- kafka简介
- kafka是分布式的消息发布和订阅系统(生产->消费)
- 特点:
- 消息持久化:通过o(1)的磁盘数据结构提供数据的持久化(拒绝写入内存操作,直接存入磁盘,小伙伴们都知道写入磁盘会速度会很慢,一定程度上受到了限制,那么kafka是如何操作的呢?kafka通过操作系统的预读、后写的机制进行操作,致使在一定程度上对磁盘的顺序访问速度比对内存随机访问速度更快,预读后写:即读取多行一次写入文件)
- 高吞吐量:每秒百万级的消息读写
- 分布式:扩展能力强
- 多客户端支持:java、php、python、c++...
- 实时性:生产者生产的message(数据单位)立即被消费者可见
- 容错性强:kafka集群里面任何一个设备挂掉之后,仍然可以工作,就算只有一个设备,依然能够保证数据传输精准无误
- kafka家庭成员
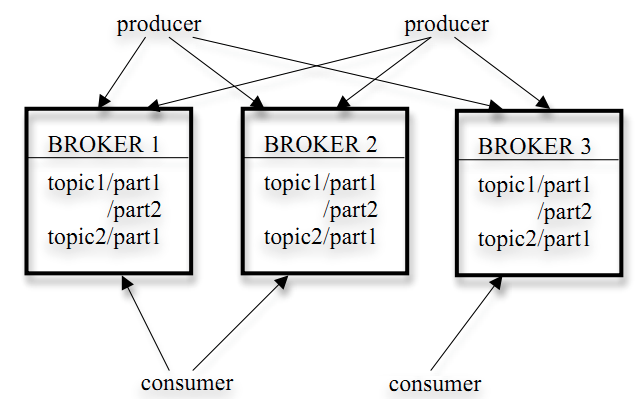
-
- Broker:将已发布的消息保存在一组服务器中,被称之为代理,一般情况下,可以理解为一个节点就是一个Broker,但是这个说法是有问题的,一个节点上可以运行多个Broker,由于这样操作当节点挂掉之后所有Broker都结束掉,所有在工作中使用的很少,一半情况下都是单节点单Broker部署
- producer:消息生产者,可以选择性的发送到任何话题(topic)中,用于写数据
- consumer:消息消费者,可以选择性的从Broker中拉去数据,用户读数据
- Topic:它指的是特定类型的消息流。消息是字节的有效负载(Payload),话题是消息的分类名或种子,不同消费者去指定的Topic中去读数据,不同生产者往不同的Topic里面去写数据(可以简单理解成逻辑概念上的一个消息的容器)
- Partition:在Topic上进行进一步区分分层(一个Topic是由多个Partition组成)
- 如果一个Topic内部多个Partition,那么是如何保证顺序性呢?,全局有序无法保证,仅仅能保证Partition内部有序,那么内部有序又是如何保证的呢?在Partition类似于一个先进先出队列,每一个message都有会记录一个offset的id来用来唯一标识分区中的消息,消息在消费者消费了一段时间之后 ,才会从队列中删除(时间可以配置,默认7天)
- Partition以文件夹的形式存在,保证数据落地
- 多个Broker的时候,Partition会存储在哪儿呢?一致性哈希算法
- kafka的工作原理
- Producer 如果生产了数据,会先通过Zookeeper找到相对应的Broker,然后将数据存放在Broker中
- Consumer 如果要消费数据,会先通过Zookeeper找到对应的Broker,然后进行消费
- kafka API
- Producer API:允许一个应用向一个或多个topic里发布记录流
- Consumer API:允许应用订阅一个或多个topics,处理topic里面的数据流
- Stream API :允许应用扮演流处理的作用,从一个或多个topic里面消费数据流,然后产生输出流数据到到其他一个或多个topic里,保证输入流数据有效、精准的传输到输出口
- Connector API :允许运行和构建一个可以重复利用的生产者和消费者,能将Kafka的topic与其他存在的应用和数据库设备连接,比如连接一个实时的数据库,可以捕捉到每张表的变化
- kafka应用场景
- 日志收集:同一接口服务的方式开放使用提供收集各种服务的Log
- 消息系统:解耦生产者和消费者、缓存消息等
- 用户跟踪:记录浏览网页、搜索、点击等行为
- 流式处理:kafka接入Spark Streaming 和Storm等