转自:https://blog.csdn.net/xiaoqiaoq0/article/details/107135747/
前言
本文继续整理CPU调度WALT相关内容,主要整理如下内容:
- WALT是什么?
- WALT 计算?
- WALT 计算数据如何使用?
1. WALT是什么?
WALT:Windows-Assist Load Tracing的缩写:
- 从字面意思来看,是以window作为辅助项来跟踪CPU LOAD;
- 实质上是一种计算方法,用数据来表现CPU当前的loading情况,用于后续任务调度、迁移、负载均衡等功能;
1.1 为什么需要WALT ?
对于一项技术的发展,尤其是一种计算方式的引入,一定是伴随着过去的技术不在适用于当前事务发展的需要,或者这项技术可以让人更懒;
1.1.1 PELT的计算方式的不足?
PELT的引进的时候,linux的主流还在于服务器使用,更多关注设备性能的体现,彼时功耗还不是考虑的重点,而随着移动设备的发展,功耗和响应速度成为被人们直接感知到的因素,成为当前技术发展主要考虑的因素:
- 对于当前的移动设备,在界面处理的应用场景,需要尽快响应,否则user会明显感觉到卡顿;
- 对于当前移动设备,功耗更是一个必须面对的因素,手机需要频繁充电,那销量一定好不了;
- 根据用户场景决定task是否heavy的要求,比如显示的内容不同,其task重要程度也不同,即同一个类别的TASK也需要根据具体情况动态改变;
而基于当前PELT的调度情况(衰减的计算思路),更能体现连续的趋势情况,而对于快速的突变性质的情况,不是很友好:
- 对于快速上升和快速下降的情况响应速度较慢,由于衰减的计算过程,所以实际的Loading上升和下降需要一定周期后才能在数据上反馈出来,导致响应速度慢;
- PELT基于其衰减机制,所以对于一个task sleep 一段时间后,则其负载计算减小,但是如果此时该Task为网络传输这种,周期性的需要cpu和freq的能力,则不能快速响应(因为该计算方式更能体现趋向性、平均效果)
1.2 WALT如何处理
根据上述的原因,我们了解到,当前需要在PELT的基础上(保持其好处),实现一种更能适用于当前需求的计算方式:
- 数据上报更加及时;
- 数据直接体现现状;
- 对算力的消耗不会增加(算力);
1.2.1 WALT 处理
我这里总结了WALT所能(需要)做到的效果:
- 继续保持对于所有Task-entity的跟踪 ;
- 在此前usage(load)的基础上,添加对于demand的记录,用于之后预测;
- 每个CPU上runqueue 的整体负载仍为所有Task统计的sum;
- 核心在于计算差异,由之前的衰减的方式变更为划分window的方式:数据采集更能快速体现实际变化(对比与PELT的趋势),如下为Linux官方的一些资料:
- A task’s demand is the maximum of its contribution to the most recently completed window and its average demand over the past N windows.
