转自:https://blog.csdn.net/yiyeguzhou100/article/details/78085857
mlock实现原理及应用
1 mlock简介
1) mlock(memory locking)是内核实现锁定内存的一种机制,用来将进程使用的部分或
全部虚拟内存锁定到物理内存。
2) mlock机制主要有以下功能:
a)被锁定的物理内存在被解锁或进程退出前,不会被页回收流程处理。
b)被锁定的物理内存,不会被交换到swap设备。
c)进程执行mlock操作时,内核会立刻分配物理内存(注意COW的情况)。
2 mlock原理
1) 每个进程都拥有一段连续的虚拟内存,内核并不是以整个虚拟内存为管理单位,而是将
整个虚拟内存划分为若干个虚拟内存区域。
2) 内核中使用vm_area_struct数据结构来管理虚拟内存区域,简称vma。vma管理虚拟内
存的方式如下图所示:
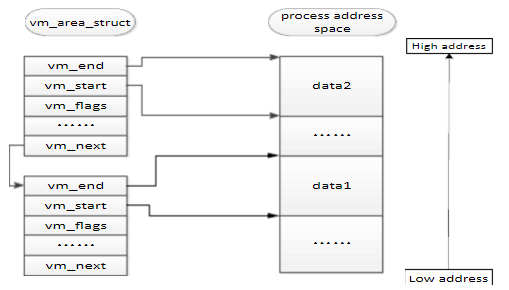
3) 每一个vma代表一个已映射的、连续的且属性相同(如可读/写)的虚拟内存区域。内核采用链表和
AVL树形式管理vma,其中链表用于遍历,AVL树用来查找(VMA的两种数据结构组织形式,就像pid的三种组织形式一样)。
4) mlock操作会给相应的vma的vm_flags置一个VM_LOCKED标记,而这个标记则会影响到物理内存回收和交换。
#define VM_LOCKED 0x00002000
5) Linux分配内存到page且只能按页锁定内存,所以指定的地址会被round down到下一个page的边界。
6) 当mlock锁定的虚拟内存区域跟现有vma管理的虚拟内存区域并不完全重合时,由于同一个vma的内存属性要求一致,而VM_LOCKED标记也是其属性,因此会导致现有的vma被合并或分割,如下图所示:
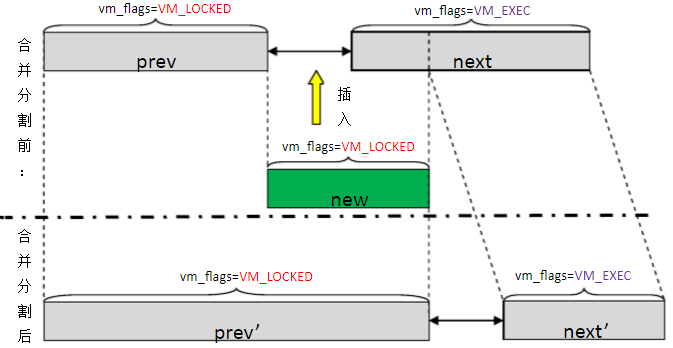
说明:
a) prev与next是已受链表管理的vma结构,new是将要新加入链表的vma。
b) 当new加入时,如果new的起始地址与prev的结束地址相同,且new属性与prev属性均为VM_LOCKED
,则将prev和new合并成prev’。
c) 如果new的结束地址与next的起始地址有重合,但next属性是VM_EXEC,则next被分割成两部分,一部分加入
prev’,另一部分变成next’。
7) 操作系统通过LRU算法来管理Linux进程的虚拟内存,LRU算法主要通过两个页面标志
符(PG_active和 PG_referenced)来标识某个页面的活跃程度,
从而决定页面如何在两个链表(active_list和inactive_list)之间进行移动。
8) 内核函数vmscan会遍历扫描active_list和inactive_list链表来回收页面。
9) 内核在LRU算法中新增了一个unevictable_list链表,将不可回收的页面都放在unevictable_list
中,mlock的页面就被放在unevictable_list中,同时给该页置一个PG_mlocked标记。
注:除了mlock的页,ramdisk或ramfs页以及共享内存映射的页也被放入unevictable_list中。
10) 解锁并不立刻将解锁的页回收,而是将解锁的页放回active_list或inactive_list链表,然后交由页回收流程处理,所以mlock的页不会被页回收流程处理。
11) 由于线程共享进程资源,所以线程的vma将继承VM_LOCKED标记。但fork后的子进程的vma并不继承VM_LOCKED
标记,以及调用exec执行其它程序时,不继承VM_LOCKED标记。
3 mlock函数
mlock机制通过提供四个函数来使用,如下所示:
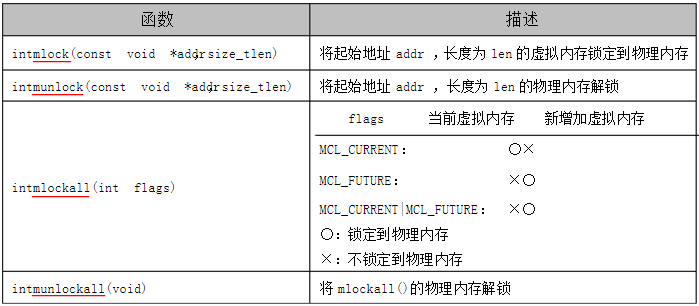
注:
1) 上述函数只能由root用户执行。
2) mlock操作不可叠加,多次调用mlock的一段内存会被一次unlock解锁。
3) 锁定进程所有映射到地址空间的数据包括:代码、数据、栈片段分页,共享库、用户空间内核数据、
共享内存以及内存映射的文件
4 mlock应用
1) mlock机制在虚拟化中的应用
libvirt已提供对mlock支持,可以通过在Guest的xml文件中添加如下内容来开启qemu-kvm进程的mlock
机制
<memoryBacking>
<locked/>
</memoryBacking>
注:默认情况下qemu-kvm进程中的mlock选项是关闭的。
2) mlock机制在实时环境下的应用
mlocked 访问内存产生page fault次数 访问内存时间开销
on 1 低
off >1 高
说明:
a) 采用mlock机制时,仅在虚拟内存和物理内存建立映射关系时产生一次page fault。
b) 未采用mlock机制时,每当访问不同的虚拟内存单元时,就会产生一次page fault。
3) mlock机制在多线程环境下的应用
mlocked 线程栈空间映射物理内存大小 映射物理内存时间开销
on 10MB 高
off 1MB 低
注:
a) 假设线程整个栈空间大小10MB,其中1MB空间已使用。
b) 假设10MB虚拟内存和物理内存建立映射关系耗时1ms,1MB虚拟内存和物理内存建立映射关系
耗时0.1ms。
说明:
当进程涉及多线程操作时:
a) 采用mlock机制时,线程整个栈空间10MB会被映射到物理内存,若一个进程中有2000
个线程,则线程栈空间和物理内存建立映射关系共耗时2000ms。
b) 未采用mlock机制时,线程栈空间已使用的1MB会被映射到物理内存,若一个进程中有2000
个线程,则线程栈空间和物理内存建立映射关系共耗时200ms。