在SSD中一共有6个用于分类和回归的特征层(feature map),
分别是feat_layers=['block4', 'block7', 'block8', 'block9', 'block10', 'block11'],
m是就是特征层的个数,按理说分母应该是6-1=5,但是这里是5-1=4, 因为作者将第一层S1, 单独拿出来设置了.
k是第几个特征层的意思,注意k的范围是1~m, 也就是1~6.
知道这些就可以开始计算了.
Sk在实际计算中考虑到取整的问题,所有与上式有所区别:
首先你要知道这个公式:
在SSD中一共有6个用于分类和回归的特征层(feature map),
分别是feat_layers=['block4', 'block7', 'block8', 'block9', 'block10', 'block11'],
m是就是特征层的个数,按理说分母应该是6-1=5,但是这里是5-1=4.很神奇。
k是第几个特征层的意思,注意k的范围是1~m, 也就是1~6.
知道这些就可以开始计算了.
Sk在实际计算中考虑到取整的问题,所有与上式有所区别:
所以你将m=5, Smin, Smax=(0.2, 0.9) 就是anchor_size_bounds=[0.20, 0.90],带入之后,
得到S1~S6: 20, 37, 54, 71, 88, 105, 其实就是挨个+17.
此时你还需要将其除以100还原回来,也就是:
0.2, 0.37, 0.54, 0.71, 0.88, 1.05
然后,我们这个是比例, 我们需要得到其在原图上的尺寸,所以需要依次乘以300, 得到:
60, 111, 162, 213, 264, 315.
最后,你会问: 30呢? 这就要说到S1’了,S1’=0.5*S1, 就是0.1, 再乘以300, 就是30.
这样, 我们有七个数, 6个区间段, 也就是6组min_size和max_size. 就可以计算每个特征层的anchor_box 的尺寸了.详细见下片博文.
可以看出作者为了不让我们搞懂他的代码,也是煞费苦心啊…
最后, 既然我们高明白了anchor_size, 这个参数直接决定了当前特征层的box 的大小, 可以看出越靠近输入层, box越小, 越靠近输出层, box越大, 所以 SSD的底层用于检测小目标, 高层用于检测大目标.
------
feature map则是刚才指的Classifier产生的结果,如图(b)和(c) b是大小8*8的feature map,c是大小4*4的feature map,其中每一个小个子都包含多个box,同时每个box对应loc(位置坐标)和conf(每个种类的得分),default box长宽比例默认有四个和六个,四个default box是长宽比为(1:1)、(2:1)、(1:2)、(1:1)这四个,六个则是添加了(1:3)、(3:1)这两个,这时候有小伙伴会问,为什么会有两个(1:1)呢。这时候就要讲下论文中Choosing scales and aspect ratios for default boxes这段内容了。作者认为不同的feature map应该有不同的比例,这是什么意思呢,代表的是default box中这个1在原图中的尺寸是多大的,计算公式如下所示:

公式Sk即代表在300*300输入中的比例,m为当前的feature map是第几层,k代表的是一共有多少层的feature map,Smin和Smax代表的是第一层和最后一层所占的比例,在ssd300中为0.2-0.9。那么S怎么用呢,作者给出的计算方法是,wk = Sk√ar,hk = Sk / √ar,其中ar代表的是之前提到的default box比例,即(1,2,3,1/2,1/3),对于default box中心点的值取值为((i+0.5) / |fk|,(j+0.5)/|fk|),其中i,j代表在feature map中的水平和垂直的第几格,fk代表的是feature map的size。那么重点来了,还记得之前有一个小疑问,为什么default box的size有两个1吗?作者在这有引入了一个Sk' = √Sk*Sk+1,多出来的那个1则是通过使用这个Sk'来计算的,有的小伙伴可能会有疑问,这有了k+1则需要多出来一部分的Sk啊,是的没错,作者的代码中就添加了两层,第一层取0.1,最后一层取1。到这位置,基本上模型和default box是解释清楚了。