- WALT “forgets” blocked time entirely:即只统计runable和running time,可以对于Task的实际耗时有更准确的统计,可以通过demand预测;
- CPU busy time - The sum of execution times of all tasks in the most recently completed window;
- WALT “forgets” cpu utilization as soon as tasks are taken off of the runqueue;
1.2.2 应用补充
- task分配前各个CPU和task负载的统计;
- task migration 迁移
- 大小核的分配;
- EAS 分配;
1.3 版本导入
- linux 4.8.2 之后导入(但是在bootlin查看code,最新5.8仍没有对应文件)
- android 4.4之后导入(android kernel 4.9 中是有这部分的)
2. Kernel如何启用WALT
android kernel code中已经集成了这部分内容,不过根据厂商的差异,可能存在没有启用的情况:
- 打开宏测试:
- menuconfig ==》Genernal setup ==》CPU/Task time and stats accounting ==》support window based load tracking
- 图示:
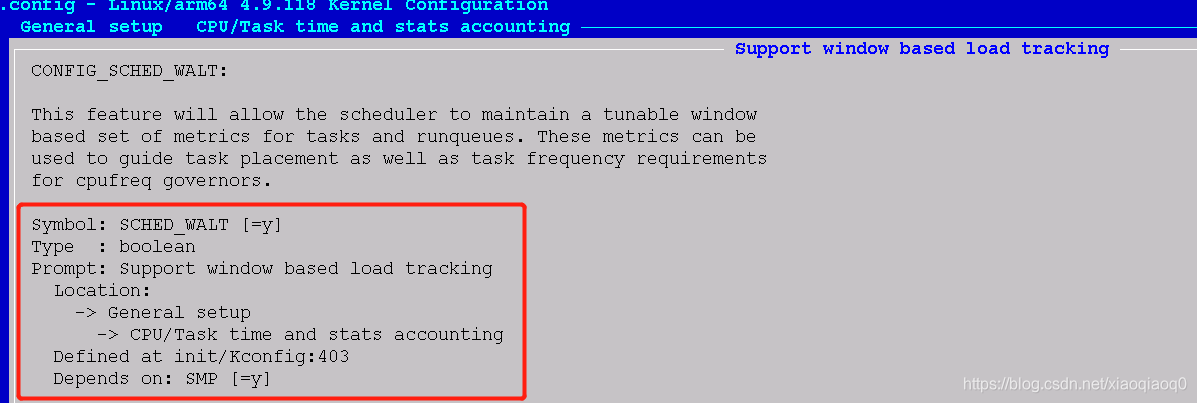
- 直接修改
- kernel/arch/arm64/config/defconfig中添加CONFIG_SCHED_WALT=y
- build image 验证修改是否生效:
demo:/sys/kernel/tracing # zcat /proc/config.gz | grep WALTCONFIG_SCHED_WALT=y
CONFIG_HID_WALTOP=y - 测试
当前只是在ftrace中可以看到确实有统计walt的数据,但是没有实际的应用来确认具体是否有改善或者其他数据(当然Linux的资料中有一些数据,但是并非本地测试);
3. WALT计算
本小节从原理和code 来说明,WALT采用的计算方式:
- windows 是如何划分的?
- 对于Task如何分类,分别做怎样的处理?
- WALT部分数据如何更新?
- WALT更新的数据如何被调度、EAS使用?
3.1 Windows划分
首先来看辅助计算项window是如何划分的?
简单理解,就是将系统自启动开始以一定时间作为一个周期,分别统计不同周期内Task的Loading情况,并将其更新到Runqueue中;
则还有哪些内容需要考虑?
- 一个周期即window设置为多久比较合适?这个根据实际项目不同调试不同的值,目前Kernel中是设置的标准是20ms;
- 具体统计多少个window内的Loading情况?根据实际项目需要调整,目前Kernel中设置为5个window;
所以对于一个Task和window,可能存在如下几种情况:
ps:ms = mark_start(Task开始),ws = window_start(当前window开始), wc = wallclock(当前系统时间)
