版本选择:2.7.5或者2.7.5以上版本均可
软件安装准备工作
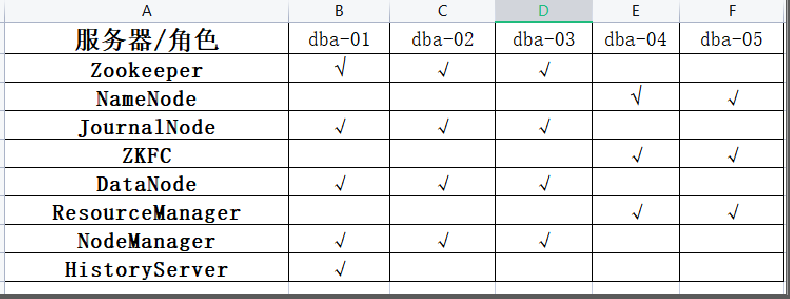
机器规划
1.所有服务器关闭防火墙和selinux
#systemctl stop firewalld ---临时停掉firewalld
#systemctl disable firewalld ---永久开机关闭firewalld
#setenforce 0 ----临时停掉selinux
#vim /etc/selinux/config ---永久开机关闭selinux
SELINUX=disabled
#getenfore ---查看selinux状态
2.linux创建hadoop用户组
#useradd hadoop
创建用户密码
#password hadoop
3.创建文件路径(每台服务器都要创建)
创建hadoop临时文件存放路径
#mkdir -p /home/hadoop/app/hadoop/data/tmp
#mkdir -p /home/hadoop/app/hadoop/data/journal
#mkdir -p /home/hadoop/app/hadoop/tmp
4.ssh免密配置(hadoop用户)
每台机器执行
#ssh-keygen
#cat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keys
几台机器之间互传
#cat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keys
#scp /home/hadoop/.ssh/authorized_keys root@ip:/home/hadoop/.ssh/authorized_keys
#chmod 600 authorized_keys ----hadoop用户
修改/etc/hosts
#vim /etc/hosts
dba-01 xxxxxx
dba-02 xxxxxx
dba-03 xxxxxx
dba-04 xxxxxx
dba-05 xxxxxx
5.jdk1.8安装(所有服务器均使用root用户安装)
#tar -zxvf jdk-8u202-linux-x64.tar.gz -C /opt
#vim /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_202/
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
#source /etc/profile
#which java
hadoop集群安装
1.下载安装包并解压
#wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz
#tar -zxvf hadoop-2.7.5.tar.gz -C /home/hadoop/app
#ln -s /home/hadoop/app/hadoop-2.7.5 /home/hadoop/app/hadoop
2.配置环境变量(每台服务器都要添加)
#vim /etc/profile
export HADOOP_HOME=/home/hadoop/app/hadoop
#path路径添加
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#source /etc/profile
3.配置/home/hadoop/app/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_202/
4.配置/home/hadoop/app/hadoop/etc/hadoop/core-site.xml
添加内容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-2.7.5/data/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>ipc.server.read.threadpool.size</name>
<value>3</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>dba-01:2181,dba-02:2181,bigdata03:2181</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
5.修改hdfs-site.xml
#vim /home/hadoop/app/hadoop-2.7.5/etc/hadoop/hdfs-site.xml
添加内容:
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>dba-04:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>dba-04:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>dba-05:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>dba-05:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://dba-01:8485;dba-02:8485;dba-03:8485/ns1</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/app/hadoop-2.7.5/data/journal</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
6.修改yarn-site.xml
# vim /home/hadoop/app/hadoop-2.7.5/etc/hadoop/yarn-site.sh
添加内容:
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster_id</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>dba-04</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>dba-05</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>dba-04:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>dba-05:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>dba-01:2181,dba-02:2181,dba-03:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>3600</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://dba-01:19888/jobhistory/logs/</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/home/hadoop/app/hadoop-2.7.5/etc/hadoop/fair-scheduler.xml</value>
</property>
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.fair.sizebasedweight</name>
<value>false</value>
</property>
<property>
<name>yarn.scheduler.fair.assignmultiple</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.max.assign</name>
<value>3</value>
</property>
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-state-store.parent-path</name>
<value>/rmstore</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