我们都知道SSD默认框从6层卷积层输出的特征图中产生,分别为conv4_3、fc7、conv6_2、conv7_2、conv8_2、conv9_2。这6个特征层产生的特征图的大小分别为38*38、19*19、10*10、5*5、3*3、1*1。每个n*n大小的特征图中有n*n个中心点,每个中心点产生k个默认框,六层中每层的每个中心点产生的k分别为4、6、6、6、4、4。所以6层中的每层取一个特征图共产生38*38*4+19*19*6+10*10*6+5*5*6+3*3*4+1*1*4=8732个默认框。
2. 特征图产生min_sizes和max_sizes的计算方式
对ssd产生的默认框的大小计算首先要计算参数min_sizes和max_sizes,这些参数具体在ssd_pascal.py中有计算方法。
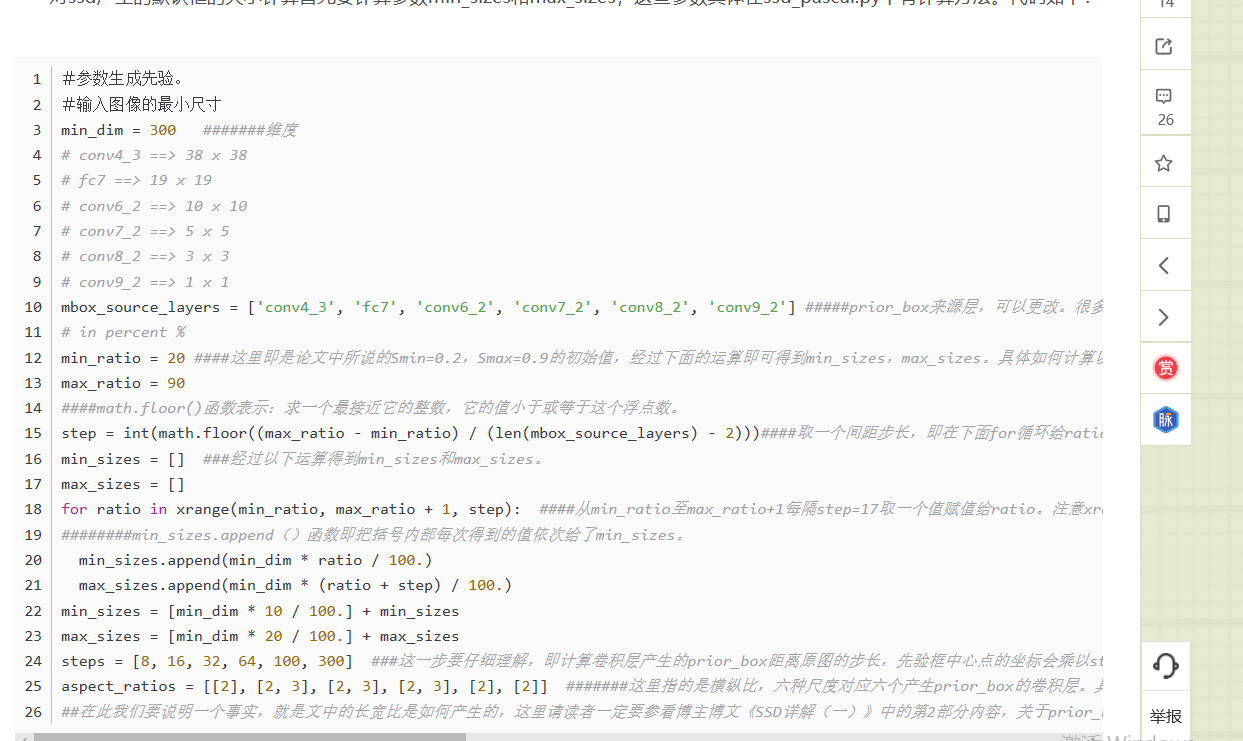
如上代码再结合prior_box_layer.cpp产生先验框,然后再结合bbox_util.cpp对先验框进行匹配。
然后根据代码的计算公式,我们还需要step,注意是step不是steps,两者的作用不一样,在代码中有博主的注释。这里计算后step=(max_ratio-min_ratio)/(len(mbox_source_layers)-2)=(90-20)/(6-2)=17。要说这个step的作用,其实就是取一个间隔,全文看完你就应该明白了。其实这里用了一个复杂的公式说白了就是显得代码高大上一点。
然后就开始计算min_sizes和max_sizes了,首先定义数组min_sizes[]和max_sizes[]用来存放计算结果,没有初始化说明默认为0,。然后计算conv4_3产生的min_sizes和max_sizes。根据代码中的公式计算:min_sizes=[min_dim*10/100]+min_sizes和max_sizes=[min_dim*20/100]+max_sizes得到结果为min_sizes=[300*10/100]+0=30,而max_sizes=[300*20/100]+0=60。这样conv4_3的计算公式被计算分别为30和60。这里为什么要先计算下面两行产生conv4_3的结果而不是使用上面两行公式产生博主也没有搞明白,欢迎指教。
然后根据公式min_sizes.append(min_dim*ratio/100)和公式max_sizes.append(min_dim*(ratio+step)/100)来计算剩下5层的min_size和max_sizes。这里需要用到ratio和step,我们前面讲了step=17,根据代码for ratio in xrange(min_ratio, max_ratio+1, step)(这句的意思我们在代码中有注释,即在min_ratio和max_ratio之间即20-90之间以step=17为间隔产生一组数据赋值给ratio),最终ratio=[20,37,54,71,88]。所以对于剩余5层所产生的min_sizes和max_sizes分别为:
fc7:min_sizes=min_dim*ratio/100=300*20/100=60,max_sizes=min_dim*(ratio+step)/100=300*(20+17)/100=111;
conv6_2:min_sizes=min_dim*ratio/100=300*37/100=111,max_sizes=min_dim*(ratio+step)/100=300*(37+17)/100=162;
conv7_2:min_sizes=min_dim*ratio/100=300*54/100=162,max_sizes=min_dim*(ratio+step)/100=300*(54+17)/100=213;
