1. Redis数据结构以及应用场景
1.1. Memcache VS Redis
1.1.1. 选Memcache理由
- 系统业务以KV的缓存为主,数据量、并发业务量大,memcache较为合适
- memcache将所有数据存储在物理内存中。Redis则有自己的VM机制,当数据超量时,会引发swap,影响计算机服务器性能
- memchache使用多线程的模式(主线程监听,work子线程工作),而Redis使用单线程,难以充分利用目前的多核CPU,我要求的是快快快,压榨光每一个资源的性能
1.1.2. 选Redis的理由
- 虽然Redis在数据的持久化方面并不那么完美,但是可以在系统奔溃发生意外时,提供一层保障
- Redis天然高可用,官方提供了sentinel集群管理工具,释放了我们大量的工作内容
- Redis能存储内容较Memcache的1M要大多了
- Redis代码质量比Memcache好多了
- 系统不仅仅只用到KV,我们需要用到Redis丰富的数据结构以及相关功能函数,Memcache不适合我的系统
1.2. Redis数据结构
1.2.1. String
1.2.1.1. 概念
- key value都是String的map
1.2.1.2. 分布式锁
//设置锁字符串键,若存在则设置失败
SETNX("couponcode","lock") == 1 //成功获取锁
SETNX(lockKey,'lock')==0//有人占用资源获取锁失败
业务处理完毕释放分布式锁
DEL(lockKey);
//设置锁字符串键的失效时间,防止宕机,系统运行意外,导致无法释放锁
PEXPIRE(lockKey, lockMilliSeconds)
1.2.1.3. 字符串键-计数器
通过字符串这两个API即可实现:
INCR key //INCR readcount::{帖子ID} 每阅读一次
GET key //GET readcount::{帖子ID} 获取阅读量

实战情况通常取部分数据到内存再进行分配
1.2.2. Hash键
1.2.2.1. 概念
类似HashMap<String,HashMap<String,String>> h = new HashMap<>();
1.2.2.2. hash键存在的意义何在?
- Hash键可以将信息凝聚在一起,而不是直接分散存储在整个Redis中,这不仅方便了数据管理,还可以尽量避免一定的误操作
- 避免键名冲突
- 减少内存占用
1.2.2.3. 不合适使用Hash键的情况
- 过期功能的使用,过期功能只能使用在key上
- 二进制操作命令,如:SETBIT、GETBIT、BITOP
- 需要考虑数据量分布的问题
1.2.3. 列表(List)键
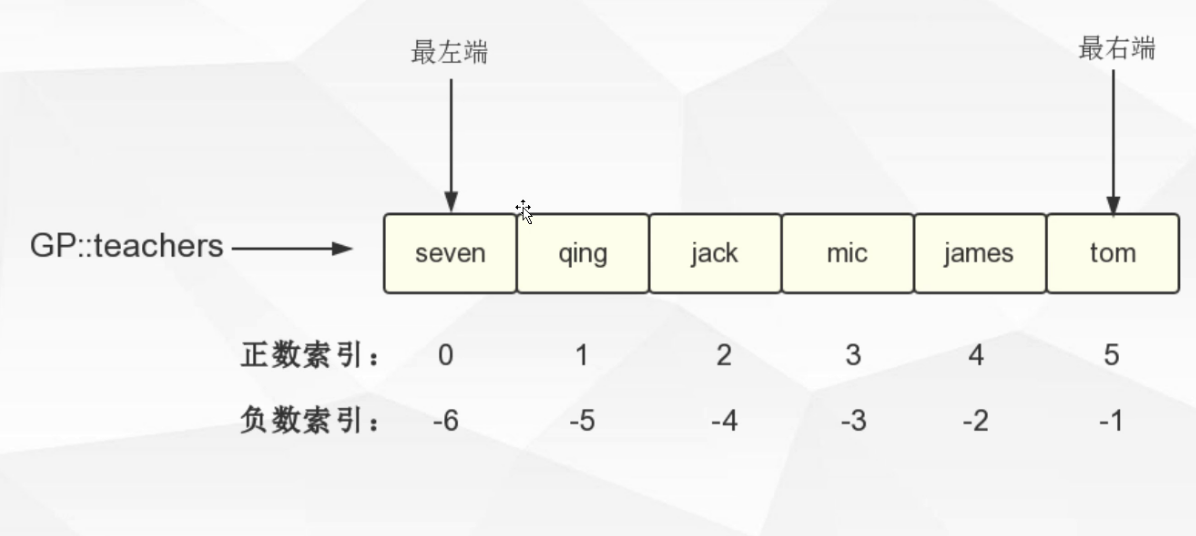
LPUSH key.value [value ...]