- Task在这个window内启动,且做统计时仍在这个window内,即Task在一个window内;
- Task在前一个window内启动,做统计时在当前window内,即Task跨过两个window;
- Task在前边某一个window内启动,做统计时在当前window内,即Task跨过多个完整window;
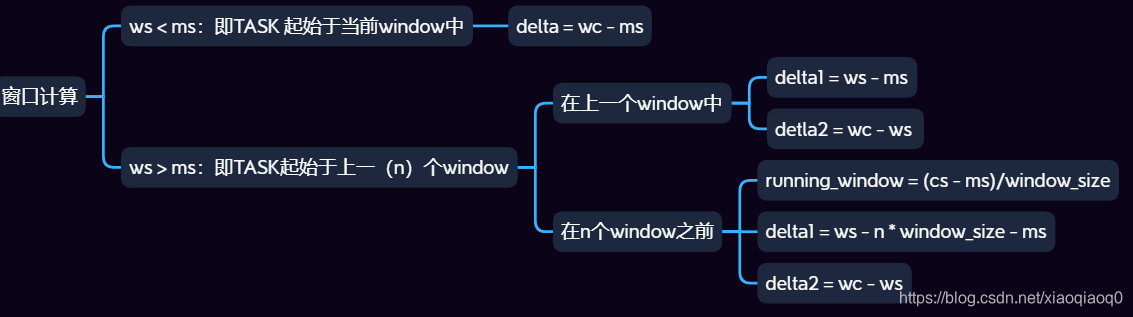
即Task在Window的划分只有上述三种情况,所有的计算都是基于上述划分的;
3.2 Task 分类
可以想到的是,对于不同类别的Task或者不同状态的Task计算公式都是不同的,WALT将Task划分为如下几个类别: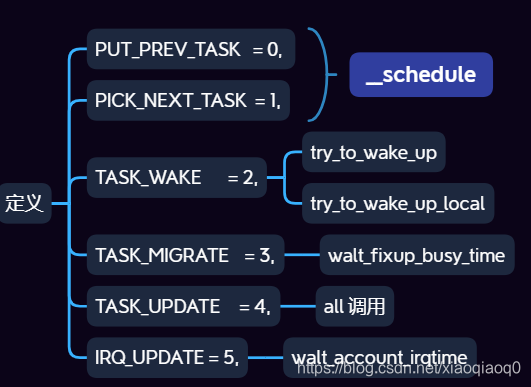
上图中有将各个Task event的调用函数列出来;
3.2.1 更新demand判断
在更新demand时,会首先根据Task event判断此时是否需要更新:
对应function:
static int account_busy_for_task_demand(struct task_struct *p, int event)
{
/* No need to bother updating task demand for exiting tasks
* or the idle task. */
//task 已退出或者为IDLE,则不需要计算
if (exiting_task(p) || is_idle_task(p))
return 0;
/* When a task is waking up it is completing a segment of non-busy
* time. Likewise, if wait time is not treated as busy time, then
* when a task begins to run or is migrated, it is not running and
* is completing a segment of non-busy time. */
// 默认 walt_account_wait_time是1,则只有TASK_WAKE
if (event == TASK_WAKE || (!walt_account_wait_time &&
(event == PICK_NEXT_TASK || event == TASK_MIGRATE)))
return 0;
return 1;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3.2.2 更新CPU busy time判断
在更新CPU busy time时,会首先根据Task event判断此时是否需要更新: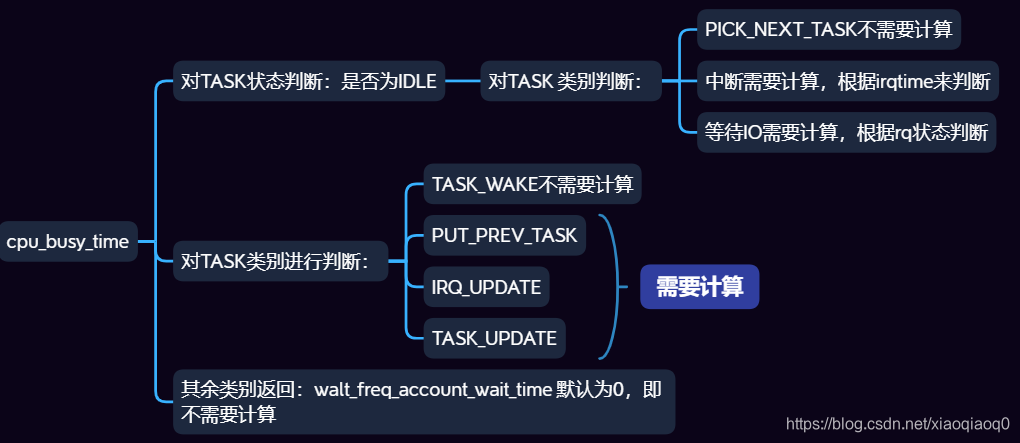
对应function:
static int account_busy_for_cpu_time(struct rq *rq, struct task_struct *p,
u64 irqtime, int event)
{
//是否为idle task or other task?
