all details come from zhihu
see https://www.zhihu.com/question/68482809
最近以QA形式写了一篇nlp中的Attention注意力机制+Transformer详解 分享一下自己的观点,目录如下:
一、Attention机制剖析
1、为什么要引入Attention机制?
2、Attention机制有哪些?(怎么分类?)
3、Attention机制的计算流程是怎样的?
4、Attention机制的变种有哪些?
5、一种强大的Attention机制:为什么自注意力模型(self-Attention model)在长距离序列中如此强大?
(1)卷积或循环神经网络难道不能处理长距离序列吗?
(2)要解决这种短距离依赖的“局部编码”问题,从而对输入序列建立长距离依赖关系,有哪些办法呢?
(3)自注意力模型(self-Attention model)具体的计算流程是怎样的呢?
二、Transformer(Attention Is All You Need)详解
1、Transformer的整体架构是怎样的?由哪些部分组成?
2、Transformer Encoder 与 Transformer Decoder 有哪些不同?
3、Encoder-Decoder attention 与self-attention mechanism有哪些不同?
4、multi-head self-attention mechanism具体的计算过程是怎样的?
5、Transformer在GPT和Bert等词向量预训练模型中具体是怎么应用的?有什么变化?
部分观点摘录如下:
1、为什么要引入Attention机制?
根据通用近似定理,前馈网络和循环网络都有很强的能力。但为什么还要引入注意力机制呢?
- 计算能力的限制:当要记住很多“信息“,模型就要变得更复杂,然而目前计算能力依然是限制神经网络发展的瓶颈。
- 优化算法的限制:虽然局部连接、权重共享以及pooling等优化操作可以让神经网络变得简单一些,有效缓解模型复杂度和表达能力之间的矛盾;但是,如循环神经网络中的长距离以来问题,信息“记忆”能力并不高。
可以借助人脑处理信息过载的方式,例如Attention机制可以提高神经网络处理信息的能力。
2、Attention机制有哪些?(怎么分类?)
当用神经网络来处理大量的输入信息时,也可以借鉴人脑的注意力机制,只 选择一些关键的信息输入进行处理,来提高神经网络的效率。按照认知神经学中的注意力,可以总体上分为两类:
- 聚焦式(focus)注意力:自上而下的有意识的注意力,主动注意——是指有预定目的、依赖任务的、主动有意识地聚焦于某一对象的注意力;
- 显著性(saliency-based)注意力:自下而上的有意识的注意力,被动注意——基于显著性的注意力是由外界刺激驱动的注意,不需要主动干预,也和任务无关;可以将max-pooling和门控(gating)机制来近似地看作是自下而上的基于显著性的注意力机制。
在人工神经网络中,注意力机制一般就特指聚焦式注意力。
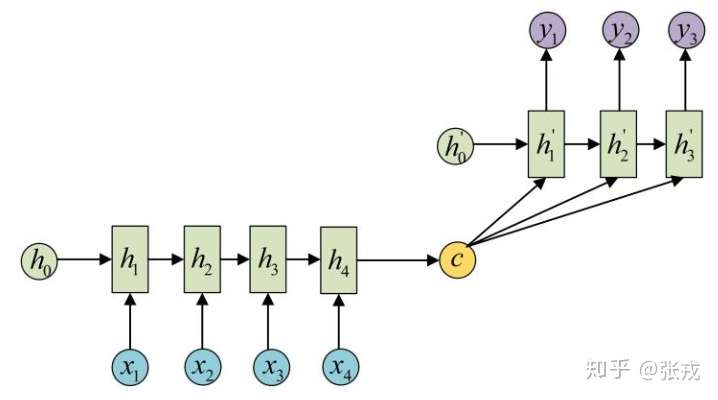
3、Attention机制的计算流程是怎样的?
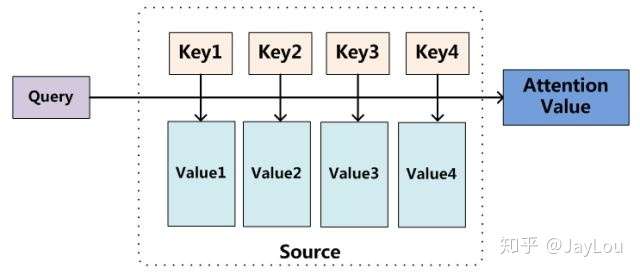 Attention机制的实质:寻址(addressing)
Attention机制的实质:寻址(addressing)
Attention机制的实质其实就是一个寻址(addressing)的过程,如上图所示:给定一个和任务相关的查询Query向量 q,通过计算与Key的注意力分布并附加在Value上,从而计算Attention Value,这个过程实际上是Attention机制缓解神经网络模型复杂度的体现:不需要将所有的N个输入信息都输入到神经网络进行计算,只需要从X中选择一些和任务相关的信息输入给神经网络。
注意力机制可以分为三步:一是信息输入;二是计算注意力分布α;三是根据注意力分布α 来计算输入信息的加权平均。
step1-信息输入:用X = [x1, · · · , xN ]表示N 个输入信息;
step2-注意力分布计算:令Key=Value=X,则可以给出注意力分布
我们将 称之为注意力分布(概率分布),
为注意力打分机制,有几种打分机制:
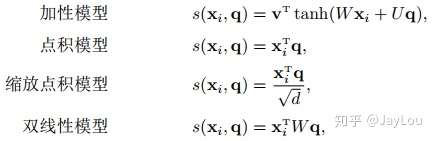
step3-信息加权平均:注意力分布 可以解释为在上下文查询q时,第i个信息受关注的程度,采用一种“软性”的信息选择机制对输入信息X进行编码为:
这种编码方式为软性注意力机制(soft Attention),软性注意力机制有两种:普通模式(Key=Value=X)和键值对模式(Key!=Value)。
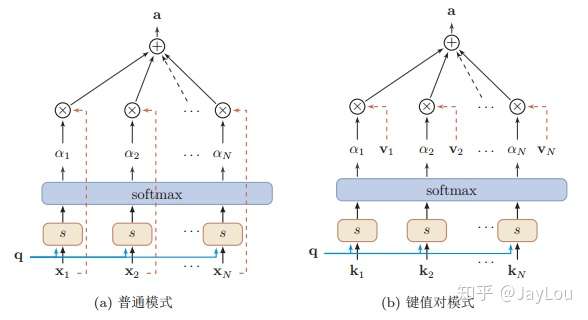 软性注意力机制(soft Attention)
软性注意力机制(soft Attention)
4、Attention机制的变种有哪些?
与普通的Attention机制(上图左)相比,Attention机制有哪些变种呢?
- 变种1-硬性注意力:之前提到的注意力是软性注意力,其选择的信息是所有输入信息在注意力 分布下的期望。还有一种注意力是只关注到某一个位置上的信息,叫做硬性注意力(hard attention)。硬性注意力有两种实现方式:(1)一种是选取最高概率的输入信息;(2)另一种硬性注意力可以通过在注意力分布式上随机采样的方式实现。硬性注意力模型的缺点:
硬性注意力的一个缺点是基于最大采样或随机采样的方式来选择信息。因此最终的损失函数与注意力分布之间的函数关系不可导,因此无法使用在反向传播算法进行训练。为了使用反向传播算法,一般使用软性注意力来代替硬性注意力。硬性注意力需要通过强化学习来进行训练。——《神经网络与深度学习》
- 变种2-键值对注意力:即上图右边的键值对模式,此时Key!=Value,注意力函数变为:
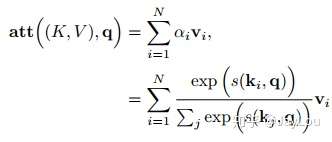
- 变种3-多头注意力:多头注意力(multi-head attention)是利用多个查询Q = [q1, · · · , qM],来平行地计算从输入信息中选取多个信息。每个注意力关注输入信息的不同部分,然后再进行拼接:
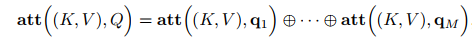
5、一种强大的Attention机制:为什么自注意力模型(self-Attention model)在长距离序列中如此强大?
(1)卷积或循环神经网络难道不能处理长距离序列吗?
当使用神经网络来处理一个变长的向量序列时,我们通常可以使用卷积网络或循环网络进行编码来得到一个相同长度的输出向量序列,如图所示:
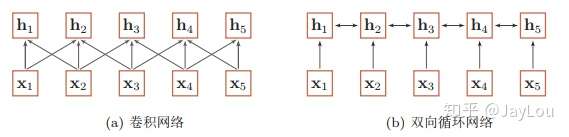 基于卷积网络和循环网络的变长序列编码
基于卷积网络和循环网络的变长序列编码
从上图可以看出,无论卷积还是循环神经网络其实都是对变长序列的一种“局部编码”:卷积神经网络显然是基于N-gram的局部编码;而对于循环神经网络,由于梯度消失等问题也只能建立短距离依赖。
(2)要解决这种短距离依赖的“局部编码”问题,从而对输入序列建立长距离依赖关系,有哪些办法呢?
如果要建立输入序列之间的长距离依赖关系,可以使用以下两种方法:一 种方法是增加网络的层数,通过一个深层网络来获取远距离的信息交互,另一种方法是使用全连接网络。 ——《神经网络与深度学习》
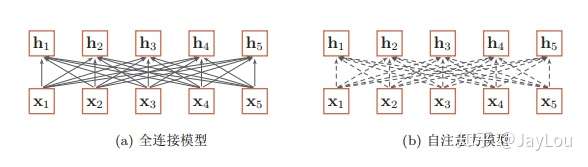 全连接模型和自注意力模型:实线表示为可学习的权重,虚线表示动态生成的权重。
全连接模型和自注意力模型:实线表示为可学习的权重,虚线表示动态生成的权重。
由上图可以看出,全连接网络虽然是一种非常直接的建模远距离依赖的模型, 但是无法处理变长的输入序列。不同的输入长度,其连接权重的大小也是不同的。
这时我们就可以利用注意力机制来“动态”地生成不同连接的权重,这就是自注意力模型(self-attention model)。由于自注意力模型的权重是动态生成的,因此可以处理变长的信息序列。
总体来说,为什么自注意力模型(self-Attention model)如此强大:利用注意力机制来“动态”地生成不同连接的权重,从而处理变长的信息序列。
(3)自注意力模型(self-Attention model)具体的计算流程是怎样的呢?
同样,给出信息输入:用X = [x1, · · · , xN ]表示N 个输入信息;通过线性变换得到为查询向量序列,键向量序列和值向量序列:
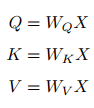
上面的公式可以看出,self-Attention中的Q是对自身(self)输入的变换,而在传统的Attention中,Q来自于外部。
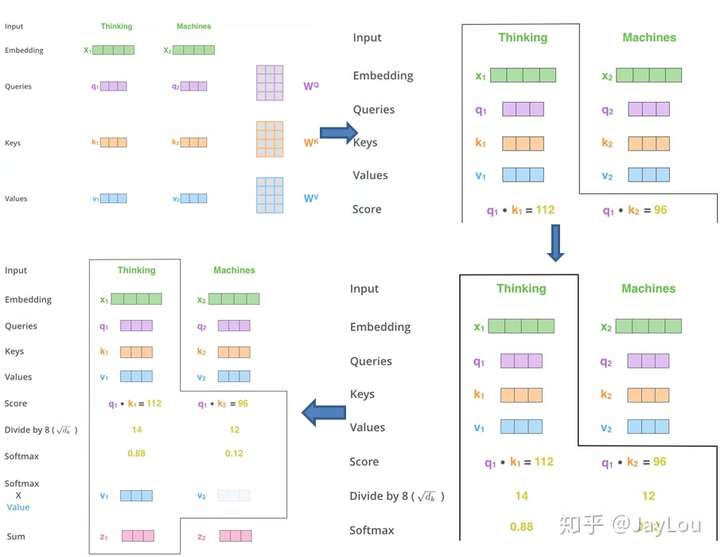 self-Attention计算过程剖解(来自《细讲 | Attention Is All You Need 》)
self-Attention计算过程剖解(来自《细讲 | Attention Is All You Need 》)
注意力计算公式为:
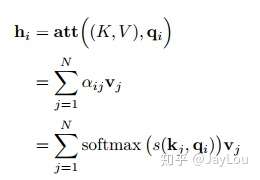
自注意力模型(self-Attention model)中,通常使用缩放点积来作为注意力打分函数,输出向量序列可以写为:
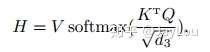
引言
在机器翻译(Machine Translation)或者自然语言处理(Natural Language Processing)领域,以前都是使用数理统计的方法来进行分析和处理。近些年来,随着 AlphaGo 的兴起,除了在游戏AI领域,深度学习在计算机视觉领域,机器翻译和自然语言处理领域也有着巨大的用武之地。在 2016 年,随着深度学习的进一步发展,seq2seq 的训练模式和翻译模式已经开始进入人们的视野。除此之外,在端到端的训练方法中,除了需要海量的业务数据之外,在网络结构中加入一些重要的模块也是非常必要的。在此情形下,基于循环神经网咯(Recurrent Neural Network)的注意力机制(Attention Mechanism)进入了人们的视野。除了之前提到的机器翻译和自然语言处理领域之外,计算机视觉中的注意力机制也是十分有趣的,本文将会简要介绍一下计算机视觉领域中的注意力方法。在此事先声明一下,笔者并不是从事这几个领域的,可能在撰写文章的过程中会有些理解不到位的地方,请各位读者指出其中的不足。
注意力机制
顾名思义,注意力机制是本质上是为了模仿人类观察物品的方式。通常来说,人们在看一张图片的时候,除了从整体把握一幅图片之外,也会更加关注图片的某个局部信息,例如局部桌子的位置,商品的种类等等。在翻译领域,每次人们翻译一段话的时候,通常都是从句子入手,但是在阅读整个句子的时候,肯定就需要关注词语本身的信息,以及词语前后关系的信息和上下文的信息。在自然语言处理方向,如果要进行情感分类的话,在某个句子里面,肯定会涉及到表达情感的词语,包括但不限于“高兴”,“沮丧”,“开心”等关键词。而这些句子里面的其他词语,则是上下文的关系,并不是它们没有用,而是它们所起的作用没有那些表达情感的关键词大。
在以上描述下,注意力机制其实包含两个部分:
- 注意力机制需要决定整段输入的哪个部分需要更加关注;
- 从关键的部分进行特征提取,得到重要的信息。
通常来说,在机器翻译或者自然语言处理领域,人们阅读和理解一句话或者一段话其实是有着一定的先后顺序的,并且按照语言学的语法规则来进行阅读理解。在图片分类领域,人们看一幅图也是按照先整体再局部,或者先局部再整体来看的。再看局部的时候,尤其是手写的手机号,门牌号等信息,都是有先后顺序的。为了模拟人脑的思维方式和理解模式,循环神经网络(RNN)在处理这种具有明显先后顺序的问题上有着独特的优势,因此,Attention 机制通常都会应用在循环神经网络上面。
虽然,按照上面的描述,机器翻译,自然语言处理,计算机视觉领域的注意力机制差不多,但是其实仔细推敲起来,这三者的注意力机制是有明显区别的。
- 在机器翻译领域,翻译人员需要把已有的一句话翻译成另外一种语言的一句话。例如把一句话从英文翻译到中文,把中文翻译到法语。在这种情况下,输入语言和输出语言的词语之间的先后顺序其实是相对固定的,是具有一定的语法规则的;
- 在视频分类或者情感识别领域,视频的先后顺序是由时间戳和相应的片段组成的,输入的就是一段视频里面的关键片段,也就是一系列具有先后顺序的图片的组合。NLP 中的情感识别问题也是一样的,语言本身就具有先后顺序的特点;
- 图像识别,物体检测领域与前面两个有本质的不同。因为物体检测其实是在一幅图里面挖掘出必要的物体结构或者位置信息,在这种情况下,它的输入就是一幅图片,并没有非常明显的先后顺序,而且从人脑的角度来看,由于个体的差异性,很难找到一个通用的观察图片的方法。由于每个人都有着自己观察的先后顺序,因此很难统一成一个整体。
在这种情况下,机器翻译和自然语言处理领域使用基于 RNN 的 Attention 机制就变得相对自然,而计算机视觉领域领域则需要必要的改造才能够使用 Attention 机制。
基于 RNN 的注意力机制
通常来说,RNN 等深度神经网络可以进行端到端的训练和预测,在机器翻译领域和或者文本识别领域有着独特的优势。对于端到端的 RNN 来说,有一个更简洁的名字叫做 sequence to sequence,简写就是 seq2seq。顾名思义,输入层是一句话,输出层是另外一句话,中间层包括编码和解码两个步骤。
而基于 RNN 的注意力机制指的是,对于 seq2seq 的诸多问题,在输入层和输出层之间,也就是词语(Items)与词语之间,存在着某种隐含的联系。例如:“中国” -> “China”,“Excellent” -> “优秀的”。在这种情况下,每次进行机器翻译的时候,模型需要了解当前更加关注某个词语或者某几个词语,只有这样才能够在整句话中进行必要的提炼。在这些初步的思考下,基于 RNN 的 Attention 机制就是:
- 建立一个编码(Encoder)和解码(Decoder)的非线性模型,神经网络的参数足够多,能够存储足够的信息;
- 除了关注句子的整体信息之外,每次翻译下一个词语的时候,需要对不同的词语赋予不同的权重,在这种情况下,再解码的时候,就可以同时考虑到整体的信息和局部的信息。
注意力机制的种类
从初步的调研情况来看,注意力机制有两种方法,一种是基于强化学习(Reinforcement Learning)来做的,另外一种是基于梯度下降(Gradient Decent)来做的。强化学习的机制是通过收益函数(Reward)来激励,让模型更加关注到某个局部的细节。梯度下降法是通过目标函数以及相应的优化函数来做的。无论是 NLP 还是 CV 领域,都可以考虑这些方法来添加注意力机制。
计算机视觉领域的 Attention 部分论文整理
下面将会简单的介绍几篇近期阅读的计算机视觉领域的关于注意力机制的文章。
Look Closer to See Better:Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition
在图像识别领域,通常都会遇到给图片中的鸟类进行分类,包括种类的识别,属性的识别等内容。为了区分不同的鸟,除了从整体来对图片把握之外,更加关注的是一个局部的信息,也就是鸟的样子,包括头部,身体,脚,颜色等内容。至于周边信息,例如花花草草之类的,则显得没有那么重要,它们只能作为一些参照物。因为不同的鸟类会停留在树木上,草地上,关注树木和草地的信息对鸟类的识别并不能够起到至关重要的作用。所以,在图像识别领域引入注意力机制就是一个非常关键的技术,让深度学习模型更加关注某个局部的信息。
在这篇文章里面,作者们提出了一个基于 CNN 的注意力机制,叫做 recurrent attention convolutional neural network(RA-CNN),该模型递归地分析局部信息,从局部的信息中提取必要的特征。同时,在 RA-CNN 中的子网络(sub-network)中存在分类结构,也就是说从不同区域的图片里面,都能够得到一个对鸟类种类划分的概率。除此之外,还引入了 attention 机制,让整个网络结构不仅关注整体信息,还关注局部信息,也就是所谓的 Attention Proposal Sub-Network(APN)。这个 APN 结构是从整个图片(full-image)出发,迭代式地生成子区域,并且对这些子区域进行必要的预测,并将子区域所得到的预测结果进行必要的整合,从而得到整张图片的分类预测概率。
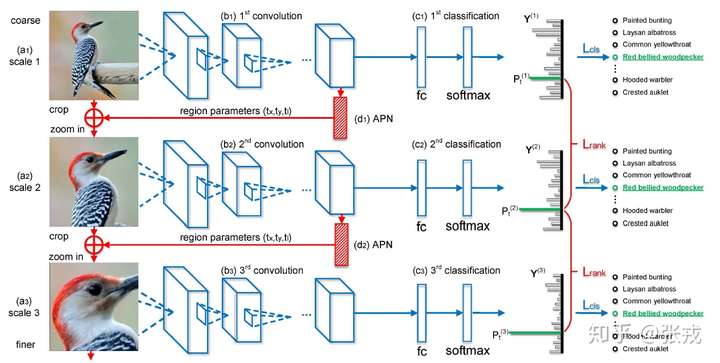
RA-CNN 的特点是进行一个端到端的优化,并不需要提前标注 box,区域等信息就能够进行鸟类的识别和图像种类的划分。在数据集上面,该论文不仅在鸟类数据集(CUB Birds)上面进行了实验,也在狗类识别(Stanford Dogs)和车辆识别(Stanford Cars)上进行了实验,并且都取得了不错的效果。