RPUSH key value [value ...]
LPOP key
RPOP key
LRANGE key start stop 例如LRANGE key 0 -1 表示拿取所有数据
1.2.3.1. 基于列表(List)键,实现阻塞消息队列
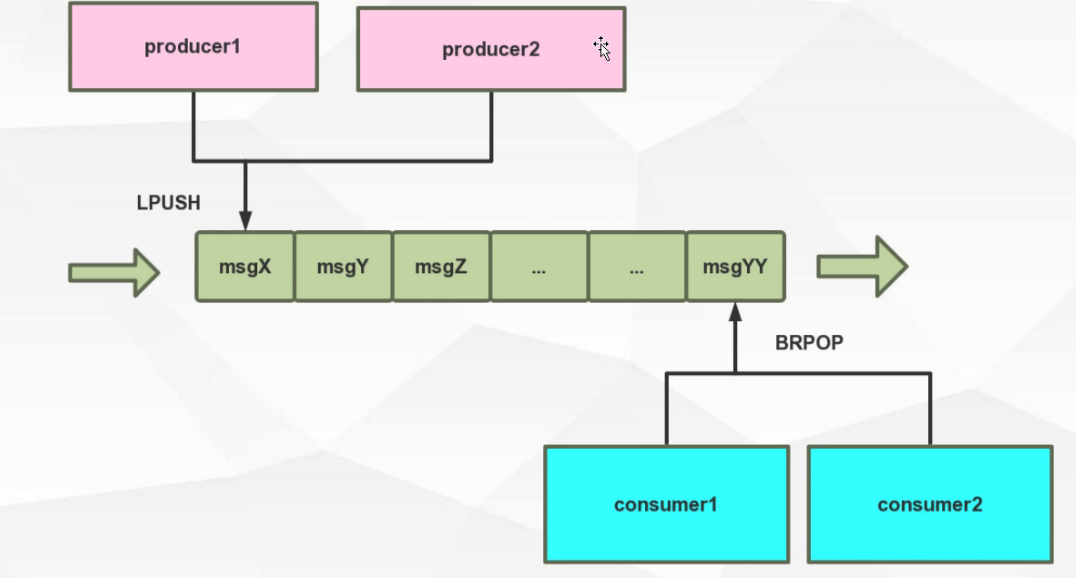
// 阻塞的取队列
BLPOP key [key ...] timeout
BRPOP key [key...] timeout

1.2.4. 集合(set)键
1.2.4.1. 基本操作
SADD key member [member ...] 添加
SREM key member [member ...] 删除
SMEMBERS key 列出所有元素
SCARD key 元素个数
SISMEMBER key member 判断元素是否在集合里 0-不存在 1-存在
SRANDMEMBER key [count] 随机弹出count个元素,默认1,保留元素在集合中
SPOP key [count] 随机弹出count个元素,并且从集合中删除
1.2.4.2. 实现抽奖

1.2.4.3. 实现点赞、签到、like等功能
点赞 --> SADD like::8001 1001
取消点赞 --> SREM like::8001 1001
检查用户是否点过赞 --> SISMEMBER like::8001 1001
获取点赞的用户列表 --> SMEMBERS like::8001
获取点赞用户数 --> SCARD like::8001
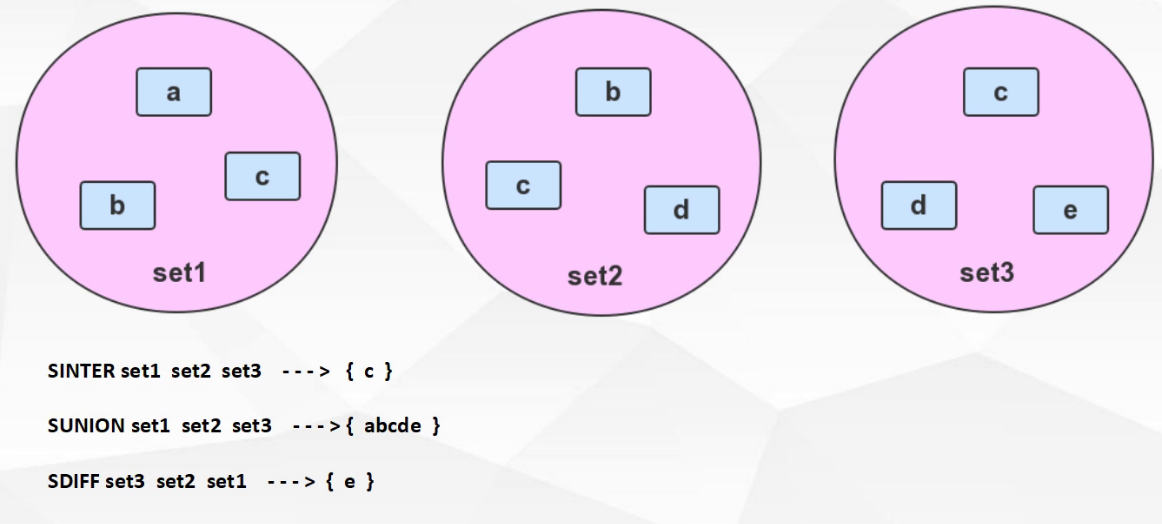