7.创建yarn公平调度模式配置文件fair-scheduler.xml
<?xml version="1.0"?>
<allocations>
<queue name="root">
<aclSubmitApps> </aclSubmitApps>
<queue name="default">
<minResources>1mb,1vcores</minResources>
<maxResources>1mb,1vcores</maxResources>
</queue>
<!-- min 1/3 max 1/2 -->
<queue name="offline">
<minResources>1048576mb,330vcores</minResources>
<maxResources>1572864mb,500vcores</maxResources>
<queue name="algo">
<weight>2.0</weight>
<minResources>524288mb,166vcores</minResources>
<maxResources>786432mb,250vcores</maxResources>
<aclSubmitApps>algo</aclSubmitApps>
<aclAdministerApps>algo</aclAdministerApps>
<schedulingPolicy>fair</schedulingPolicy>
</queue>
<queue name="dp">
<weight>2.0</weight>
<minResources>786432mb,250vcores</minResources>
<maxResources>1572864mb,500vcores</maxResources>
<!--<maxResources>1048576mb,332vcores</maxResources>-->
<aclSubmitApps>work</aclSubmitApps>
<aclAdministerApps>work</aclAdministerApps>
<schedulingPolicy>fair</schedulingPolicy>
</queue>
</queue>
<queueMaxAMShareDefault>0.5</queueMaxAMShareDefault>
<!-- Queue 'secondary_group_queue' is a parent queue and may have
user queues under it type="parent" -->
<!-- min 1/4 max 1/3 -->
<queue name="online">
<minResources>393216mb,124vcores</minResources>
<maxResources>1048576mb,330vcores</maxResources>
<queue name="algo">
<weight>2.0</weight>
<minResources>524288mb,165vcores</minResources>
<maxResources>699050mb,220vcores</maxResources>
<aclSubmitApps>algo</aclSubmitApps>
<aclAdministerApps>algo</aclAdministerApps>
<schedulingPolicy>fair</schedulingPolicy>
</queue>
<queue name="dp">
<weight>2.0</weight>
<minResources>349525mb,110vcores</minResources>
<maxResources>524288mb,165vcores</maxResources>
<aclSubmitApps>work</aclSubmitApps>
<aclAdministerApps>work</aclAdministerApps>
<schedulingPolicy>fair</schedulingPolicy>
</queue>
</queue>
<!-- min 1/3 max 2/3 -->
<queue name="spark">
<minResources>786432mb,248vcores</minResources>
<maxResources>2184532mb,682vcores</maxResources>
<!--<maxResources>1048576mb,330vcores</maxResources>-->
<queue name="algo">
<weight>2.0</weight>
<minResources>524288mb,165vcores</minResources>
<maxResources>2184532mb,682vcores</maxResources>
<!--<maxResources>699050mb,220vcores</maxResources>-->
<aclSubmitApps>algo</aclSubmitApps>
<aclAdministerApps>algo</aclAdministerApps>
<schedulingPolicy>fair</schedulingPolicy>
</queue>
<queue name="dp">
<weight>2.0</weight>
<minResources>349525mb,110vcores</minResources>
<maxResources>524288mb,165vcores</maxResources>
<aclSubmitApps>work</aclSubmitApps>
<aclAdministerApps>work</aclAdministerApps>
<schedulingPolicy>fair</schedulingPolicy>
</queue>
</queue>
<!--
<user name="sample_user">
<maxRunningApps>30</maxRunningApps>
</user>
-->
<userMaxAppsDefault>5</userMaxAppsDefault>
<!--
<queuePlacementPolicy>
<rule name="specified" />
<rule name="primaryGroup" create="false" />
<rule name="nestedUserQueue">
<rule name="secondaryGroupExistingQueue" create="false" />
</rule>
<rule name="default" queue="sample_queue"/>
</queuePlacementPolicy>
-->
</queue>
</allocations>
8.修改mapred-env.sh
#vim /home/hadoop/app/hadoop-2.7.5/etc/hadoop/mapred-env.sh
9.修改pid目录配置
export HADOOP_MAPRED_PID_DIR=/home/hadoop/app/hadoop-2.7.5/data/tmp
10.修改mapred-site.xml
#vim /home/hadoop/app/hadoop-2.7.5/etc/hadoop/mapred-site.xml
增加配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>dba-01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>dba-01:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.joblist.cache.size</name>
<value>10000</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.cpu-vcores</name>
<value>2</value>
</property>
<property>
<name>mapreduce.am.max-attempts</name>