从深度学习的网络结构来看,RA-CNN 的输入时是整幅图片(Full Image),输出的时候就是分类的概率。而提取图片特征的方法通常来说都是使用卷积神经网络(CNN)的结构,然后把 Attention 机制加入到整个网络结构中。从下图来看,一开始,整幅图片从上方输入,然后判断出一个分类概率;然后中间层输出一个坐标值和尺寸大小,其中坐标值表示的是子图的中心点,尺寸大小表示子图的尺寸。在这种基础上,下一幅子图就是从坐标值和尺寸大小得到的图片,第二个网络就是在这种基础上构建的;再迭代持续放大图片,从而不停地聚焦在图片中的某些关键位置。不同尺寸的图片都能够输出不同的分类概率,再将其分类概率进行必要的融合,最终的到对整幅图片的鸟类识别概率。
因此,在整篇论文中,有几个关键点需要注意:
- 分类概率的计算,也就是最终的 loss 函数的设计;
- 从上一幅图片到下一幅图片的坐标值和尺寸大小。
只要获得了这些指标,就可以把整个 RA-CNN 网络搭建起来。
大体来说,第一步就是给定了一幅输入图片 , 需要提取它的特征,可以记录为
,这里的
指的是卷积等各种各样的操作。所以得到的概率分布情况其实就是
,
指的是从 CNN 的特征层到全连接层的函数,外层使用了 Softmax 激活函数来计算鸟类的概率。
第二步就是计算下一个 box 的坐标 和尺寸大小
,其中
分别指的是横纵坐标,正方形的边长其实是
。用数学公式来记录这个流程就是
。在坐标值的基础上,我们可以得到以下四个值,分别表示
两个坐标轴的上下界:
局部注意力和放大策略(Attention Localization and Amplification)指的是:从上面的方法中拿到坐标值和尺寸,然后把图像进行必要的放大。为了提炼局部的信息,其实就需要在整张图片 的基础上加上一个面具(Mask)。所谓面具,指的是在原始图片的基础上进行点乘 0 或者 1 的操作,把一些数据丢失掉,把一些数据留下。在图片领域,就是把周边的信息丢掉,把鸟的信息留下。但是,有的时候,如果直接进行 0 或者 1 的硬编码,会显得网络结构不够连续或者光滑,因此就有其他的替代函数。
在激活函数里面,逻辑回归函数(Logistic Regression)是很常见的。其实通过逻辑回归函数,我们可以构造出近似的阶梯函数或者面具函数。
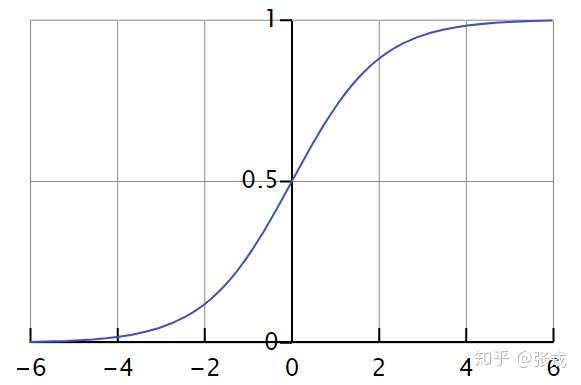
对于逻辑回归函数 而言,当
足够大的时候,
当
;
当
。此时的逻辑回归函数近似于一个阶梯函数。如果假设
,那么
就是光滑一点的阶梯函数,
当
;
当
。
因此,基于以上的分析和假设,我们可以构造如下的函数: 其中,
表示图片需要关注的区域,
函数就是
这里的
函数对应了一个足够大的
值。
当然,从一张完整的图片到小图片,在实际操作的时候,需要把小图片继续放大,在放大的过程中,可以考虑使用双线性插值算法来扩大。也就是说:
其中 ,
表示上采样因子,
分别表示一个实数的正数部分和小数部分。
在分类(Classification)和排序(Ranking)部分,RA-CNN 也有着自己的方法论。在损失函数(Loss Function)里面有两个重要的部分,第一个部分就是三幅图片的 LOSS 函数相加,也就是所谓的 classification loss, 表示预测类别的概率,
表示真实的类别。除此之外,另外一个部分就是排序的部分,
其中
表示在第
个尺寸下所得到的类别
的预测概率,并且最大值函数强制了该深度学习模型在训练中可以保证
,也就是说,局部预测的概率值应该高于整体的概率值。
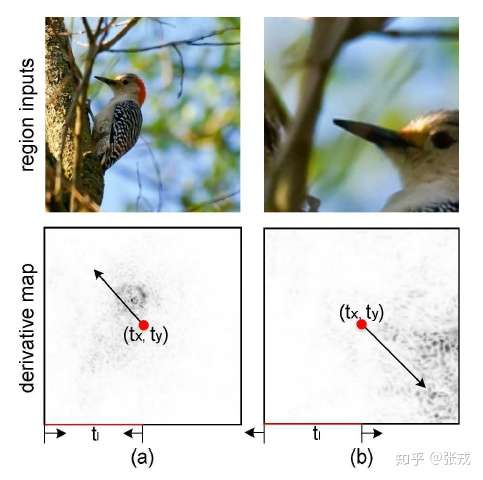
在这种 Attention 机制下,可以使用训练好的 conv5_4 或者 VGG-19 来进行特征的提取。在图像领域,location 的位置是需要通过训练而得到的,因为每张图片的鸟的位置都有所不同。进一步通过数学计算可以得到, 会随着网络而变得越来越小,也就是一个层次递进的关系,越来越关注到局部信息的提取。简单来看,
这里的 表示元素的点乘,
表示之前的网络所得到的导数。
当
当
其余情况,
当
当
其余情况,
当
其余情况,
因此, 在迭代的过程中会越来越小,也就是说关注的区域会越来越集中。
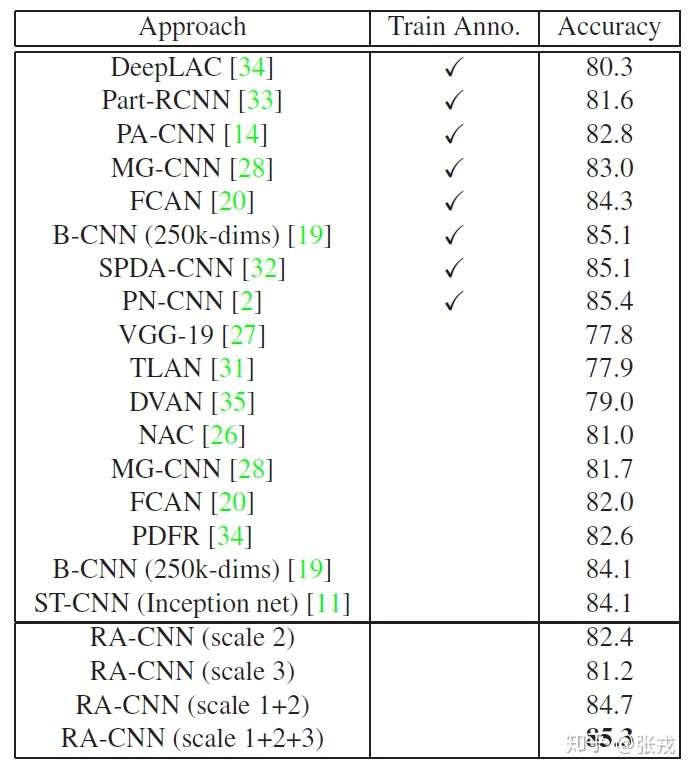
RA-CNN 的实验效果如下:
Multiple Granularity Descriptors for Fine-grained Categorization
这篇文中同样做了鸟类的分类工作,与 RA-CNN 不同之处在于它使用了层次的结构,因为鸟类的区分是按照一定的层次关系来进行的,粗糙来看,有科 -> 属 -> 种三个层次结构。
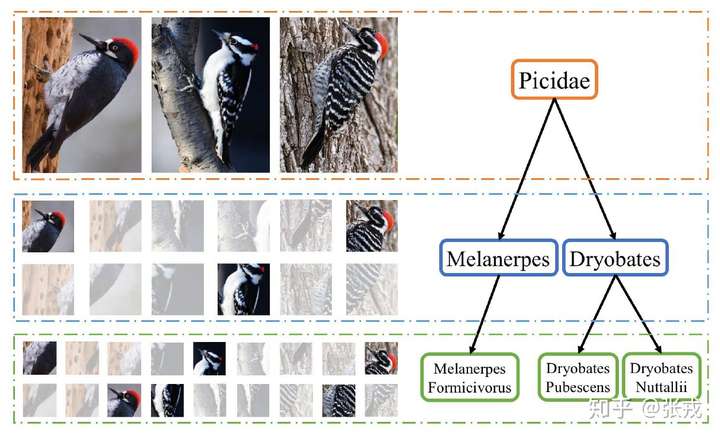
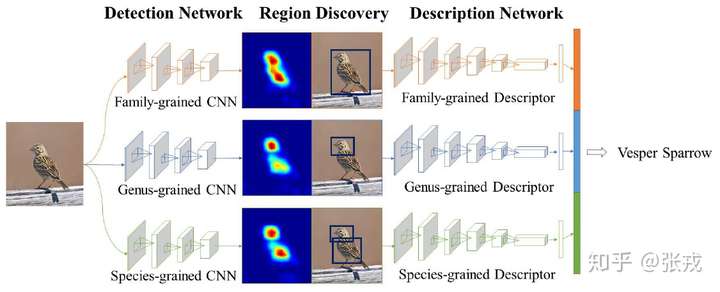
因此,在设计网络结构的过程中,需要有并行的网络结构,分别对应科,属,种三个层次。从前往后的顺序是检测网络(Detection Network),区域发现(Region Discovery),描述网络(Description Network)。并行的结构是 Family-grained CNN + Family-grained Descriptor,Genus-grained CNN + Genus-grained Descriptor,Species-grained CNN + Species-grained Descriptor。而在区域发现的地方,作者使用了 energy 的思想,让神经网络分别聚焦在图片中的不同部分,最终的到鸟类的预测结果。