if (is_idle_task(p)) {
/* TASK_WAKE && TASK_MIGRATE is not possible on idle task! */
// 是schedule 触发的下一个task为idle task
if (event == PICK_NEXT_TASK)
return 0;
/* PUT_PREV_TASK, TASK_UPDATE && IRQ_UPDATE are left */
// 如果是中断或者等待IO的IDLE TASK,是要计算busy time的;
return irqtime || cpu_is_waiting_on_io(rq);
}
//wake 唤醒操作不需要计算;
if (event == TASK_WAKE)
return 0;
//不是IDLE TASK则以下几个类型需要计算
if (event == PUT_PREV_TASK || event == IRQ_UPDATE ||
event == TASK_UPDATE)
return 1;
/* Only TASK_MIGRATE && PICK_NEXT_TASK left */
//默认是0
return walt_freq_account_wait_time;
}
3.3 数据如何更新?(调用逻辑)
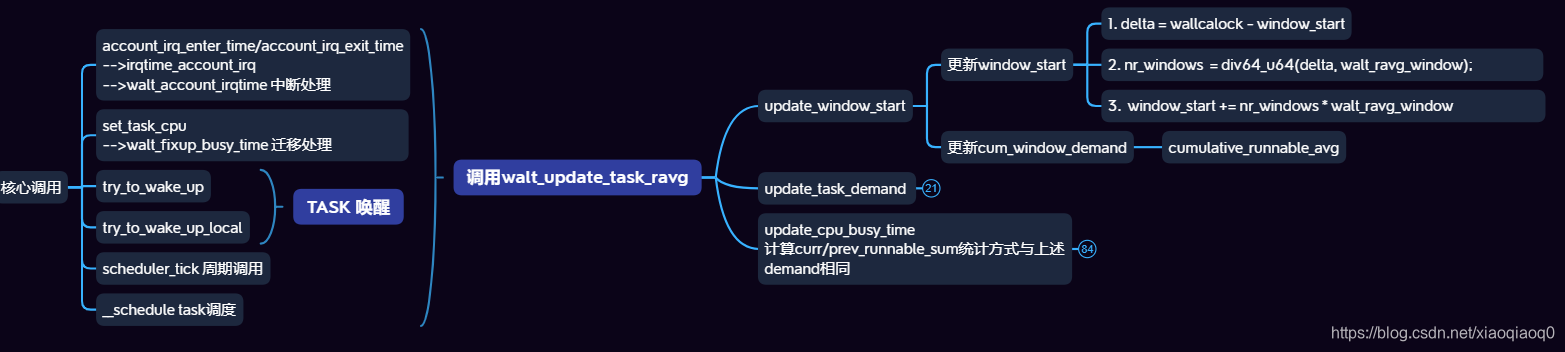
前边两个小结已经介绍了Task在window上统计逻辑和不同Task统计不同数据判断,这里具体来看核心调用逻辑,首先上一张图:
这个图是在xmind导出来的结构图,不清楚是否可以放大查看,这里具体介绍流程:
- 入口函数walt_update_task_ravg
- demand更新函数
- cpu busy time 更新函数
3.3.1 入口函数介绍
对应function:
/* Reflect task activity on its demand and cpu's busy time statistics */
void walt_update_task_ravg(struct task_struct *p, struct rq *rq,
int event, u64 wallclock, u64 irqtime)
{
//判断返回
if (walt_disabled || !rq->window_start)
return;
lockdep_assert_held(&rq->lock);
//更新window_start和cum_window_demand
update_window_start(rq, wallclock);
if (!p->ravg.mark_start)
goto done;
//更新数据:demand和busy_time
update_task_demand(p, rq, event, wallclock);
update_cpu_busy_time(p, rq, event, wallclock, irqtime);
done:
// trace
trace_walt_update_task_ravg(p, rq, event, wallclock, irqtime);
// 更新mark_start
p->ravg.mark_start = wallclock;
}
函数主要做三件事情:
- 更新当前 window start时间为之后数据更新做准备;
- 更新对应task的demand数值,需要注意这里也会对应更新RQ中的数据;