1.2.4.4. 集合运算操作
SINTER key [key ...] SINTERSTORE destination key [key ...] //交集运算 保存到目的key集中
SUNION key [key ...] SUNIONSTORE destination key [key ...] //并集计算
//差集以第一个集合为准,对后方集合进行差集运行
SDIFF key [key ...] SDIFFSTORE destination key [key ...] //差集运算
1.2.4.5. 基于集合键,实现关注模型(可能认识的人)

1.2.4.6. 基于集合运算,实现电商商品筛选
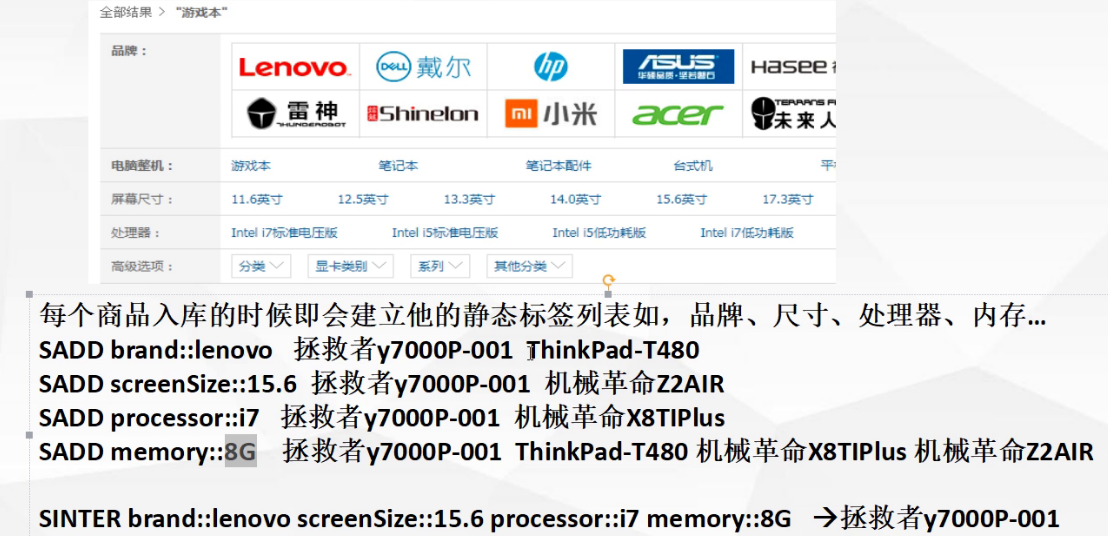
1.2.4.7. 实现与支付系统间对账
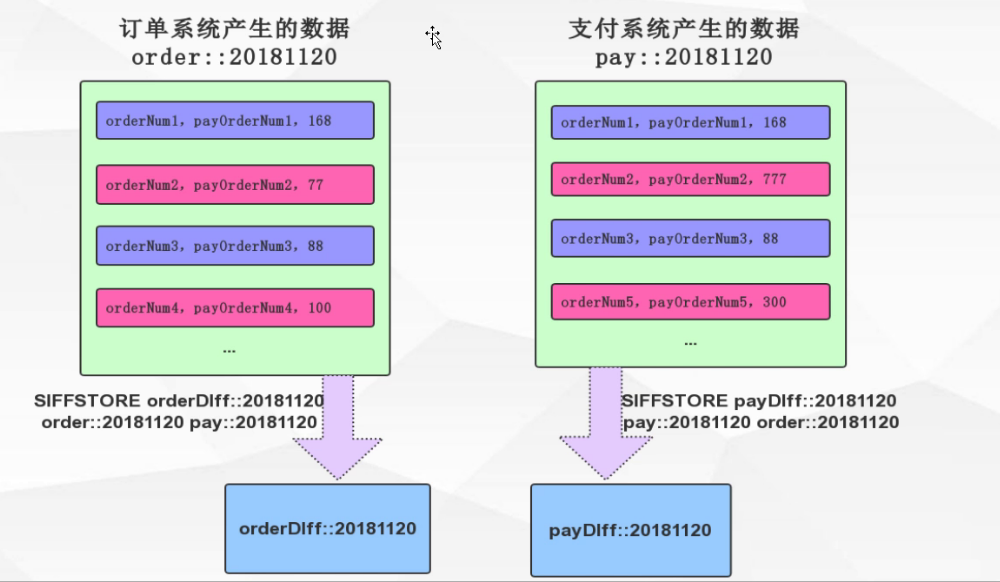
1.2.5. 有序集合(Zset)键


ZADD key score element [[score element][score element]...] 添加
ZREM key element [element...] 删除
ZSCORE key element 查看分值
ZINCRBY key increment element
ZCARD key
ZRANGE key start stop [WITHSCORES] //取出范围内元素和值 0 -1 全部
ZREVRANGE key start stop [WITHSCORES] //反向范围
集合运算操作
ZUNIONSTORE destkey numkeys key [key...]
