需要合并的目录指定相应的权限,实时的添加、删除、修改已经被mount好的目录。而且,他还能在多个可写的branch/dir间进行负载均衡。更进一步地,AUFS支持为每一个成员目录(AKA branch)设定'readonly', 'readwrite' 和 'whiteout-able' 权限,同时AUFS里有一个类似分层的概念,对 readonly 权限的branch可以逻辑上进行修改(增量地,不影响readonly部分的)。Docker把UnionFS的想像力发挥到了容器的镜像,利用AUFS技术做出了分层的镜像,如下图:
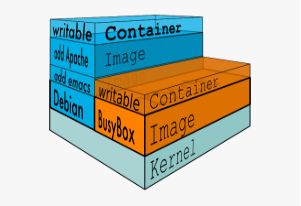
典型的Linux启动到运行需要两个FS -bootfs + rootfs (从功能角度而非文件系统角度),bootfs (boot file system) 主要包含 bootloader 和 kernel, bootloader主要是引导加载kernel, 当boot成功后 kernel 被加载到内存中后 bootfs就被umount了,rootfs (root file system) 包含的就是典型 Linux 系统中的 /dev,/proc,/bin,/etc 等标准目录和文件。由此可见对于不同的linux发行版, bootfs基本是一致的, rootfs会有差别, 因此不同的发行版可以公用bootfs,如下图:
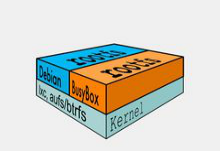
典型的Linux在启动后,首先将 rootfs 置为 readonly, 进行一系列检查, 然后将其切换为 “readwrite” 供用户使用。在docker中,起初也是将 rootfs 以readonly方式加载并检查,然而接下来利用 union mount 的将一个 readwrite 文件系统挂载在 readonly 的rootfs之上,并且允许再次将下层的 file system设定为readonly 并且向上叠加, 这样一组readonly和一个writeable的结构构成一个container的运行目录, 每一个被称作一个Layer。如下图:

得益于AUFS的特性, 每一个对readonly层文件/目录的修改都只会存在于上层的writeable层中。这样由于不存在竞争, 多个container可以共享readonly的layer。所以docker将readonly的层称作 “image”。对于container而言整个rootfs都是read-write的,但事实上所有的修改都写入最上层的writeable层中。上层的image依赖下层的image,因此docker中把下层的image称作父image,没有父image的image称作base image,因此想要从一个image启动一个container,docker会先加载其父image直到base image,用户的进程运行在writeable的layer中。所有parent image中的数据信息以及ID、网络和lxc管理的资源限制等具体container的配置,构成一个docker概念上的container。
关于docker的分层镜像,除了aufs,docker还支持btrfs, devicemapper和vfs。在Ubuntu 14.04下,docker默认Ubuntu的 aufs(在CentOS7下,用的是devicemapper)。