- 更新对应task的cpu busy time占用;
这个函数是WALT计算的主要入口,可以看到调用它的位置有很多,即上图最左侧内容,简单来说就是在中断、唤醒、迁移、调度这些case下都会更新Loading情况,这里不一一详细说明了;
- task awakend
- task start execute
- task stop execute
- task exit
- window rollover
- interrupt
- scheduler_tick
- task migration
- freq change
3.3.2 更新window start
这里主要是在计算之前更新window_start确保rq 窗口起始值准确: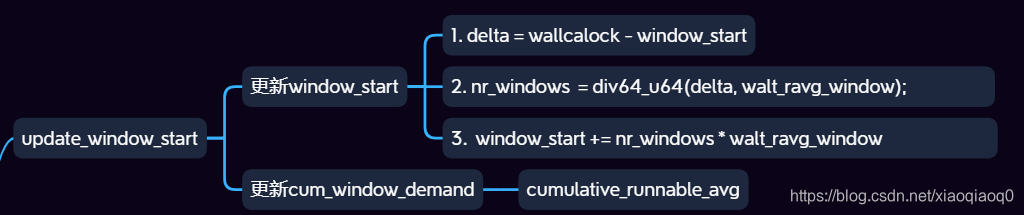
对应function:
static void
update_window_start(struct rq *rq, u64 wallclock)
{
s64 delta;
int nr_windows;
//计算时间
delta = wallclock - rq->window_start;
/* If the MPM global timer is cleared, set delta as 0 to avoid kernel BUG happening */
if (delta < 0) {
delta = 0;
/*
* WARN_ONCE(1,
* "WALT wallclock appears to have gone backwards or reset
");
*/
}
if (delta < walt_ravg_window) // 不足一个window周期,则直接返回;
return;
nr_windows = div64_u64(delta, walt_ravg_window);//计算window数量
rq->window_start += (u64)nr_windows * (u64)walt_ravg_window;//统计window_start时间
rq->cum_window_demand = rq->cumulative_runnable_avg;//实质还得使用cumulative_runnable_avg
}
3.3.3 更新demand
3.3.3.1 demand主要逻辑:
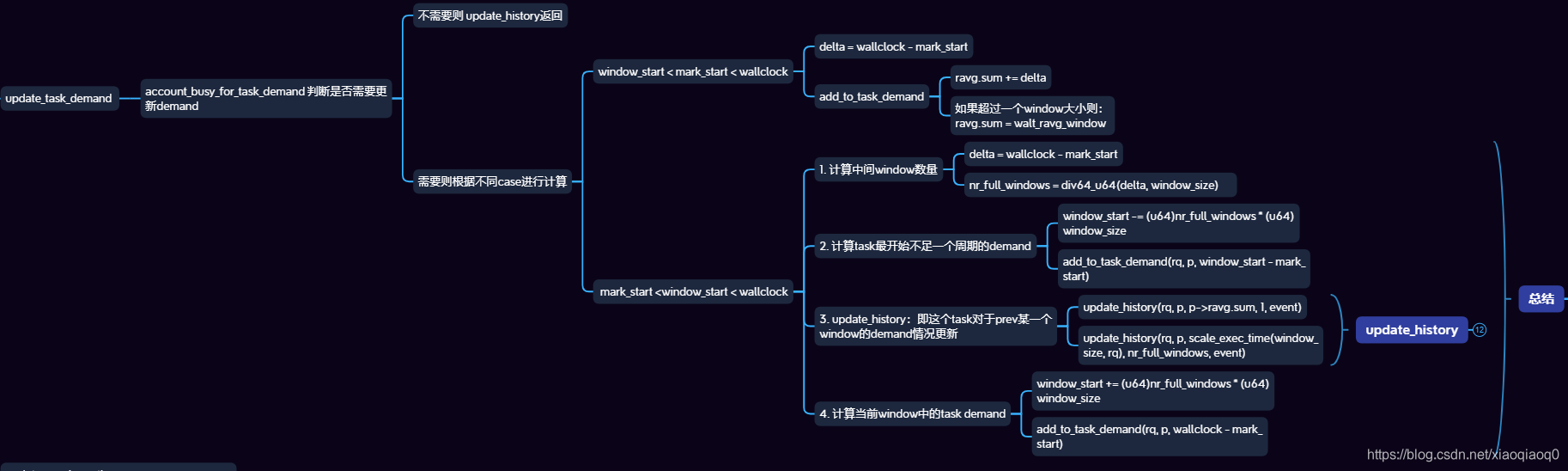
对应function:
/*
* Account cpu demand of task and/or update task's cpu demand history
*
* ms = p->ravg.mark_start;
* wc = wallclock
* ws = rq->window_start
*
* Three possibilities:
*
* a) Task event is contained within one window.
* window_start < mark_start < wallclock
*
* ws ms wc
* | | |
* V V V
* |---------------|
*
* In this case, p->ravg.sum is updated *iff* event is appropriate
* (ex: event == PUT_PREV_TASK)
*
* b) Task event spans two windows.