Recurrent Models of Visual Attention
在计算机视觉中引入注意力机制,DeepMind 的这篇文章 recurrent models of visual attention 发表于 2014 年。在这篇文章中,作者使用了基于强化学习方法的注意力机制,并且使用收益函数来进行模型的训练。从网络结构来看,不仅从整体来观察图片,也从局部来提取必要的信息。
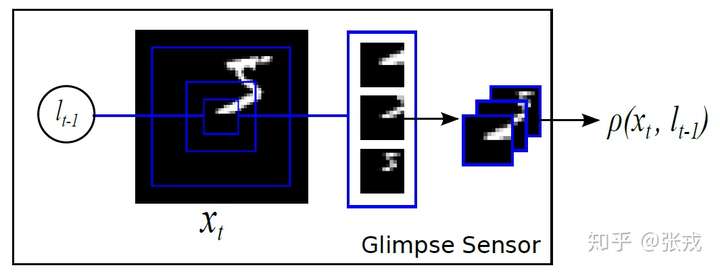
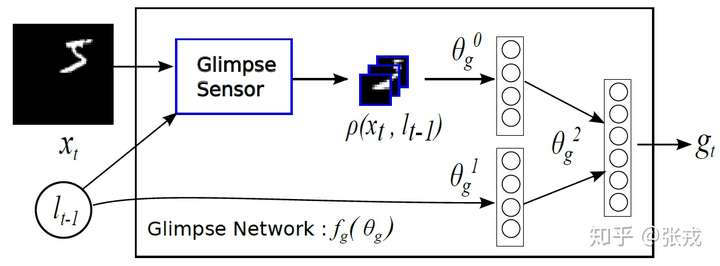
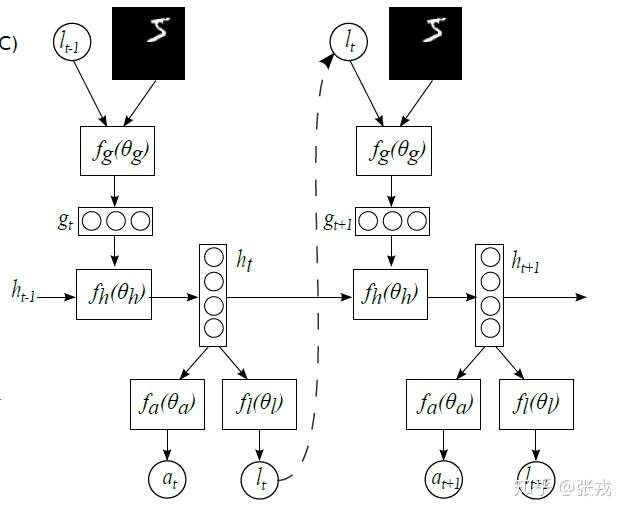
整体来看,其网络结构是 RNN,上一个阶段得到的信息和坐标会被传递到下一个阶段。这个网络只在最后一步进行分类的概率判断,这是与 RA-CNN 不同之处。这是为了模拟人类看物品的方式,人类并非会一直把注意力放在整张图片上,而是按照某种潜在的顺序对图像进行扫描。Recurrent Models of Visual Attention 本质上是把图片按照某种时间序列的形式进行输入,一次处理原始图片的一部分信息,并且在处理信息的过程中,需要根据过去的信息和任务选择下一个合适的位置进行处理。这样就可以不需要进行事先的位置标记和物品定位了。
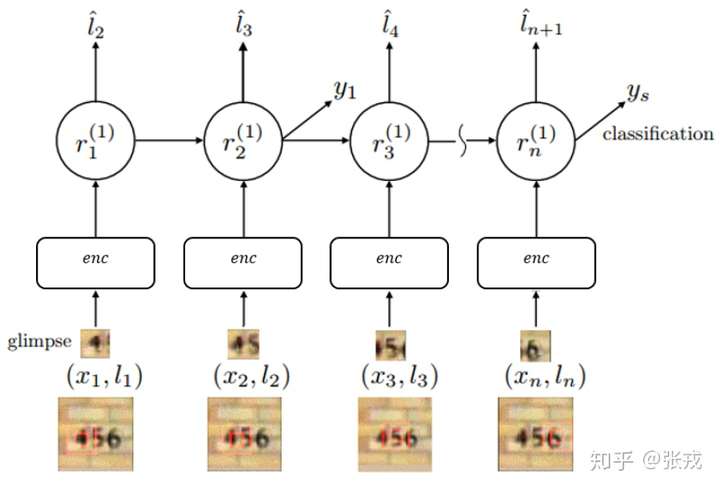
正如上图所示,enc 指的是对图片进行编码, 表示解码的过程,
表示图片的一个子区域。而
表示对图片的预测概率或者预测标签。
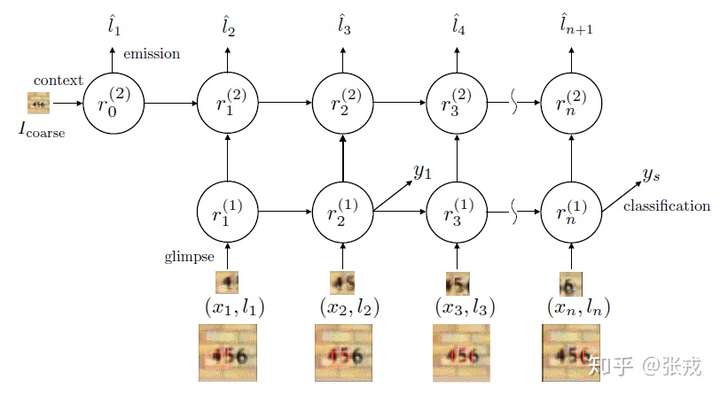
Multiple Object Recognition with Visual Attention
这篇文章同样是 DeepMind 的论文,与 Recurrent Models of Visual Attention 不同之处在于,它是一个两层的 RNN 结构,并且在最上层把原始图片进行输入。其中 enc 是编码网络, 是解码网络,
是注意力网络,输出概率在解码网络的最后一个单元输出。
在门牌识别里面,该网络是按照从左到右的顺序来进行图片扫描的,这与人类识别物品的方式极其相似。除了门牌识别之外,该论文也对手写字体进行了识别,同样取得了不错的效果。
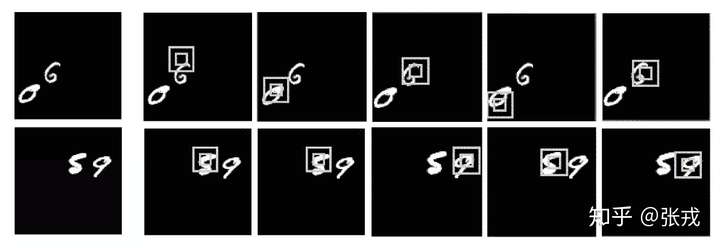