<value>2</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx1638m -Xms1638m -Xmn256m -XX:MaxDirectMebaiwanrySize=128m -XX:SurvivorRatio=6 -XX:MaxPermSize=128m</value>
</property>
<property>
<name>mapreduce.map.mebaiwanry.mb</name>
<value>2548</value>
</property>
<property>
<name>mapreduce.reduce.mebaiwanry.mb</name>
<value>4596</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx2048m -Xms2048m -Xmn256m -XX:MaxDirectMebaiwanrySize=128m -XX:SurvivorRatio=6 -XX:MaxPermSize=128m -XX:ParallelGCThreads=10</value>
<final>true</final>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx4096m -Xms4096m -Xmn256m -XX:MaxDirectMebaiwanrySize=128m -XX:SurvivorRatio=6 -XX:MaxPermSize=128m -XX:ParallelGCThreads=10</value>
<final>true</final>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>100</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>512</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>10</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.merge.percent</name>
<value>0.8</value>
</property>
<property>
<name>mapreduce.reduce.input.buffer.percent</name>
<value>0.25</value>
</property>
<property>
<name>mapreduce.job.reduce.slowstart.completedmaps</name>
<value>0.5</value>
</property>
<property>
<name>mapreduce.map.speculative</name>
<value>true</value>
</property>
<property>
<name>mapreduce.shuffle.max.threads</name>
<value>100</value>
</property>
<property>
<name>mapreduce.reduce.input.buffer.percent</name>
<value>0.25</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>40</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.merge.percent</name>
<value>0.8</value>
</property>
11.修改slaves文件(哪些节点运行datanode)
#vim /home/hadoop/app/hadoop-2.7.5/etc/hadoop/slaves
添加datanode节点:
dba-01
dba-02
dba-03
12.hadoop包分发到其他节点上
scp -r /home/hadoop/app/hadoop-2.7.5 dba-02:/home/hadoop/app
scp -r /home/hadoop/app/hadoop-2.7.5 dba-03:/home/hadoop/app
scp -r /home/hadoop/app/hadoop-2.7.5 dba-04:/home/hadoop/app
scp -r /home/hadoop/app/hadoop-2.7.5 dba-05:/home/hadoop/app
13.首先启动所有的journalnode
#cd /home/hadoop/app/hadoop-2.7.5/sbin
#./hadoop-daemon.sh start journalnode
14.namenode中一个节点上初始化
#cd /home/hadoop/app/hadoop-2.7.5/sbin
#hadoop namenode -format
#hdfs zkfc -formatZK
#hadoop-daemon.sh start namenode
#hadoop-daemon.sh start zkfc
#yarn-daemon.sh start resourcemanager
15.namenode另外一个节点上初始化
#hdfs namenode -bootstrapStandby
#hadoop-daemon.sh start namenode
#hadoop-daemon.sh start zkfc
#yarn-daemon.sh start resourcemanager
16.namenode第一个节点上启动集群
#cd /home/hadoop/app/hadoop-2.7.5/sbin
#hadoop-daemon.sh start datanode
#./mr-jobhistory-daemon.sh start historyserver
17.jobserver机器启动jobhistory
./mr-jobhistory-daemon.sh start historyserver
18.hadoop性能压测(自己选型工具进行压测)
常见问题
1.启动journalnode时报错:/home/hadoop/app/hadoop-2.7.5/bin/hdfs: line 304: /opt/jdk1.8.0_202//bin/java: No such file or directory
原因:/home/hadoop/app/hadoop/etc/hadoop/hadoop-env.sh配置文件中java_home配置路径下无java
2.hdfs集群启动之后,检查各个节点进程,发现有datanode节点未启动,启动日志如下:
Starting namenodes on [dba-04 dba-05]
dba-04: starting namenode, logging to /home/hadoop/app/hadoop-2.7.5/logs/hadoop-hadoop-namenode-dba-04.out
dba-05: starting namenode, logging to /home/hadoop/app/hadoop-2.7.5/logs/hadoop-hadoop-namenode-dba-05.out
dba-01: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
dba-01: @ WARNING: POSSIBLE DNS SPOOFING DETECTED! @
dba-01: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
dba-01: The ECDSA host key for dba-01 has changed,
dba-01: and the key for the corresponding IP address 10.3.0.42
dba-01: is unknown. This could either mean that
dba-01: DNS SPOOFING is happening or the IP address for the host
dba-01: and its host key have changed at the same time.