* mark_start < window_start < wallclock
*
* ms ws wc
* | | |
* V V V
* -----|-------------------
*
* In this case, p->ravg.sum is updated with (ws - ms) *iff* event
* is appropriate, then a new window sample is recorded followed
* by p->ravg.sum being set to (wc - ws) *iff* event is appropriate.
*
* c) Task event spans more than two windows.
*
* ms ws_tmp ws wc
* | | | |
* V V V V
* ---|-------|-------|-------|-------|------
* | |
* |<------ nr_full_windows ------>|
*
* In this case, p->ravg.sum is updated with (ws_tmp - ms) first *iff*
* event is appropriate, window sample of p->ravg.sum is recorded,
* 'nr_full_window' samples of window_size is also recorded *iff*
* event is appropriate and finally p->ravg.sum is set to (wc - ws)
* *iff* event is appropriate.
*
* IMPORTANT : Leave p->ravg.mark_start unchanged, as update_cpu_busy_time()
* depends on it!
*/
static void update_task_demand(struct task_struct *p, struct rq *rq,
int event, u64 wallclock)
{
u64 mark_start = p->ravg.mark_start;//mark start 可以看到是task 的值;
u64 delta, window_start = rq->window_start;//window start是 rq的值;
int new_window, nr_full_windows;
u32 window_size = walt_ravg_window;
//第一个判断条件,ms和ws,即当前task的start实际是否在这个window内;
new_window = mark_start < window_start;
if (!account_busy_for_task_demand(p, event)) {
if (new_window)
/* If the time accounted isn't being accounted as
* busy time, and a new window started, only the
* previous window need be closed out with the
* pre-existing demand. Multiple windows may have
* elapsed, but since empty windows are dropped,
* it is not necessary to account those. */
update_history(rq, p, p->ravg.sum, 1, event);
return;
}
// 如果ms > ws,则是case a:将wc-ms,在此周期内的实际执行时间;
if (!new_window) {
/* The simple case - busy time contained within the existing
* window. */
add_to_task_demand(rq, p, wallclock - mark_start);
return;
}
//超过 1个window的情况
/* Busy time spans at least two windows. Temporarily rewind
* window_start to first window boundary after mark_start. */
//从ms 到 ws的时间,包含多个完整window
delta = window_start - mark_start;
nr_full_windows = div64_u64(delta, window_size);
window_start -= (u64)nr_full_windows * (u64)window_size;
//ws 计算到ws_tmp这里:
/* Process (window_start - mark_start) first */
//先添加最开始半个周期的demand
add_to_task_demand(rq, p, window_start - mark_start);
/* Push new sample(s) into task's demand history */
//更新history
update_history(rq, p, p->ravg.sum, 1, event);
if (nr_full_windows)
update_history(rq, p, scale_exec_time(window_size, rq),
nr_full_windows, event);
/* Roll window_start back to current to process any remainder
* in current window. */
// 还原 window_start
window_start += (u64)nr_full_windows * (u64)window_size;
/* Process (wallclock - window_start) next */
//更新最后的周期,可以看到整体类似于pelt的计算,增加了history的操作;
mark_start = window_start;
add_to_task_demand(rq, p, wallclock - mark_start);
}
//demand计算更新:
static void add_to_task_demand(struct rq *rq, struct task_struct *p,
u64 delta)