实验效果如下:
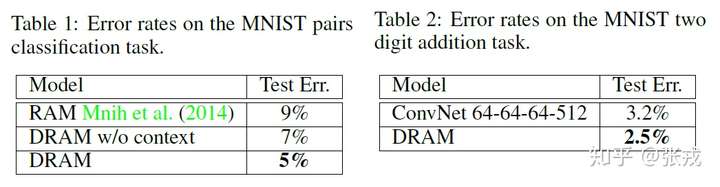
总结
本篇 Blog 初步介绍了计算机视觉中的 Attention 机制,除了这些方法之外,应该还有一些更巧妙的方法,希望各位读者多多指教。
参考文献
- Look Closer to See Better:Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition,CVPR,2017.
- Recurrent Models of Visual Attention,NIPS,2014
- GitHub 代码:Recurrent-Attention-CNN,https://github.com/Jianlong-Fu/Recurrent-Attention-CNN
- Multiple Granularity Descriptors for Fine-grained Categorization,ICCV,2015
- Multiple Object Recognition with Visual Attention,ICRL,2015
- Understanding LSTM Networks,Colah's Blog,2015,http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- Survey on the attention based RNN model and its applications in computer vision,2016
注意力模型最近几年在深度学习各个领域被广泛使用,无论是图像处理、语音识别还是自然语言处理的各种不同类型的任务中,都很容易遇到注意力模型的身影。所以,了解注意力机制的工作原理对于关注深度学习技术发展的技术人员来说有很大的必要。
人类的视觉注意力
从注意力模型的命名方式看,很明显其借鉴了人类的注意力机制,因此,我们首先简单介绍人类视觉的选择性注意力机制。
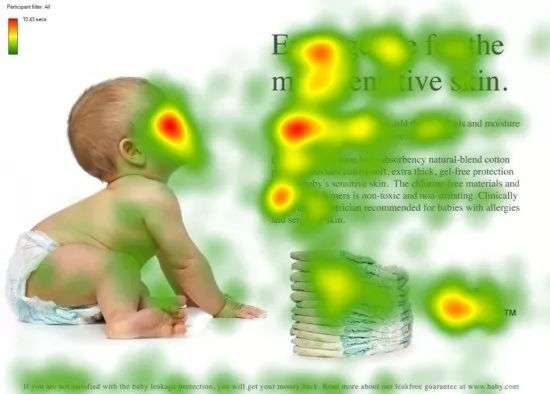
图1 人类的视觉注意力
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
图1形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标,很明显对于图1所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
Encoder-Decoder框架
要了解深度学习中的注意力模型,就不得不先谈Encoder-Decoder框架,因为目前大多数注意力模型附着在Encoder-Decoder框架下,当然,其实注意力模型可以看作一种通用的思想,本身并不依赖于特定框架,这点需要注意。
Encoder-Decoder框架可以看作是一种深度学习领域的研究模式,应用场景异常广泛。图2是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示。
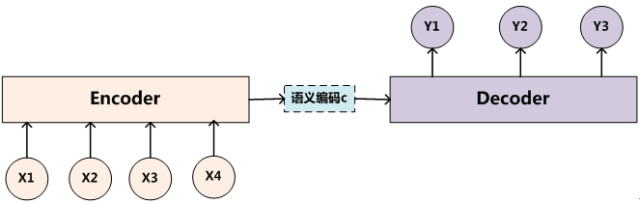
图2 抽象的文本处理领域的Encoder-Decoder框架
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成:
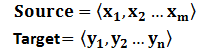
Encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
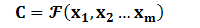
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息

来生成i时刻要生成的单词
:
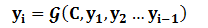
每个yi都依次这么产生,那么看起来就是整个系统根据输入句子Source生成了目标句子Target。如果Source是中文句子,Target是英文句子,那么这就是解决机器翻译问题的Encoder-Decoder框架;如果Source是一篇文章,Target是概括性的几句描述语句,那么这是文本摘要的Encoder-Decoder框架;如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。由此可见,在文本处理领域,Encoder-Decoder的应用领域相当广泛。
Encoder-Decoder框架不仅仅在文本领域广泛使用,在语音识别、图像处理等领域也经常使用。比如对于语音识别来说,图2所示的框架完全适用,区别无非是Encoder部分的输入是语音流,输出是对应的文本信息;而对于“图像描述”任务来说,Encoder部分的输入是一副图片,Decoder的输出是能够描述图片语义内容的一句描述语。一般而言,文本处理和语音识别的Encoder部分通常采用RNN模型,图像处理的Encoder一般采用CNN模型。
Attention模型
本节先以机器翻译作为例子讲解最常见的Soft Attention模型的基本原理,之后抛离Encoder-Decoder框架抽象出了注意力机制的本质思想,然后简单介绍最近广为使用的Self Attention的基本思路。
Soft Attention模型
图2中展示的Encoder-Decoder框架是没有体现出“注意力模型”的,所以可以把它看作是注意力不集中的分心模型。为什么说它注意力不集中呢?请观察下目标句子Target中每个单词的生成过程如下:
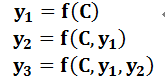
其中f是Decoder的非线性变换函数。从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子Source的语义编码C都是一样的,没有任何区别。
而语义编码C是由句子Source的每个单词经过Encoder 编码产生的,这意味着不论是生成哪个单词,y1,y2还是y3,其实句子Source中任意单词对生成某个目标单词yi来说影响力都是相同的,这是为何说这个模型没有体现出注意力的缘由。这类似于人类看到眼前的画面,但是眼中却没有注意焦点一样。
如果拿机器翻译来解释这个分心模型的Encoder-Decoder框架更好理解,比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。
在翻译“杰瑞”这个中文单词的时候,分心模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,但是分心模型是无法体现这一点的,这就是为何说它没有引入注意力的原因。
没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息,这也是为何要引入注意力模型的重要原因。
上面的例子中,如果引入Attention模型的话,应该在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
(Tom,0.3)(Chase,0.2) (Jerry,0.5)
每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。这对于正确翻译目标语单词肯定是有帮助的,因为引入了新的信息。
同理,目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词yi的时候,原先都是相同的中间语义表示C会被替换成根据当前生成单词而不断变化的Ci。理解Attention模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。增加了注意力模型的Encoder-Decoder框架理解起来如图3所示。
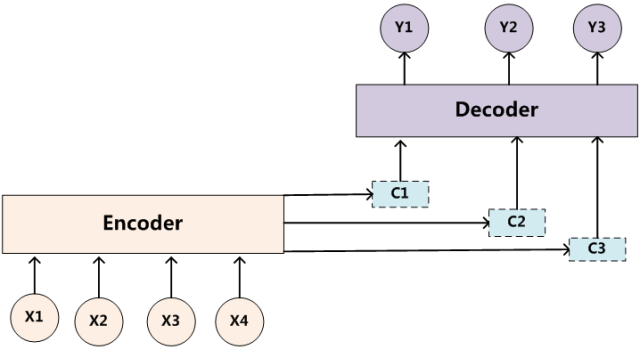
图3 引入注意力模型的Encoder-Decoder框架
即生成目标句子单词的过程成了下面的形式:
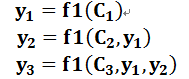
而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:

其中,f2函数代表Encoder对输入英文单词的某种变换函数,比如如果Encoder是用的RNN模型的话,这个f2函数的结果往往是某个时刻输入xi后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,即下列公式:
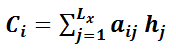
其中,Lx代表输入句子Source的长度,aij代表在Target输出第i个单词时Source输入句子中第j个单词的注意力分配系数,而hj则是Source输入句子中第j个单词的语义编码。假设下标i就是上面例子所说的“ 汤姆” ,那么Lx就是3,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”)分别是输入句子每个单词的语义编码,对应的注意力模型权值则分别是0.6,0.2,0.2,所以g函数本质上就是个加权求和函数。如果形象表示的话,翻译中文单词“汤姆”的时候,数学公式对应的中间语义表示Ci的形成过程类似图4。
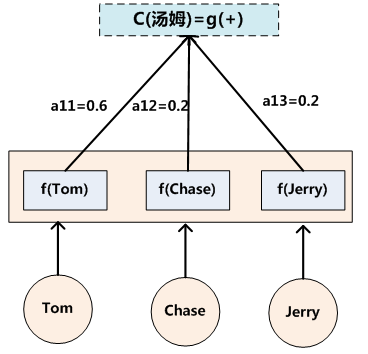
图4 Attention的形成过程
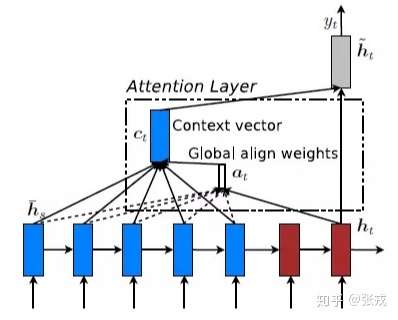
这里还有一个问题:生成目标句子某个单词,比如“汤姆”的时候,如何知道Attention模型所需要的输入句子单词注意力分配概率分布值呢?就是说“汤姆”对应的输入句子Source中各个单词的概率分布:(Tom,0.6)(Chase,0.2) (Jerry,0.2) 是如何得到的呢?
为了便于说明,我们假设对图2的非Attention模型的Encoder-Decoder框架进行细化,Encoder采用RNN模型,Decoder也采用RNN模型,这是比较常见的一种模型配置,则图2的框架转换为图5。
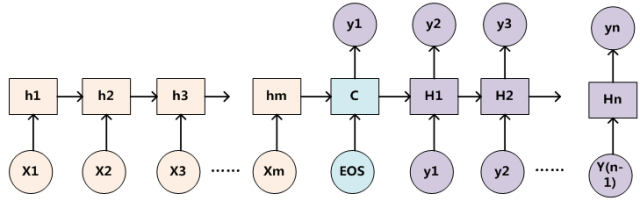
图5 RNN作为具体模型的Encoder-Decoder框架
那么用图6可以较为便捷地说明注意力分配概率分布值的通用计算过程。
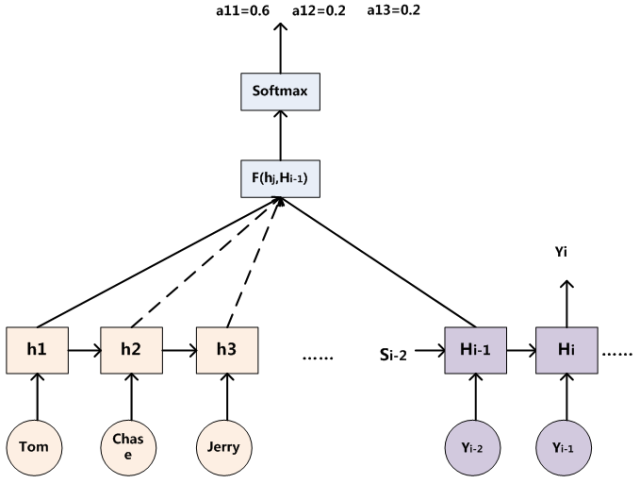
图6 注意力分配概率计算
对于采用RNN的Decoder来说,在时刻i,如果要生成yi单词,我们是可以知道Target在生成Yi之前的时刻i-1时,隐层节点i-1时刻的输出值Hi-1的,而我们的目的是要计算生成Yi时输入句子中的单词“Tom”、“Chase”、“Jerry”对Yi来说的注意力分配概率分布,那么可以用Target输出句子i-1时刻的隐层节点状态Hi-1去一一和输入句子Source中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数F(hj,Hi-1)来获得目标单词yi和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
绝大多数Attention模型都是采取上述的计算框架来计算注意力分配概率分布信息,区别只是在F的定义上可能有所不同。图7可视化地展示了在英语-德语翻译系统中加入Attention机制后,Source和Target两个句子每个单词对应的注意力分配概率分布。
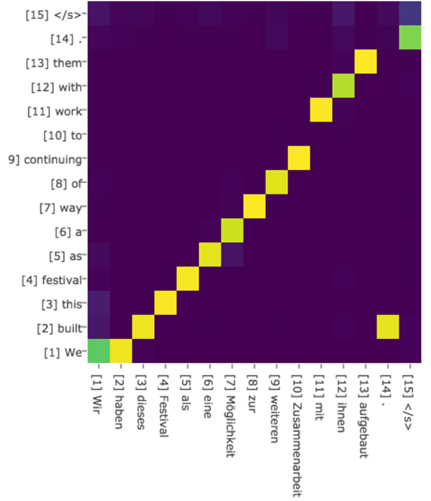
图7 英语-德语翻译的注意力概率分布
上述内容就是经典的Soft Attention模型的基本思想,那么怎么理解Attention模型的物理含义呢?一般在自然语言处理应用里会把Attention模型看作是输出Target句子中某个单词和输入Source句子每个单词的对齐模型,这是非常有道理的。
目标句子生成的每个单词对应输入句子单词的概率分布可以理解为输入句子单词和这个目标生成单词的对齐概率,这在机器翻译语境下是非常直观的:传统的统计机器翻译一般在做的过程中会专门有一个短语对齐的步骤,而注意力模型其实起的是相同的作用。
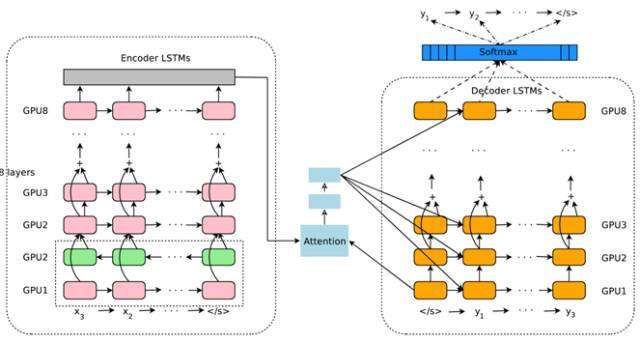
图8 Google 神经网络机器翻译系统结构图
图8所示即为Google于2016年部署到线上的基于神经网络的机器翻译系统,相对传统模型翻译效果有大幅提升,翻译错误率降低了60%,其架构就是上文所述的加上Attention机制的Encoder-Decoder框架,主要区别无非是其Encoder和Decoder使用了8层叠加的LSTM模型。
Attention机制的本质思想
如果把Attention机制从上文讲述例子中的Encoder-Decoder框架中剥离,并进一步做抽象,可以更容易看懂Attention机制的本质思想。
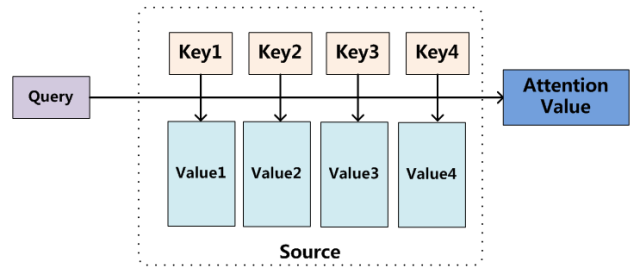
图9 Attention机制的本质思想
我们可以这样来看待Attention机制(参考图9):将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式:
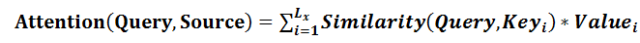
其中,Lx=||Source||代表Source的长度,公式含义即如上所述。上文所举的机器翻译的例子里,因为在计算Attention的过程中,Source中的Key和Value合二为一,指向的是同一个东西,也即输入句子中每个单词对应的语义编码,所以可能不容易看出这种能够体现本质思想的结构。
当然,从概念上理解,把Attention仍然理解为从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息,这种思路仍然成立。聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
从图9可以引出另外一种理解,也可以将Attention机制看作一种软寻址(Soft Addressing):Source可以看作存储器内存储的内容,元素由地址Key和值Value组成,当前有个Key=Query的查询,目的是取出存储器中对应的Value值,即Attention数值。通过Query和存储器内元素Key的地址进行相似性比较来寻址,之所以说是软寻址,指的不像一般寻址只从存储内容里面找出一条内容,而是可能从每个Key地址都会取出内容,取出内容的重要性根据Query和Key的相似性来决定,之后对Value进行加权求和,这样就可以取出最终的Value值,也即Attention值。所以不少研究人员将Attention机制看作软寻址的一种特例,这也是非常有道理的。
至于Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将Attention的计算过程抽象为如图10展示的三个阶段。
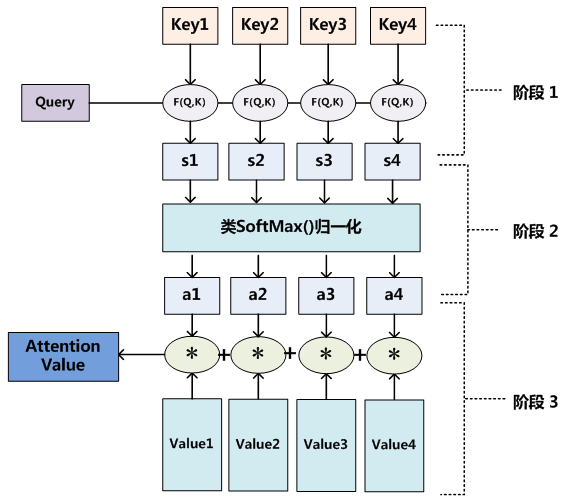
图10 三阶段计算Attention过程
在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个Key_i,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:

第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:
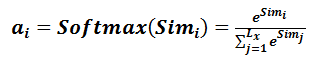
第二阶段的计算结果a_i即为value_i对应的权重系数,然后进行加权求和即可得到Attention数值:

通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。
Self Attention模型
通过上述对Attention本质思想的梳理,我们可以更容易理解本节介绍的Self Attention模型。Self Attention也经常被称为intra Attention(内部Attention),最近一年也获得了比较广泛的使用,比如Google最新的机器翻译模型内部大量采用了Self Attention模型。
在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素Query和Source中的所有元素之间。而Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。其具体计算过程是一样的,只是计算对象发生了变化而已,所以此处不再赘述其计算过程细节。
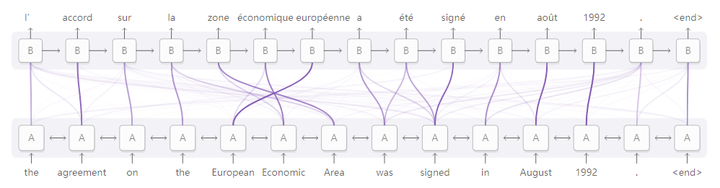
如果是常规的Target不等于Source情形下的注意力计算,其物理含义正如上文所讲,比如对于机器翻译来说,本质上是目标语单词和源语单词之间的一种单词对齐机制。那么如果是Self Attention机制,一个很自然的问题是:通过Self Attention到底学到了哪些规律或者抽取出了哪些特征呢?或者说引入Self Attention有什么增益或者好处呢?我们仍然以机器翻译中的Self Attention来说明,图11和图12是可视化地表示Self Attention在同一个英语句子内单词间产生的联系。
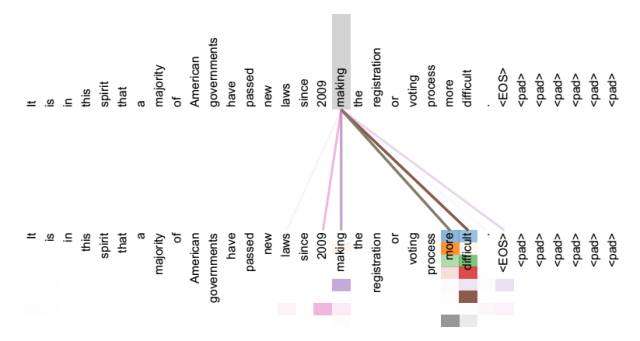
图11 可视化Self Attention实例
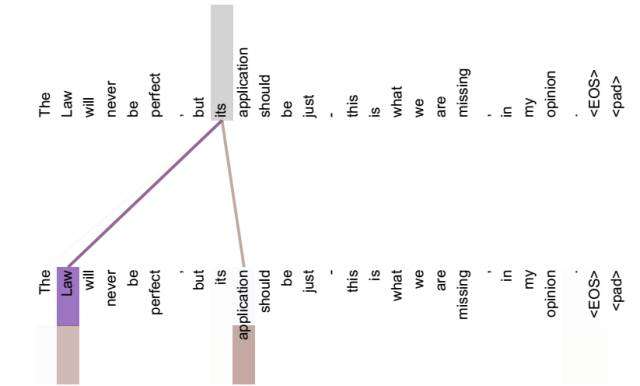
图12 可视化Self Attention实例
从两张图(图11、图12)可以看出,Self Attention可以捕获同一个句子中单词之间的一些句法特征(比如图11展示的有一定距离的短语结构)或者语义特征(比如图12展示的its的指代对象Law)。
很明显,引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此外,Self Attention对于增加计算的并行性也有直接帮助作用。这是为何Self Attention逐渐被广泛使用的主要原因。
Attention机制的应用
前文有述,Attention机制在深度学习的各种应用领域都有广泛的使用场景。上文在介绍过程中我们主要以自然语言处理中的机器翻译任务作为例子,下面分别再从图像处理领域和语音识别选择典型应用实例来对其应用做简单说明。
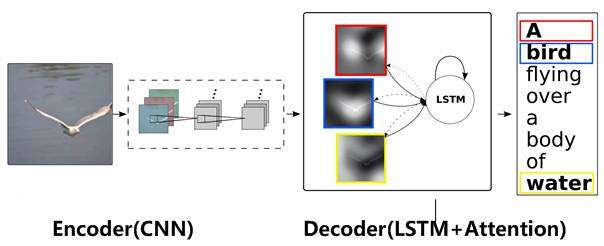
图13 图片-描述任务的Encoder-Decoder框架
图片描述(Image-Caption)是一种典型的图文结合的深度学习应用,输入一张图片,人工智能系统输出一句描述句子,语义等价地描述图片所示内容。很明显这种应用场景也可以使用Encoder-Decoder框架来解决任务目标,此时Encoder输入部分是一张图片,一般会用CNN来对图片进行特征抽取,Decoder部分使用RNN或者LSTM来输出自然语言句子(参考图13)。
此时如果加入Attention机制能够明显改善系统输出效果,Attention模型在这里起到了类似人类视觉选择性注意的机制,在输出某个实体单词的时候会将注意力焦点聚焦在图片中相应的区域上。图14给出了根据给定图片生成句子“A person is standing on a beach with a surfboard.”过程时每个单词对应图片中的注意力聚焦区域。

图14 图片生成句子中每个单词时的注意力聚焦区域
图15给出了另外四个例子形象地展示了这种过程,每个例子上方左侧是输入的原图,下方句子是人工智能系统自动产生的描述语句,上方右侧图展示了当AI系统产生语句中划横线单词的时候,对应图片中聚焦的位置区域。比如当输出单词dog的时候,AI系统会将注意力更多地分配给图片中小狗对应的位置。

