一、概念
KNN主要用来解决分类问题,是监督分类算法,它通过判断最近K个点的类别来决定自身类别,所以K值对结果影响很大,虽然它实现比较简单,但在目标数据集比例分配不平衡时,会造成结果的不准确。而且KNN对资源开销较大。
二、计算
通过K近邻进行计算,需要:
1、加载打标好的数据集,然后设定一个K值;
2、计算预测对象与打标对象的欧式距离,
欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式:
二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离:
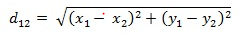
三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离:

两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离:
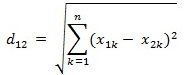
然后将计算的结果进行排序选取前K个组成决策集合,然后在其中选取最多的作为预测对象类别
三、实现
import math import operator def get_distance(vect_test, vect_train): distance = 0 for i in range(len(vect_test)): distance = pow((vect_test[i] - vect_train[i]), 2) return math.sqrt(distance) def get_neighbor(vect_test, train_vect_set, k): distance = [] for vect_train in train_vect_set: dist = get_distance(vect_test, vect_train) distance.append((dist, vect_train)) distance.sort(key=operator.itemgetter(0)) neighbors = [] for i in range(k): neighbors.append(distance[i][1]) return neighbors def get_result(neighbors): votes = {} for neighbor in neighbors: vote = neighbor[-1] if vote in votes: votes[vote] += 1 else: votes[vote] = 1 vote_order = sorted(votes.items(), key=operator.itemgetter(1), reverse=True) return vote_order[0][0] def k_nearest_neighbor(vect_test, vect_train, k): neighbors = get_neighbor(vect_test, vect_train, k) result = get_result(neighbors) print(result) if __name__ == '__main__': vect_train = [[1, 1, 1, 'a'], [2, 2, 2, 'b'], [1, 1, 3, 'a'], [4, 4, 4, 'b'], [0, 0, 0, 'a'], [4, 5, 4, 'b']] vect_test = [5, 5, 5] k_nearest_neighbor(vect_test, vect_train, 3)