Hadoop 开源分布式计算平台,前身是:Apache Nutch(爬虫),Lucene(中文搜索引擎)子项目之一。
以Hadoop分布式计算文件系统(Hadoop Distributed File System HDFS)和MapReduce(Google MapReduce的开源实现)为核心 的Hadoop基础架构。
HDFS的高容错性、搞伸缩性等优点可以将Hadoop部署在廉价版的硬件上,形成分布式系统;
MapReduce分布式编程模型,利用这种模型软件开发者可以轻松地编写出分布式并行程序。
优势:
1、高可靠性:按位储存和处理数据的能力指的信赖。
2、高扩展性:在可用的计算机集簇间分配数据完成计算任务,这些集簇可以扩展到数以千计的节点中。
3、高效性:能够在节点之间动态的移动数据,已保证各个节点的动态平衡,因此处理速度非常快。
4、高容错性:Hadoop能够自动保存数据的多分副本,并且能够自动将失败的任务重新分配。
Hadoop项目极其结构
hadoop核心是MapReduce(编程模型)和HDFS(计算系统)
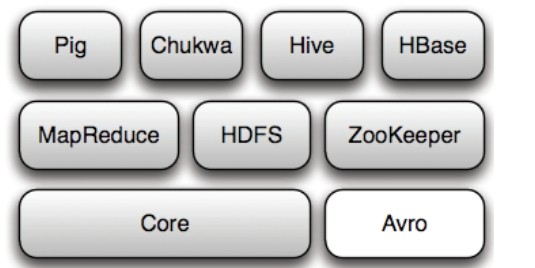
1、Hadoop Common:是Hadoop为其它子项目提供支持的常用工具,主要包括FileSystem、PRC和串行化库。
2、Avro:是数据序列化的系统,将逐步取代Hadoop原有的IPC机制。
3、MapReduce:是一种编程模型,并行计算框架,用于大规模数据集的并行运算。
4、HDFS:是分布式计算系统,具有高容错性
HDFS设计目标:
4.1:检测和快速恢复硬件故障是HDFS的核心目标。
4.2:流式的数据访问;重视数据的吞吐量,不是数据访问的反应速度。
4.3:简化一致性模型;
4.4:通信协议;所有的通信协议都是建立在TCP/IP协议之上的。
5、Chukwa:是开源的数据收集系统,用于监控和分析大型分布式系统的数据,在MapReduce和HDFS之上搭建的,通过HDFS来储存数据并依赖MR任务处理数据。
6、Hive:数据仓库工具,由Facebook贡献。建立在Hadoop基础上的数据仓库,提供对Hadoop文件中的数据集进行数据整理、特殊查询和分析储存的工具。
7、HBase:开源的分布式、面向列的数据库。7.1:HBase是一个适合于非结构化数据储存的数据库;7.2:HBase是基于列而不是基于行的模式。
8、Pig:大数据分析和评估平台。底层由一个编译器组成,语言层由Pig Latin的正文型语言组成。
9、Zookeeper:是一个为分布式应用所设计的开源协调服务。主要为用户提供同步、配置管理、分组和命名等服务。由Java编写、但支持J和C两种语言。
----------------------
Ambari:Hadoop管理工具。Apache Ambari是对Hadoop进行监控、管理和生命周期管理的基于网页的开源项目。
Sqoop:于在HADOOP与传统的数据库间进行数据的传递。利用Sqoop将数据从数据库导入到HDFS。
Hadoop体系结构
1、HDFS讲解
HDFS和MapReduce是Hadoop两大核心,而整个Hadoop的体系结构主要是通过HDFS来实现分布式储存的底层支持的。
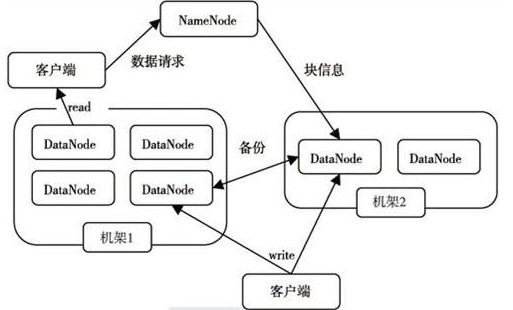
HDFS采用 主从(Master/Slave)结构模型,一个HDFS由一个NameNode和若干个DataNode组成,NameNode作为主服务器来管理文件系统的命名空间和客户端对文件的访问操作,
集群中的DataNode管理储存数据。允许以文件的形式来储存数据,从内部来看 文件被分成若干个数据块存放在一组DataNode上,DataNode处理文件的读写请求,NameNode处理例如:
打开、关闭、重命名文件或目录等也负责数据块到具体DataNode的映射。
NameNode是所有HDFS元数据的管理者,用户需要保存的数据不会经过NameNode,而是直接流向存储数据dataNode。
体系结构图:
2、MapReduce介绍
基于MapReduce可以将任务分发到由上千台商用机器组成的集群上,并以一种可靠性容错的方式并行处理大数据集,实现Hadoop的并行任务处理功能。
MapReduce是由一个单独运行在主节点的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。
主节点负责调度构成一个作业任务,这些任务分配在不同的从节点上,主节点监控他们的执行情况,并且重新执行之前失败的任务。
从节点负责由主节点指派的任务,当一个Job被提交时,JobTracker接收到提交作业和配置信息后,就会将配置信息分发给从节点,并同时监控。
总结:MapReduce和HDFS共同组成了Hadoop分布式系统的体系结构,HDFS在集群上实现了分布式文件系统,MapReduce实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了对文件操作和储存等的支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作并收集结果。二者相互作用完成了Hadoop分布式集群的主要任务。