图15 图像描述任务中Attention机制的聚焦作用
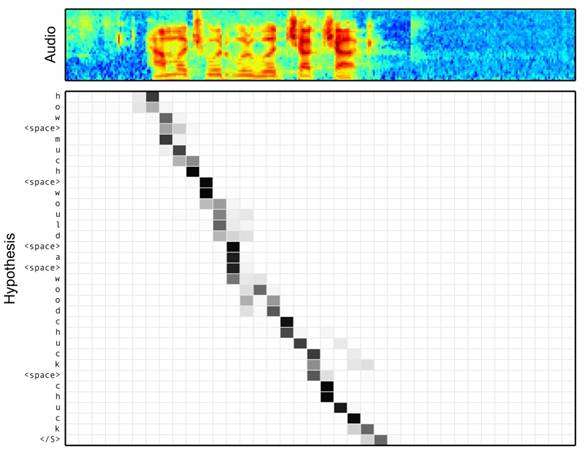
图16 语音识别中音频序列和输出字符之间的Attention
语音识别的任务目标是将语音流信号转换成文字,所以也是Encoder-Decoder的典型应用场景。Encoder部分的Source输入是语音流信号,Decoder部分输出语音对应的字符串流。
图16可视化地展示了在Encoder-Decoder框架中加入Attention机制后,当用户用语音说句子 how much would a woodchuck chuck 时,输入部分的声音特征信号和输出字符之间的注意力分配概率分布情况,颜色越深代表分配到的注意力概率越高。从图中可以看出,在这个场景下,Attention机制起到了将输出字符和输入语音信号进行对齐的功能。
上述内容仅仅选取了不同AI领域的几个典型Attention机制应用实例,Encoder-Decoder加Attention架构由于其卓越的实际效果,目前在深度学习领域里得到了广泛的使用,了解并熟练使用这一架构对于解决实际问题会有极大帮助。
谢邀。一年前的这个时候,梳理过Attention的相关工作,Attention可以从多个角度上进行认识:
1. 首先是Object Recognition。我是从Recurrent Model of Visual Attention (RAM)开始关注Attention的,作者是DeepMind 的Mnih (Hinton高徒),加上后面他的师弟Jimmy在DeepMind 实习期间发的这个工作的后续Multiple Object Recognition with Visual Attention(DRAM),都是比较有趣的工作。说其有趣,是因为模型结合了CNN,RNN 和 Reinforcement Learning,来解决问题。值得注意的是,这两篇文章属于提出新思路,实验都只是在变换的MNIST上做的,放在实际场景数据集上未必work(我出于兴趣复现了tf版的DRAM,并且在其上对它进行很大程度了改进,并引入了weakly supervised的因素,虽在变换的MNIST上表现很好,后面我尝试过拿他来在现实场景的datasets上做实验,但是效果不好;也尝试了拿它做车辆的细粒度分类,同样没有直接拿一个 CNN 效果好(可能是我太不才,求交流))。跟前两篇方法类似,用attention来做图像生成,如DRAW: A Recurrent Neural Network For Image Generation 来序列地生成数字。
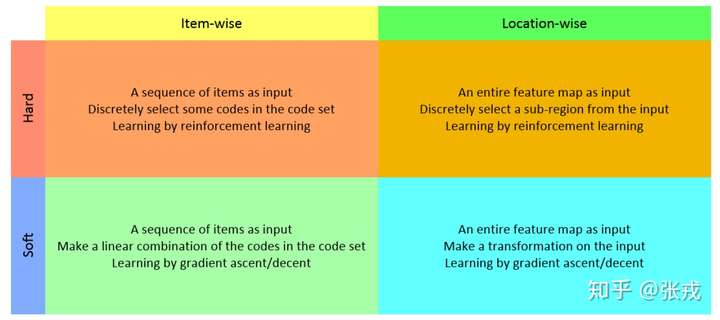
2. 然后是Image Caption。Xu在ICML上的 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention可谓应用Attetion来解image caption的经典。该文中也总结出Soft attention 和 Hard attention。soft是拿deterministic的分布作为权重进行加权,hard是从分布上stochastic 采样。这类工作也是用RNN逐渐进行处理的。
3. NLP中的Machine Translation. 前面的工作都是用时序地进行Attention来关注一幅图像的不同位置区域。类比sequence问题,也就顺理成章地用在Machine Translation上了,同样是时序的关注不同历史特征来出每一个翻译词汇。Attention用在Machine Translation上的文章很多,具体可关注Bengio组的工作,比如neural machine translation。
4. 不使用RNN结构。在特征图上生成空间分布的权重,然后再对特征图加权求和,试图让网络学出来对不同物体区域加以不同关注度。之后的在CV领域中应用attention绝大多数都是这么干的。例如,spatial transformer networks(STN)是之后将attention用于物体识别比较有名的一篇文章,在一些现实应用中仍被使用。再如residual attention network.
5. 总结与泛化。划重点:attention机制听起来高达上,其实就是学出一个权重分布,再拿这个权重分布施加在原来的特征之上,就可以叫做attention。简单来说:
(1)这个加权可以是保留所有分量均做加权(即soft attention);也可以是在分布中以某种采样策略选取部分分量(即hard attention)。
(2)这个加权可以作用在原图上,也就是RAM和DRAM;也可以作用在特征图上,如后续的好多文章(例如image caption)。
(3)这个加权可以作用在空间尺度上,给不同空间区域加权;也可以作用在channel尺度上,给不同通道特征加权;甚至特征图上每个元素加权。
(4)这个加权还可以作用在不同时刻历史特征上,如Machine Translation,以及我前段时间做的视频相关的工作。
所以说,Attention是啥啊?不就是一个权重分布嘛,搞得玄乎其玄~
更新: 感谢评论指正,是Show, Attend and Tell这篇文章把attention分成了soft和hard两种。
———以下为原答案
谢邀,我本身没有在实践中用到过attention,所看到的只是论文中的内容,所以和实际不符的话请指出。
attention最早应该出现在2014年bengio的neural machine translation论文上面,在seq2seq问题上引入attention,你可以理解为给你一段文字,脑中形成一些关于这段文字的记忆,要求你根据这段文字继续往下写,你就会关注和邻近文字相关的内容,或者关注和你当前写的内容相关的以往文字,使得写出来的内容通畅。这篇论文里分了两种attention,一种是soft attention,可以求导,作反向传播来更新权重。另外一种是hard attention,不可以求导,所以原作引入了强化学习来解决这个问题。
重点讲讲卷积网络上的attention吧,我本身也是做视觉的,和CNN打交道比较多。主要分为两种,一种是spatial attention, 另外一种是channel attention。
什么意思呢,CNN每一层都会输出一个C x H x W的特征图,C就是通道,代表卷积核的数量,亦为特征的数量,H 和W就是原始图片经过压缩后的图,spatial attention就是对于所有的通道,在二维平面上,对H x W尺寸的图学习到一个权重,对每个像素都会学习到一个权重。你可以想象成一个像素是C维的一个向量,深度是C,在C个维度上,权重都是一样的,但是在平面上,权重不一样。这方面的论文已经很多了,重点关注一下image/video caption。相反的,channel attention就是对每个C,在channel维度上,学习到不同的权重,平面维度上权重相同。spatial 和 channel attention可以理解为关注图片的不同区域和关注图片的不同特征。channel attention写的最好的一篇论文个人感觉是SCA-CNN,读完有一种”卧槽,原来这就是channel attention!”的感觉哈哈,我当时拿这篇论文给实验室导师看的时候,他说了句,卧槽,他把我想做的给做了 ,这就很气。
网络架构上,Squeeze and Excitation Network就是channel attention的典型代表,主要思想是卷积网络的卷积核所代表的特征之间存在冗余,他们起了个名字叫feature recalibration,可以看作是在不影响性能的前提下减少卷积核数量是等效的。同样的,实验室一个同学也想到了这种方法,在cifar10数据集提了20个点,后来和我说过以后,我说这不就是SeNet吗……
Attention机制在近几年来在图像,自然语言处理等领域中都取得了重要的突破,被证明有益于提高模型的性能。Attention机制本身也是符合人脑和人眼的感知机制,这里我们主要以计算机视觉领域为例,讲述Attention机制的原理,应用以及模型的发展。
1 Attention机制与显著图
1.1 何为Attention机制
所谓Attention机制,便是聚焦于局部信息的机制,比如图像中的某一个图像区域。随着任务的变化,注意力区域往往会发生变化。

面对上面这样的一张图,如果你只是从整体来看,只看到了很多人头,但是你拉近一个一个仔细看就了不得了,都是天才科学家。
图中除了人脸之外的信息其实都是无用的,也做不了什么任务,Attention机制便是要找到这些最有用的信息,可以想见最简单的场景就是从照片中检测人脸了。
1.2 基于Attention的显著目标检测
和注意力机制相伴而生的一个任务便是显著目标检测,即salient object detection。它的输入是一张图,输出是一张概率图,概率越大的地方,代表是图像中重要目标的概率越大,即人眼关注的重点,一个典型的显著图如下:

右图就是左图的显著图,在头部位置概率最大,另外腿部,尾巴也有较大概率,这就是图中真正有用的信息。
显著目标检测需要一个数据集,而这样的数据集的收集便是通过追踪多个实验者的眼球在一定时间内的注意力方向进行平均得到,典型的步骤如下:
(1) 让被测试者观察图。
(2) 用eye tracker记录眼睛的注意力位置。
(3) 对所有测试者的注意力位置使用高斯滤波进行综合。
(4) 结果以0~1的概率进行记录。
于是就能得到下面这样的图,第二行是眼球追踪结果,第三行就是显著目标概率图。

上面讲述的都是空间上的注意力机制,即关注的是不同空间位置,而在CNN结构中,还有不同的特征通道,因此不同特征通道也有类似的原理,下面一起讲述。
2 Attention模型架构
注意力机制的本质就是定位到感兴趣的信息,抑制无用信息,结果通常都是以概率图或者概率特征向量的形式展示,从原理上来说,主要分为空间注意力模型,通道注意力模型,空间和通道混合注意力模型三种,这里不区分soft和hard attention。
2.1 空间注意力模型(spatial attention)
不是图像中所有的区域对任务的贡献都是同样重要的,只有任务相关的区域才是需要关心的,比如分类任务的主体,空间注意力模型就是寻找网络中最重要的部位进行处理。
我们在这里给大家介绍两个具有代表性的模型,第一个就是Google DeepMind提出的STN网络(Spatial Transformer Network[1])。它通过学习输入的形变,从而完成适合任务的预处理操作,是一种基于空间的Attention模型,网络结构如下:
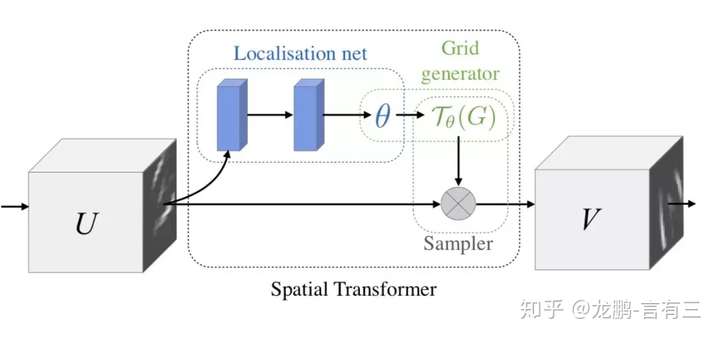
这里的Localization Net用于生成仿射变换系数,输入是C×H×W维的图像,输出是一个空间变换系数,它的大小根据要学习的变换类型而定,如果是仿射变换,则是一个6维向量。
这样的一个网络要完成的效果如下图:
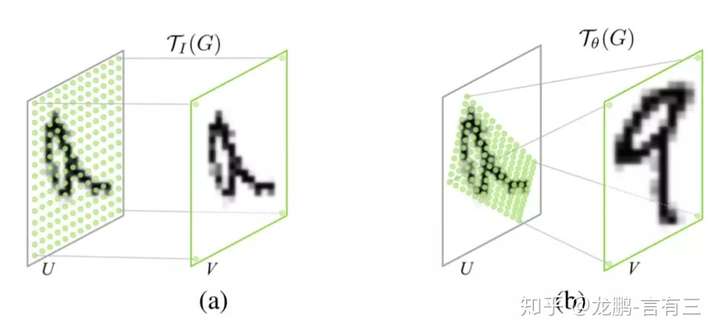
即定位到目标的位置,然后进行旋转等操作,使得输入样本更加容易学习。这是一种一步调整的解决方案,当然还有很多迭代调整的方案,感兴趣可以去有三知识星球星球中阅读。
相比于Spatial Transformer Networks 一步完成目标的定位和仿射变换调整,Dynamic Capacity Networks[2]则采用了两个子网络,分别是低性能的子网络(coarse model)和高性能的子网络(fine model)。低性能的子网络(coarse model)用于对全图进行处理,定位感兴趣区域,如下图中的操作fc。高性能的子网络(fine model)则对感兴趣区域进行精细化处理,如下图的操作ff。两者共同使用,可以获得更低的计算代价和更高的精度。
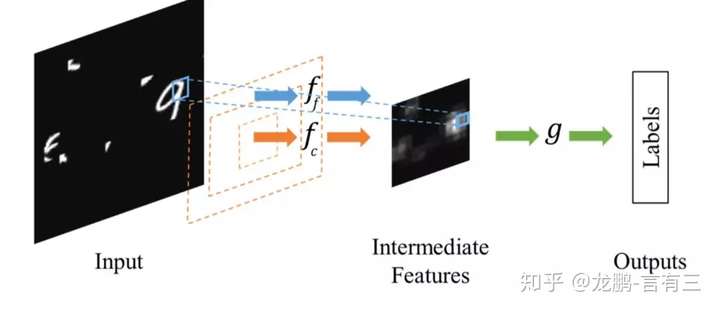
由于在大部分情况下我们感兴趣的区域只是图像中的一小部分,因此空间注意力的本质就是定位目标并进行一些变换或者获取权重。
2.2 通道注意力机制
对于输入2维图像的CNN来说,一个维度是图像的尺度空间,即长宽,另一个维度就是通道,因此基于通道的Attention也是很常用的机制。
SENet(Sequeeze and Excitation Net)[3]是2017届ImageNet分类比赛的冠军网络,本质上是一个基于通道的Attention模型,它通过建模各个特征通道的重要程度,然后针对不同的任务增强或者抑制不同的通道,原理图如下。
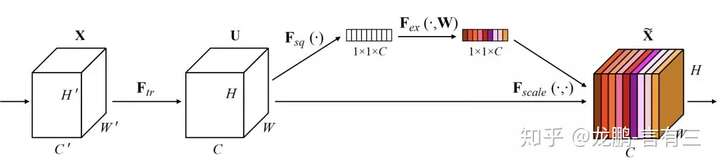
在正常的卷积操作后分出了一个旁路分支,首先进行Squeeze操作(即图中Fsq(·)),它将空间维度进行特征压缩,即每个二维的特征图变成一个实数,相当于具有全局感受野的池化操作,特征通道数不变。
然后是Excitation操作(即图中的Fex(·)),它通过参数w为每个特征通道生成权重,w被学习用来显式地建模特征通道间的相关性。在文章中,使用了一个2层bottleneck结构(先降维再升维)的全连接层+Sigmoid函数来实现。
得到了每一个特征通道的权重之后,就将该权重应用于原来的每个特征通道,基于特定的任务,就可以学习到不同通道的重要性。
将其机制应用于若干基准模型,在增加少量计算量的情况下,获得了更明显的性能提升。作为一种通用的设计思想,它可以被用于任何现有网络,具有较强的实践意义。而后SKNet[4]等方法将这样的通道加权的思想和Inception中的多分支网络结构进行结合,也实现了性能的提升。
通道注意力机制的本质,在于建模了各个特征之间的重要性,对于不同的任务可以根据输入进行特征分配,简单而有效。
2.3 空间和通道注意力机制的融合
前述的Dynamic Capacity Network是从空间维度进行Attention,SENet是从通道维度进行Attention,自然也可以同时使用空间Attention和通道Attention机制。
CBAM(Convolutional Block Attention Module)[5]是其中的代表性网络,结构如下:
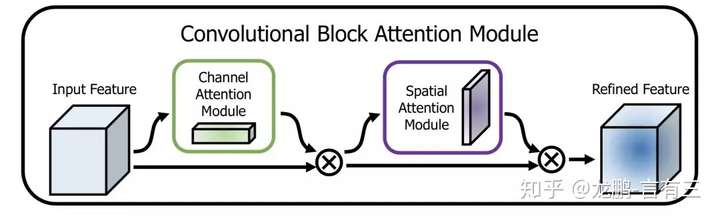
通道方向的Attention建模的是特征的重要性,结构如下:
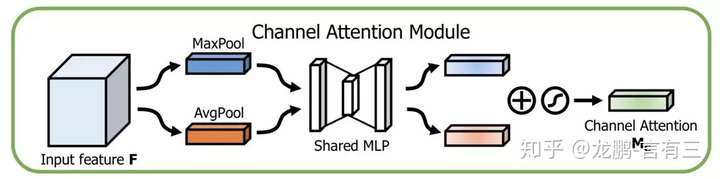
同时使用最大pooling和均值pooling算法,然后经过几个MLP层获得变换结果,最后分别应用于两个通道,使用sigmoid函数得到通道的attention结果。
空间方向的Attention建模的是空间位置的重要性,结构如下:
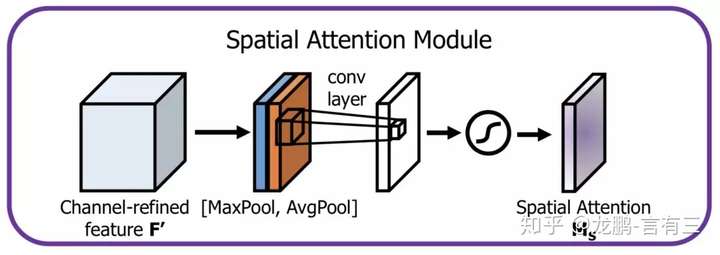
首先将通道本身进行降维,分别获取最大池化和均值池化结果,然后拼接成一个特征图,再使用一个卷积层进行学习。
这两种机制,分别学习了通道的重要性和空间的重要性,还可以很容易地嵌入到任何已知的框架中。
除此之外,还有很多的注意力机制相关的研究,比如残差注意力机制,多尺度注意力机制,递归注意力机制等。
感兴趣的同学可以去我们知识星球中阅读相关的网络结构主题。


3 Attention机制典型应用场景
从原理上来说,注意力机制在所有的计算机视觉任务中都能提升模型性能,但是有两类场景尤其受益。
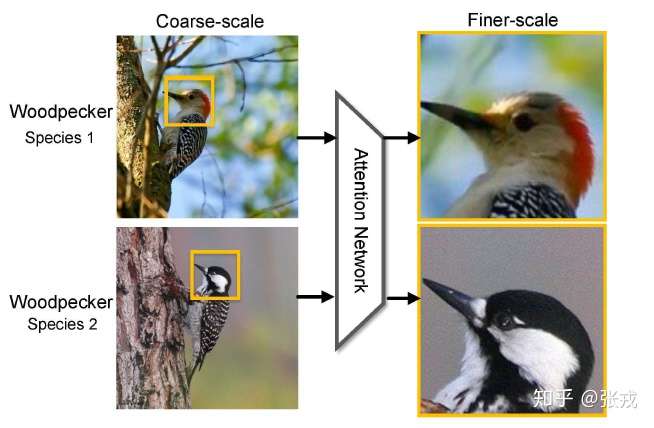
3.1 细粒度分类
关于细粒度分类的基础内容,可以参考。
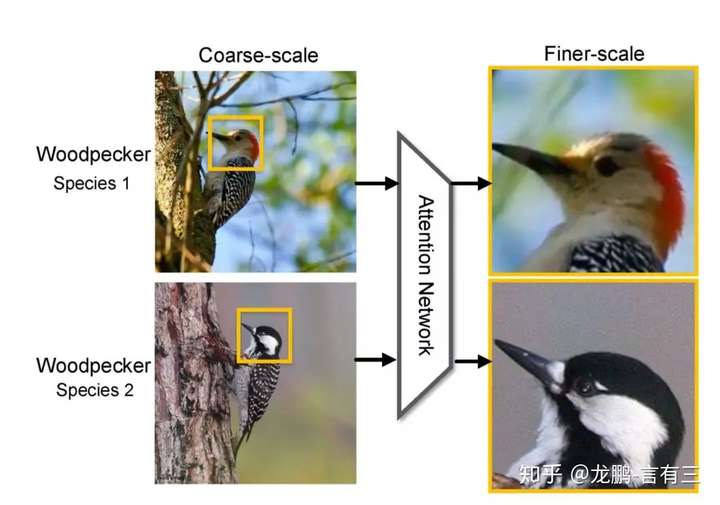
我们知道细粒度分类任务中真正的难题在于如何定位到真正对任务有用的局部区域,如上示意图中的鸟的头部。Attention机制恰巧原理上非常合适,文[1],[6]中都使用了注意力机制,对模型的提升效果很明显。
3.2 显著目标检测/缩略图生成/自动构图
我们又回到了开头,没错,Attention的本质就是重要/显著区域定位,所以在目标检测领域是非常有用的。


上图展示了几个显著目标检测的结果,可以看出对于有显著目标的图,概率图非常聚焦于目标主体,在网络中添加注意力机制模块,可以进一步提升这一类任务的模型。
除此之外,在视频分析,看图说话等任务中也比较重要,相关内容将在有三AI知识星球中每日更新。
[1] Jaderberg M, Simonyan K, Zisserman A. Spatial transformer networks[C]//Advances in neural information processing systems. 2015: 2017-2025.
[2] Almahairi A, Ballas N, Cooijmans T, et al. Dynamic capacity networks[C]//International Conference on Machine Learning. 2016: 2549-2558.
[3] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
[4] Li X, Wang W, Hu X, et al. Selective Kernel Networks[J]. 2019.
[5] Woo S, Park J, Lee J Y, et al. Cbam: Convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 3-19.
[6] Fu J, Zheng H, Mei T. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4438-4446.
总结
注意力机制是一个原理简单而有效的机制,符合人眼的视觉感知原理,在实现上也容易嵌入当前的主流模型架构,是值得采用和学习的技术。
我理解的attention方法就是引入一层全连接层或者卷积层用非监督的方式(因为训练没有提供attention的groundtruth)让模型自动学习不同part的权重,之前的回答已经总结得很好了。
因为我的博士工作跟attention也有很多相关,在这里“不知羞耻”地做下广告:
- 关于spatial attention model, 我们关于基于人脸视频的年龄估计的一篇论文中提出了在CNN里嵌入一层attention layer,有些类似于“show, attend and tell”的soft attention, 不过我们的attention layer是在夹在convolutional layers之间的,而且我们提出了一种所谓的spatially-index attention机制,采用individual weight和shared weight相结合的方式 用来capture更细微的variation。
- 关于temporal attention model, 我们在关于sequence classification的一篇论文中将attention以gate的方式引入到RNN模型中,用来学习每一个time step的attention weight。
谢谢大家关注。
 Inter Attention Weights [1]
Inter Attention Weights [1]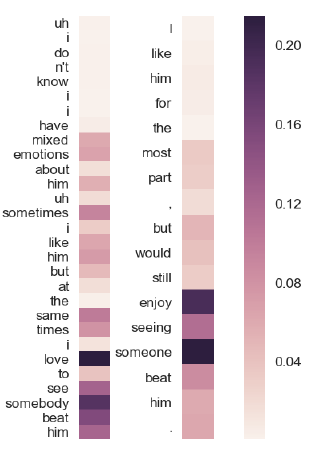 Intra Attention Weights [3]
Intra Attention Weights [3]
Keras实现代码:
- Inter Attention: https://github.com/codekansas/keras-language-modeling/blob/master/attention_lstm.py#L8
- Intra Attention: https://github.com/yanghanxy/CIAN/blob/master/model_library.py#L109
[1] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2014. Neural machine translation by jointly learning to align and translate. CoRR abs/1409.0473.
[2] Yang, Z., Yang, D., Dyer, C., He, X., Smola, A., & Hovy, E. (2016). Hierarchical attention networks for document classification. In Proceedings of NAACL-HLT (pp. 1480-1489).
[3] Yang, H., Costa-jussà, M. R., & Fonollosa, J. A. (2017). Character-level Intra Attention Network for Natural Language Inference. In Proceedings of the 2nd Workshop on Evaluating Vector Space Representations for NLP (pp. 46-50).
“Attention,Attention,还是Attention,看了三篇顶会论文,现在CVPR、ICCV都这么好发了么,随随便便加个Attention就算了不得的创新点?”这是曾经有段时间实验室大家读paper后很统一的的槽点。

你可能还在通过不断增加卷积层、池化层、全连接层以尽量让自己的网络结构“看起来”和别人的不太一样,也可能还在琢磨怎么从图像分割领域“借”点东西过来应用于图像识别领域。
对于很多科研小白来说,好不容易啃完了50+篇paper,脑子里灵光一闪顿悟了一个写下来手都直打哆嗦的创新点。然后发现了一个比想不到创新点更残酷的事实——一篇小论文里只有一个创新点还远远不够。
其他创新点那就只能尽量靠“凑”。
神经网络本身就有点玄学的味道,你可不知道加进去哪味佐料就能炼出来一颗神丹妙药。而这味“Attention”原料经很多神经网络的专业炼丹师妙手验证,它确实百搭又好用。
所以当你还在为小论文的创新点抓耳挠腮一筹莫展时,不妨试试神经网络结构里的百搭小助手---Attention注意力机制。

当“易上手”Keras遇上“百搭”Attention
随着TensorFlow 2.0发布,Keras实现的深层网络开始备受开发者关注。在TensorFlow 2.0中,Keras可以利用以下三个强大的高层神经网络API实现深度网络。
· sequence API——这是最简单的API,首先调动 model = Sequential()并不断添加层,例如 model.add(Dense(...)) .
· 函数式API——高级API,创建自定义模式,随机输入/输出。此处定义模块要小心谨慎,随便一点微小改动都会影响用户端。定义模型可以使用model = Model(inputs=[...],outputs=[...]) .
· 子类化API——高级API,可以将该模型定义为Python类。这里,在属类中定义模型的前向传递,Keras自动计算后向传递。
 图片来源:Keras官方文档 主页
图片来源:Keras官方文档 主页
Keras作为一个专为支持快速实验而生的高层神经网咯API,与Tensorflow、Pytorch、Caffe这类深度学习框架相比,它更像是个神经网络接口。尽管它提供的底层弹性和灵活性要逊色于其他几种深度学习框架,然而它的模块高度封装,对用户非常友好,最易上手,用它把想法迅速输出为结果通常来说是不二之选。
所以,当你需要快速创建一个神经网络,并测试你的网络模块添加或删减得是否那么“得当”,不妨尝试使用下Keras这个非常好上手的API。
而上面说的Attention注意力机制,其实类似神经网络是参考人类大脑神经元的工作原理发展而来,Attention注意力模型也是巧妙借鉴了人类在发展过程中对于必要信息的着重关注同时自动忽略非必要信息的视觉注意力提取机制原理。
接下来,本篇将先从介绍“‘序列-序列’模型”入手,然后通过介绍“Attention注意力机制的实质”来表明为什么Attention机制对于序列-序列的模型来说非常重要,最后通过实例用Keras快速实现Attention Layer。

“序列-序列”模型
“序列-序列”模型(Sequence to Sequence Model)是深度学习模型的强大分支,旨在解决机器学习领域中最棘手的问题。例如:
· 机器翻译
· 聊天机器人
· 文本摘要
每个问题都分别面临着各自特定的挑战。例如,机器翻译必须处理不同的词序拓扑(即主谓宾语序)。因此,此“序列-序列”模型是解决复杂的神经语言程序学相关问题的必要武器。
“序列-序列”模型是如何应用于英&法机器翻译任务的呢?
“序列-序列”模型有两个组件,一个编码器和一个解码器。编码器将源语句转化为简洁的矢量(称为上下文矢量),其中解码器键入上下文矢量中,并利用解码表示执行计算机翻译。
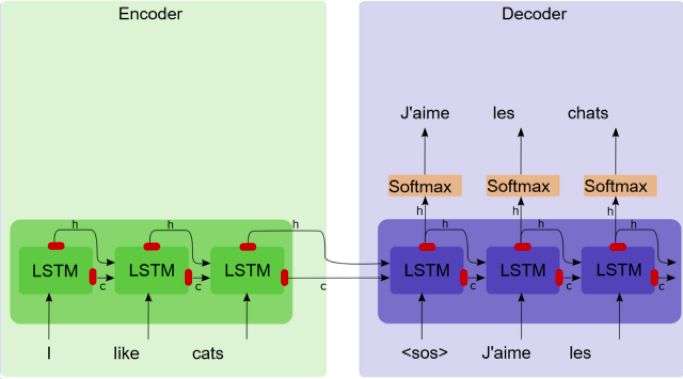 序列到序列模型
序列到序列模型
这种方法存在什么问题吗?
这种方法存在严重瓶颈。上下文矢量需要将给定源语句中的所有信息编码为包含几百个元素的向量。现在,为了融入相关语境,该矢量需要保留以下信息:
· 关于主语、宾语和谓语动词的信息
· 这些字符之间的交互
这个过程任务相当艰巨,特别是对于长句子而言。因此,需要更好的解决方案,这也是Attention机制被用于解决该瓶颈的初衷所在。
Attention注意力机制的实质
如果解码器可以访问过去的所有状态,而不只是上下文矢量,那会怎么样?这正是注意力机制所做的事情。每个解码步骤中,解码器都可以任意查看编码器的特定状态。在这里,我们将讨论巴赫达瑙注意机制(Bahdanau Attention)。下图描述了注意力机制的内部工作原理。
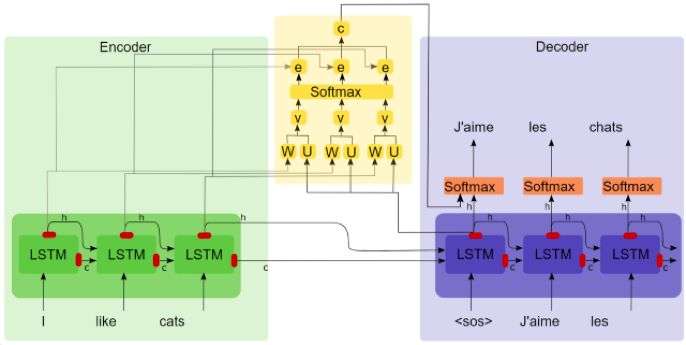 注意机制作用下的序列到序列模型
注意机制作用下的序列到序列模型
从图中不难看出,上下文矢量成为了所有编码器过去状态的加权和。事实上Attention机制从数学公式和代码实现上来看就是加权求和,而研究加权求和中权重的合理性配置正是Attention想要解决的问题。
引入Keras注意力机制
目前的一些注意力机制运作起来会相当麻烦。而Keras注意力机制则采用了更模块化的方法,它在更细的层级上实现注意力机制(即给定解码器RNN/LSTM/GRU的每个解码器步骤)。
使用Attention注意力层
可以将Attention Layer用作任何层,例如,定义一个注意力层:
attn_layer = AttentionLayer(name='attention_layer')([encoder_out,decoder_out])
这里提供了一个简单神经机器翻译(NMT)的示例,演示如何在NMT(nmt.py)中利使用注意层,下面给大家介绍些细节。
利用注意力机制实现NMT
在这里,简要介绍一下利用注意力机制实现NMT的步骤。
首先定义编码器和解码器输入((源/目标字符)。它们都具有一定规格(批量大小、时间步骤、词汇表大小)。
encoder_inputs = Input(batch_shape=(batch_size,en_timesteps, en_vsize), name='encoder_inputs')
decoder_inputs = Input(batch_shape=(batch_size, fr_timesteps - 1, fr_vsize),name='decoder_inputs')
定义编码器(注意return_sequences=True )。
encoder_gru =GRU(hidden_size, return_sequences=True, return_state=True, name='encoder_gru')
encoder_out, encoder_state = encoder_gru(encoder_inputs)
定义解码器(注意return_sequences=True)。
decoder_gru =GRU(hidden_size, return_sequences=True, return_state=True, name='decoder_gru')
decoder_out, decoder_state = decoder_gru(decoder_inputs,initial_state=encoder_state)
定义注意力层。输入进注意力层的是encoder_out (编码器输出序列)和 decoder_out (解码器输出序列)。
attn_layer =AttentionLayer(name='attention_layer')
attn_out, attn_states = attn_layer([encoder_out, decoder_out])
连接 attn_out和 decoder_out并将其作为Softmax层的输入。
decoder_concat_input =Concatenate(axis=-1, name='concat_layer')([decoder_out, attn_out])
定义 TimeDistributed Softmax层,并输入 decoder_concat_input。
dense =Dense(fr_vsize, activation='softmax', name='softmax_layer')
dense_time = TimeDistributed(dense, name='time_distributed_layer')
decoder_pred = dense_time(decoder_concat_input)
定义全模型。
full_model =Model(inputs=[encoder_inputs, decoder_inputs], outputs=decoder_pred)
full_model.compile(optimizer='adam', loss='categorical_crossentropy')
支持注意力机制可视化
事实上,这不仅实现了注意力机制,还提供了将注意力机制可视化的方法。因为对于每个解码步骤这一层都返回两个值:
· 注意力上下文矢量(用作解码器Softmax层的额外输入)
· 注意力权重(注意力机制的Softmax输出)
因此,通过可视化注意力权重,就能充分了解注意力在训练/推理过程中所做的事情。下面详细谈论讨论这个过程。
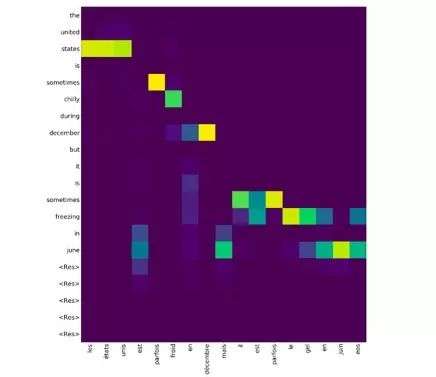
由NMT获得注意力权重推断
NMT推断需要完成以下步骤:
· 获取编码器输出
· 定义一个解码器,执行解码器的单个步骤(因为我们需要提供该步骤的预测为下一步的输入做准备)
· 使用编码器输出作为解码器的初始状态
· 执行解码,直到得到一个无效的单词/输出<EOS>/固定部署
让我们来看看如何利用该模型获得注意力权重。
for i in range(20):
dec_out, attention, dec_state =decoder_model.predict([enc_outs, dec_state, test_fr_onehot_seq])
dec_ind = np.argmax(dec_out,axis=-1)[0, 0]
...
attention_weights.append((dec_ind,attention))
然后,需要将这个注意权重列表传递给 plot_attention_weights(nmt.py)以便获得带有其他参数的注意力热度图。绘图后的输出可能如下所示。
本文使用Keras实现了Attention Layer。对于顺序模型或者其他一些模型来说,注意力机制都非常重要,因为它确实十分百搭。
现有的实现注意力机制的方法要么过于老旧,要么还没有实现模块化。而恰好Keras可以为注意力机制的实现提供了一个不错的解决办法。
看完本文,你不妨赶紧去试试用Keras实现Attention机制是否真如我说的那么简单,说不定你遭遇的paper创新点瓶颈马上就能迎刃而解(Good Luck)。

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
可以看一下这篇文章, 主要讲CV方向的Attention:
An Empirical Study of Spatial Attention Mechanisms in Deep Networks
An Empirical Study of Spatial Attention Mechanisms in Deep Networks可参见我之前写的关于近几年的attention的整理和讨论,里面包含了较全的对主流attention的分类及类比,望指正:
小川Ryan:白话attention(上)zhuanlan.zhihu.com