ZINTERSTORE destkey numkeys key [key...]
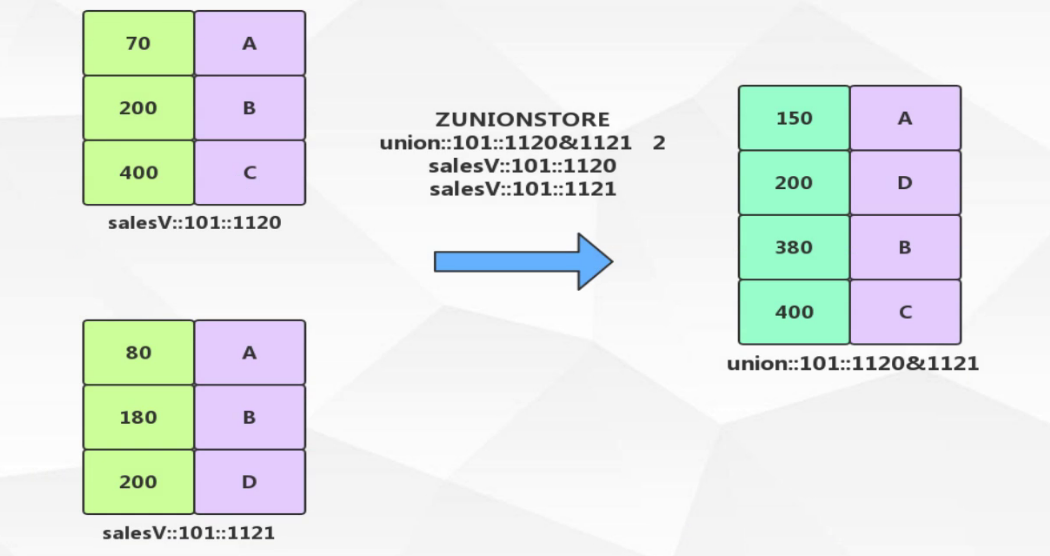
1.2.5.1. ZUNIONSTORE 并集运算
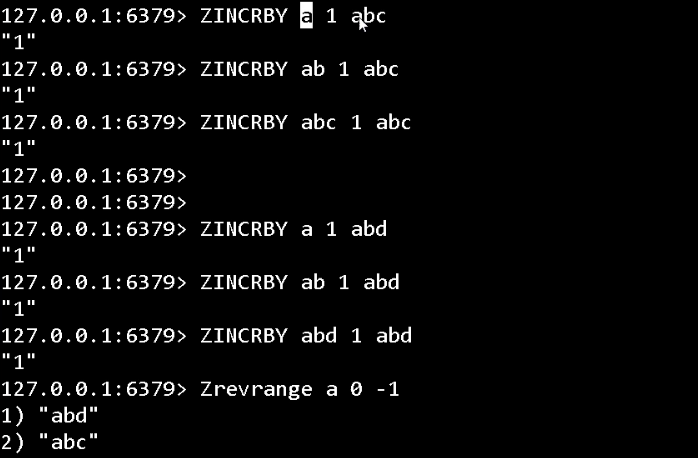
1.2.5.2. 基于有序集合键,实现自动补齐功能
1.2.5.3. 基于有序集合(Zset)键,实现单日排行榜
