Centralized cache management in HDFS has many significant advantages.
- Explicit pinning prevents frequently used data from being evicted from memory. This is particularly important when the size of the working set exceeds the size of main memory, which is common for many HDFS workloads. 阻止经常使用的数据被逐出内存。
- Because DataNode caches are managed by the NameNode, applications can query the set of cached block locations when making task placement decisions. Co-locating a task with a cached block replica improves read performance.
- When block has been cached by a DataNode, clients can use a new , more-efficient, zero-copy read API. Since checksum verification of cached data is done once by the DataNode, clients can incur essentially zero overhead when using this new API.可以使用更高效的无复制的api读这些块。
- Centralized caching can improve overall cluster memory utilization. When relying on the OS buffer cache at each DataNode, repeated reads of a block will result in all nreplicas of the block being pulled into buffer cache. With centralized cache management, a user can explicitly pin only m of the n replicas, saving n-m memory.减少重复读时使用的
适用的情况:
经常需要读的文件。比如一个小文件。
结构:
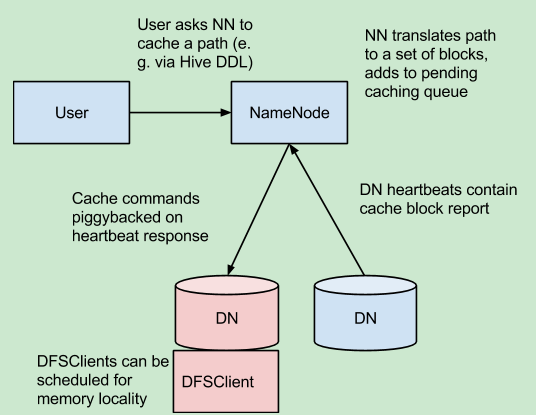
datanode通过heartbeats定期发送缓存块信息到namenode,namdenode把新进的缓存路径发送给datanode让其缓存。
namenode会定时的复查namespace和缓存列表来决定哪些需要缓存和不需要缓存,缓存信息会更新中fsimage中和edit log中。
注意:不会缓存不一致的块,也不会缓存快捷方式的目标对象。
注意:当前只支持文件和目录级别缓存,不支持块级别。目录只支持目录下第一级的数据缓存,不支持循环。
命令和配置:
http://hadoop.apache.org/docs/r2.6.4/hadoop-project-dist/hadoop-hdfs/CentralizedCacheManagement.html
中文件参考: