什么是Spark
-
大数据计算框架
-
离线批处理
-
大数据体系架构图(Spark)
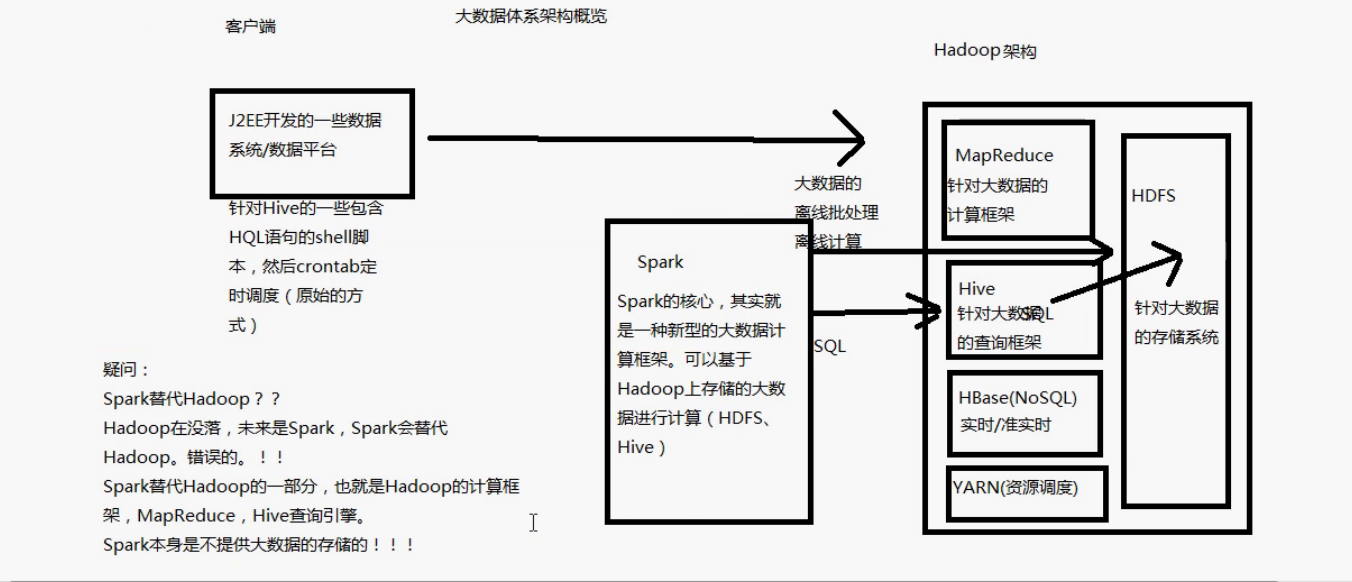
-
Spark包含了大数据领域常见的各种计算框架:比如Spark Core用于离线计算,Spark SQL用于交互式查询,Spark Streaming用于实时流式计算,Spark MLib用于机器学习,Spark GraphX用于图计算
-
Spark主要用于大数据的计算,而Hadoop以后主要用于大数据的存储(比如HDFS、Hive、HBase)等,,以及资源调度(Yarn)
-
Spark+hadoop的组合是大数据领域最热门的组合,也是最有前景的组合
-
Spark与MapReduce计算过程,Spark基于内存进行计算,所以速度更快
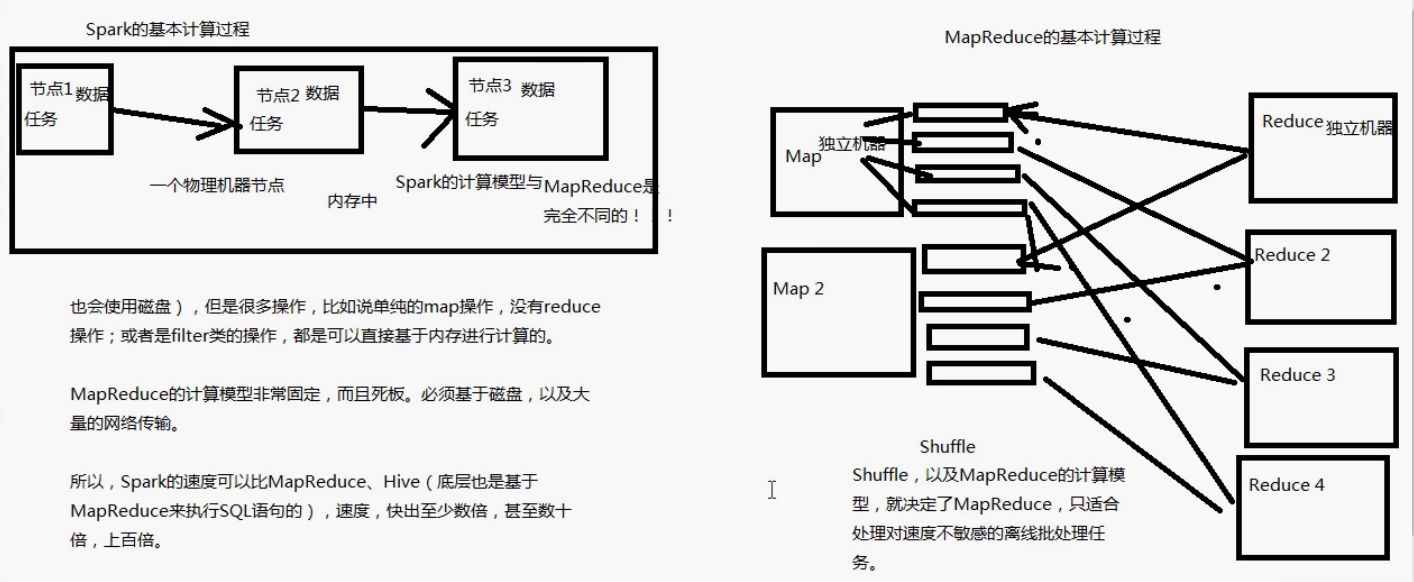
-
Spark整体架构图
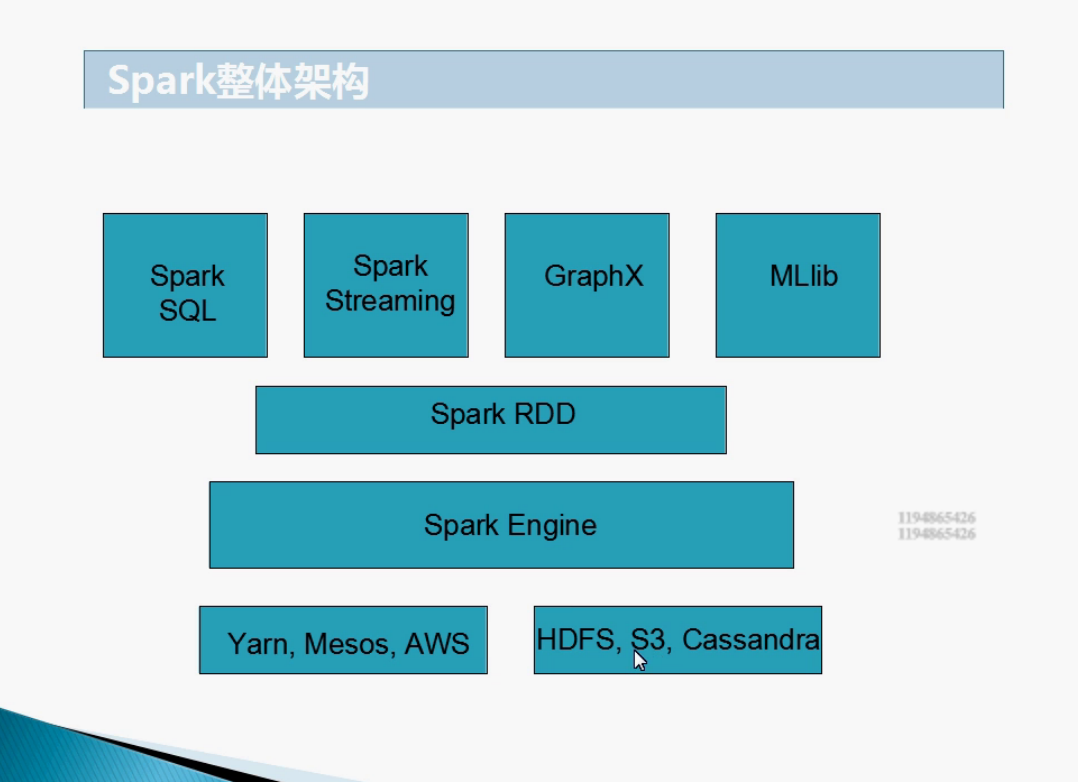
Spark的特点
- 速度快:基于内存进行计算(当然也有部分计算基于磁盘,比如shuffle)
- 容易上手开发:Spark的基于RDD的计算模型,比Hadoop的基于Map-Reduce的计算模型要更加易于理解,更加易于上手开发,实现各种复杂功能,比如二次排序,topn等复杂操作时,更加便捷
- 超强的通用性:Spark提供了多种计算组件
- 集成Hadoop:Spark与Hadoop进行了高度的继承,完成double win
- 极高的活跃度
Hive架构
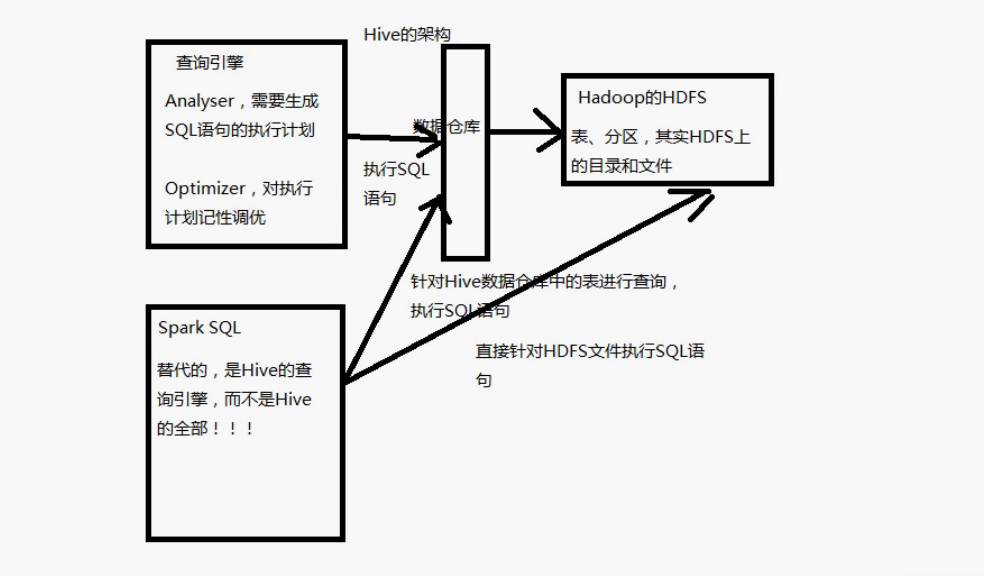
- Spark SQL实际上不能完全替代Hive,以为Hive是一种基于HDFS的数据仓库,并且提供了基于SQL模型的,针对存储了大数据的数据仓库,进行分布式交互查询的查询引擎
- 严格来讲,Spark SQL能够替代的,是Hive的查询引擎,而不是Hive本身,Spark本身是不提供存储的,自然不能替代Hive作为数据仓库的这个功能
- Hive的查询引擎,基于MapReduce,必须经过shuffle过程走磁盘,因此速度是非常缓慢的。Spark基于内存,因此速度达到Hive查询引擎的数倍以上
- Spark SQL相较Hive的另一个特点,就是支持大量不同的数据源,包括Hive、json、parquet、jdbc等等。此外,Spark SQL由于身处Spark技术堆栈内,也是基于RDD来工作,因此可以与Spark其他组件无缝整合使用。比如Spark SQL支持可以直接针对hdfs文件执行sql语句
Storm与Spark对比