dba-01: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
dba-01: @ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
dba-01: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
dba-01: IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
dba-01: Someone could be eavesdropping on you right now (man-in-the-middle attack)!
dba-01: It is also possible that a host key has just been changed.
dba-01: The fingerprint for the ECDSA key sent by the remote host is
dba-01: SHA256:zCbOslLNiDBjkO5qKNSgbzvgUDYMQurHHe47MJmCueA.
dba-01: Please contact your system administrator.
dba-01: Add correct host key in /home/hadoop/.ssh/known_hosts to get rid of this message.
dba-01: Offending ECDSA key in /home/hadoop/.ssh/known_hosts:2
dba-01: ECDSA host key for dba-01 has changed and you have requested strict checking.
dba-01: Host key verification failed.
dba-04: starting datanode, logging to /home/hadoop/app/hadoop-2.7.5/logs/hadoop-hadoop-datanode-dba-04.out
dba-05: starting datanode, logging to /home/hadoop/app/hadoop-2.7.5/logs/hadoop-hadoop-datanode-dba-05.out
dba-03: starting datanode, logging to /home/hadoop/app/hadoop-2.7.5/logs/hadoop-hadoop-datanode-dba-03.out
dba-02: starting datanode, logging to /home/hadoop/app/hadoop-2.7.5/logs/hadoop-hadoop-datanode-dba-02.out
Starting journal nodes [dba-01 dba-02 dba-03 dba-04 dba-05]
dba-01: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
dba-01: @ WARNING: POSSIBLE DNS SPOOFING DETECTED! @
dba-01: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
dba-01: The ECDSA host key for dba-01 has changed,
dba-01: and the key for the corresponding IP address 10.3.0.42
dba-01: is unknown. This could either mean that
dba-01: DNS SPOOFING is happening or the IP address for the host
dba-01: and its host key have changed at the same time.
dba-01: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
dba-01: @ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
dba-01: @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
dba-01: IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
dba-01: Someone could be eavesdropping on you right now (man-in-the-middle attack)!
dba-01: It is also possible that a host key has just been changed.
dba-01: The fingerprint for the ECDSA key sent by the remote host is
dba-01: SHA256:zCbOslLNiDBjkO5qKNSgbzvgUDYMQurHHe47MJmCueA.
dba-01: Please contact your system administrator.
dba-01: Add correct host key in /home/hadoop/.ssh/known_hosts to get rid of this message.
dba-01: Offending ECDSA key in /home/hadoop/.ssh/known_hosts:2
dba-01: ECDSA host key for dba-01 has changed and you have requested strict checking.
dba-01: Host key verification failed.
dba-05: journalnode running as process 22165. Stop it first.
dba-04: journalnode running as process 23866. Stop it first.
dba-03: journalnode running as process 17302. Stop it first.
dba-02: journalnode running as process 16164. Stop it first.
Starting ZK Failover Controllers on NN hosts [dba-04 dba-05]
dba-04: starting zkfc, logging to /home/hadoop/app/hadoop-2.7.5/logs/hadoop-hadoop-zkfc-dba-04.out
dba-05: starting zkfc, logging to /home/hadoop/app/hadoop-2.7.5/logs/hadoop-hadoop-zkfc-dba-05.out