conv8_2:min_sizes=min_dim*ratio/100=300*71/100=213,max_sizes=min_dim*(ratio+step)/100=300*(71+17)/100=264;
conv9_2:min_sizes=min_dim*ratio/100=300*88/100=213,max_sizes=min_dim*(ratio+step)/100=300*(88+17)/100=315;
所以,最终计算的结果为:
文中代码显示,给出的长宽比为
aspect_ratios = [[2], [2, 3], [2, 3], [2, 3], [2], [2]]
首先我们要知道,我们在前面也讲了,每层的特征图的每个中心点分别会产生4、6、6、6、4、4个默认框,但我们要知道为什么是这几个默认框,这里就和aspect_ratios有关系了。
在SSD中6层卷积层的每个特征图的每个中心点会产生2个不同大小的正方形默认框,另外每设置一个aspect_ratio则会增加两个长方形默认框,而文中代码对于6层的aspect_ratio个数分别为1、2、2、2、1、1,所以这也就是为什么会产生4、6、6、6、4、4个默认框了。例如conv4_3默认生成两个不同大小的正方形默认框,另外又有一个aspect_ratio=2产生了两个长方形默认框,所以总共有4个。再如fc7,默认生成两个正方形默认框,另外又有aspect_ratio=[2,3],所以又生成了4个不同的长方形默认框,共有6个不同大小的默认框。
接着我们再讲这些产生的默认框的大小计算。这里参考paper中的计算公式,我们可以知道,对于产生的正方形的默认框,一大一小共两个,其边长计算公式为:小边长=min_size,而大边长=sqrt(min_size*max_size)。对于产生的长方形默认框,我们需要计算它的高(height)和宽(width),其中,height=1/sqrt(aspect_ratio)*min_size,width=sqrt(aspect_ratio)*min_size,对其高和宽翻转后得到另一个面积相同但宽高相互置换的长方形。如图所示:
conv4_3:小正方形边长=min_size=30,大正方形边长=sqrt(min_size*max_size)=sprt(30*60)=42.42;
长方形的宽=sqrt(aspect_ratio)*min_size=sqrt(2)*30,高=1/sqrt(aspect_ratio)*min_size=30/sqrt(2),宽高比刚好为2:1;
将以上宽高旋转90度产生另一个长方形,宽高比变为1:2。
第1组长方形的宽=sqrt(aspect_ratio)*min_size=sqrt(2)*60,高=1/sqrt(aspect_ratio)*min_size=60/sqrt(2),宽高比刚好为2:1;
将以上宽高旋转90度产生另一个长方形,宽高比变为1:2。
第2组长方形的宽=sqrt(aspect_ratio)*min_size=sqrt(3)*60,高=1/sqrt(aspect_ratio)*min_size=60/sqrt(3),宽高比刚好为3:1;
将以上宽高旋转90度产生另一个长方形,宽高比变为1:3。
第1组长方形的宽=sqrt(aspect_ratio)*min_size=sqrt(2)*111,高=1/sqrt(aspect_ratio)*min_size=111/sqrt(2),宽高比刚好为2:1;
将以上宽高旋转90度产生另一个长方形,宽高比变为1:2。
第2组长方形的宽=sqrt(aspect_ratio)*min_size=sqrt(3)*111,高=1/sqrt(aspect_ratio)*min_size=111/sqrt(3),宽高比刚好为3:1;
将以上宽高旋转90度产生另一个长方形,宽高比变为1:3。
conv7_2、conv8_2、conv9_2我们这里就不再计算了,相信大家看完以上应该明白了如何计算,具体实现的步骤请大家参考脚本prior_box_layer.cpp。这就是我们先验框的计算方式。
另外先验框与ground truth框的匹配通过函数CHECK_GT()函数实现,具体在bbox_util.cpp脚本中实现
然后移除dropout层和fc8层,并新增一系列卷积层,在检测数据集上做finetuing。
其中VGG16中的Conv4_3层将作为用于检测的第一个特征图。conv4_3层特征图大小是 ,但是该层比较靠前,其norm较大,所以在其后面增加了一个L2 Normalization层(参见ParseNet),以保证和后面的检测层差异不是很大,这个和Batch Normalization层不太一样,其仅仅是对每个像素点在channle维度做归一化,而Batch Normalization层是在[batch_size, width, height]三个维度上做归一化。归一化后一般设置一个可训练的放缩变量gamma,使用TF可以这样简单实现:
# l2norm (not bacth norm, spatial normalization)
def l2norm(x, scale, trainable=True, scope="L2Normalization"):
n_channels = x.get_shape().as_list()[-1]
l2_norm = tf.nn.l2_normalize(x, [3], epsilon=1e-12)
with tf.variable_scope(scope):
gamma = tf.get_variable("gamma", shape=[n_channels, ], dtype=tf.float32,
initializer=tf.constant_initializer(scale),
trainable=trainable)
return l2_norm * gamma从后面新增的卷积层中提取Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2作为检测所用的特征图,加上Conv4_3层,共提取了6个特征图,其大小分别是 ,但是不同特征图设置的先验框数目不同(同一个特征图上每个单元设置的先验框是相同的,这里的数目指的是一个单元的先验框数目)。先验框的设置,包括尺度(或者说大小)和长宽比两个方面。对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加:
其中 指的特征图个数,但却是
,因为第一层(Conv4_3层)是单独设置的,
表示先验框大小相对于图片的比例,而
和
表示比例的最小值与最大值,paper里面取0.2和0.9。对于第一个特征图,其先验框的尺度比例一般设置为
,那么尺度为
。对于后面的特征图,先验框尺度按照上面公式线性增加,但是先将尺度比例先扩大100倍,此时增长步长为
,这样各个特征图的
为
,将这些比例除以100,然后再乘以图片大小,可以得到各个特征图的尺度为
,这种计算方式是参考SSD的Caffe源码。综上,可以得到各个特征图的先验框尺度
。对于长宽比,一般选取
,对于特定的长宽比,按如下公式计算先验框的宽度与高度(后面的
均指的是先验框实际尺度,而不是尺度比例):
默认情况下,每个特征图会有一个 且尺度为
的先验框,除此之外,还会设置一个尺度为
且
的先验框,这样每个特征图都设置了两个长宽比为1但大小不同的正方形先验框。注意最后一个特征图需要参考一个虚拟
来计算
。因此,每个特征图一共有
个先验框
,但是在实现时,Conv4_3,Conv10_2和Conv11_2层仅使用4个先验框,它们不使用长宽比为
的先验框。每个单元的先验框的中心点分布在各个单元的中心,即
,其中
为特征图的大小。
得到了特征图之后,需要对特征图进行卷积得到检测结果,图7给出了一个 大小的特征图的检测过程。其中Priorbox是得到先验框,前面已经介绍了生成规则。检测值包含两个部分:类别置信度和边界框位置,各采用一次
卷积来进行完成。令
为该特征图所采用的先验框数目,那么类别置信度需要的卷积核数量为
,而边界框位置需要的卷积核数量为
。由于每个先验框都会预测一个边界框,所以SSD300一共可以预测
个边界框,这是一个相当庞大的数字,所以说SSD本质上是密集采样。
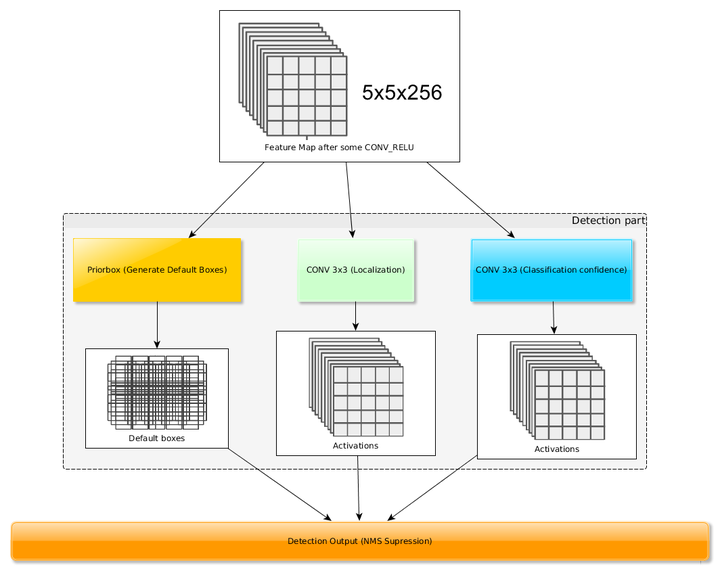 图7 基于卷积得到检测结果
图7 基于卷积得到检测结果
训练过程