{
//demand需要做一次转换,将实际运行时间,转换为CPU 能力比例,一般就是获取CPU 的capcurr 然后除1024;
delta = scale_exec_time(delta, rq);
p->ravg.sum += delta;
//这里有个判断当sum超过window size的时候修改;
if (unlikely(p->ravg.sum > walt_ravg_window))
p->ravg.sum = walt_ravg_window;
}3.3.3.2 update history 逻辑:
update_history 整理:
- 本函数在Task进入一个新的Window的时候调用;
- 更新Task中的demand,根据过往几个Window的情况;
- 同步更新Rq中的Usage,根据当前demand计算值;
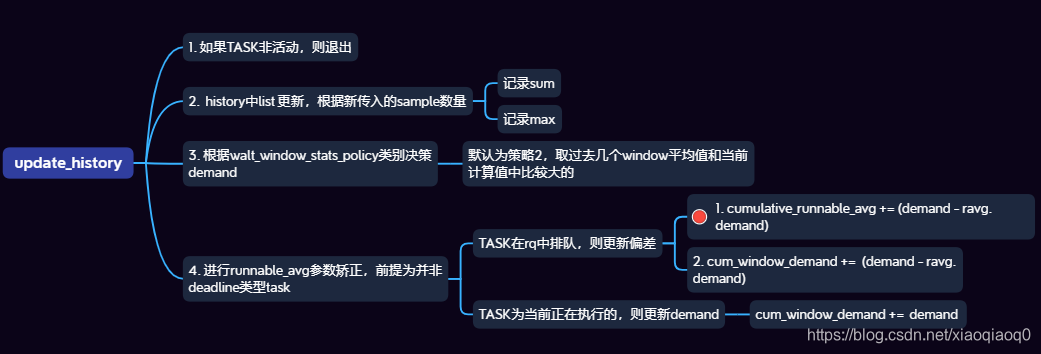
对应function:
/*
* Called when new window is starting for a task, to record cpu usage over
* recently concluded window(s). Normally 'samples' should be 1. It can be > 1
* when, say, a real-time task runs without preemption for several windows at a
* stretch.
*/
static void update_history(struct rq *rq, struct task_struct *p,
u32 runtime, int samples, int event)
{
u32 *hist = &p->ravg.sum_history[0];//对应window 指针链接
int ridx, widx;
u32 max = 0, avg, demand;
u64 sum = 0;
/* Ignore windows where task had no activity */
if (!runtime || is_idle_task(p) || exiting_task(p) || !samples)
goto done;
/* Push new 'runtime' value onto stack */
widx = walt_ravg_hist_size - 1;// history数量最大位置
ridx = widx - samples;//计算链表中需要去除的window数量
//如下两个for循环就是将新增加的window添加到history链表中,并更新sum值和max值;
for (; ridx >= 0; --widx, --ridx) {
hist[widx] = hist[ridx];
sum += hist[widx];
if (hist[widx] > max)
max = hist[widx];
}
for (widx = 0; widx < samples && widx < walt_ravg_hist_size; widx++) {
hist[widx] = runtime;
sum += hist[widx];
if (hist[widx] > max)
max = hist[widx];
}
// Task中sum赋值;
p->ravg.sum = 0;
//demand根据策略不同,从history window中计算,我们默认是policy2 就是 WINDOW_STATS_MAX_RECENT_AVG,在过去平均值和当前值中选择大的那个;
if (walt_window_stats_policy == WINDOW_STATS_RECENT) {
demand = runtime;
} else if (walt_window_stats_policy == WINDOW_STATS_MAX) {
demand = max;
} else {
avg = div64_u64(sum, walt_ravg_hist_size);
if (walt_window_stats_policy == WINDOW_STATS_AVG)
demand = avg;
else
demand = max(avg, runtime);
}
/*
* A throttled deadline sched class task gets dequeued without
* changing p->on_rq. Since the dequeue decrements hmp stats
* avoid decrementing it here again.
*
* When window is rolled over, the cumulative window demand
* is reset to the cumulative runnable average (contribution from
* the tasks on the runqueue). If the current task is dequeued
* already, it's demand is not included in the cumulative runnable
* average. So add the task demand separately to cumulative window
* demand.
*/
//进行runnable_avg参数矫正,前提为并非deadline类型task
if (!task_has_dl_policy(p) || !p->dl.dl_throttled) {
if (task_on_rq_queued(p))//在runqueue中排队,但是没有实际执行
fixup_cumulative_runnable_avg(rq, p, demand);//在rq中添加当前demand和task中记录demand的差值,更新到cumulative_runnable_avg
else if (rq->curr == p)//当前执行的就是这个Task
fixup_cum_window_demand(rq, demand);//在rq中添加demand
}
//最后将计算出来的demand更新到Task中;
p->ravg.demand = demand;
done:
trace_walt_update_history(rq, p, runtime, samples, event);
return;
}
//更新cumulative_runnable_avg的值;
static void
fixup_cumulative_runnable_avg